高校生向け:今日からはじめるCGLA(non-CGRA)
温暖化抑止に貢献できるものづくりと新しいコンピュータ作りに興味ある高校生へ
音声合成マクロ付きpptm(合成mp4はyoutubeチャンネル)の元ノートを見たい人は以下
IMAX3: Amazing Dataflow-Centric CGLA(non-CGRA)
これは,円安になっても,輸出できるコンピュータがない国に住んでいる高校生へのメッセージ。メーカーに就職しましょうではなく,メーカーの肩代りをしましょうです。参考文献。これからは,燃費の悪いノイマン型コンピュータを輸入してプログラムの仕方を勉強して専門家のふりをするだけではなく,温暖化抑止に直接効果がある省エネコンピュータを自ら作ることのできる知恵が大切です。コンピュータの世界では,省エネと生産性を両立できないので,別の何かを諦める相当の知恵が必要です。そして,CGRAという新しい計算の仕組みでは,老舗メーカーは何をあきらめるかを決められないので,老舗メーカーは手も足も出ません。G○○○○○やA○○○○のように,必要なものは自分で決めて作る。周りが使い始めたら教えてもらおうとか,未来の**コンピュータが全て解決するとか思考停止するのはやめましょう。ところで,CGRAには大きく2種類あります。FPGAを拡張したものと,CPUを拡張したものです。この記事は,後者を取り扱います。なぜって? そりゃ,前者はコンパイルに長時間かかるので,役に立たないからです。そうそう,うちの汎用CGRA(IMAX2)と,ブロックチェインCGRA(U2BCA)は,すでに公開し,各方面からダウンロードされているし,来訪もあります。CGRAは,まだ研究レベルだし,同業者がやらないからまだ安心と,いつまでも寝ている技術者は,追い付くのに10年かかるので,もう手遅れです。ところで,この記事は,かなり古いので,新しいの見たい人は,頭のYoutubeチャンネルか,pptmをみてください.2022/01/01(なかしま@ならせんたんだい)

うちのCGRAは,普通の人が聞いたことがあるものとは,全く違います。様々な機能が高密度実装されていて,かつ,コンパイル速度が速いので,JITコンパイルも可能です。
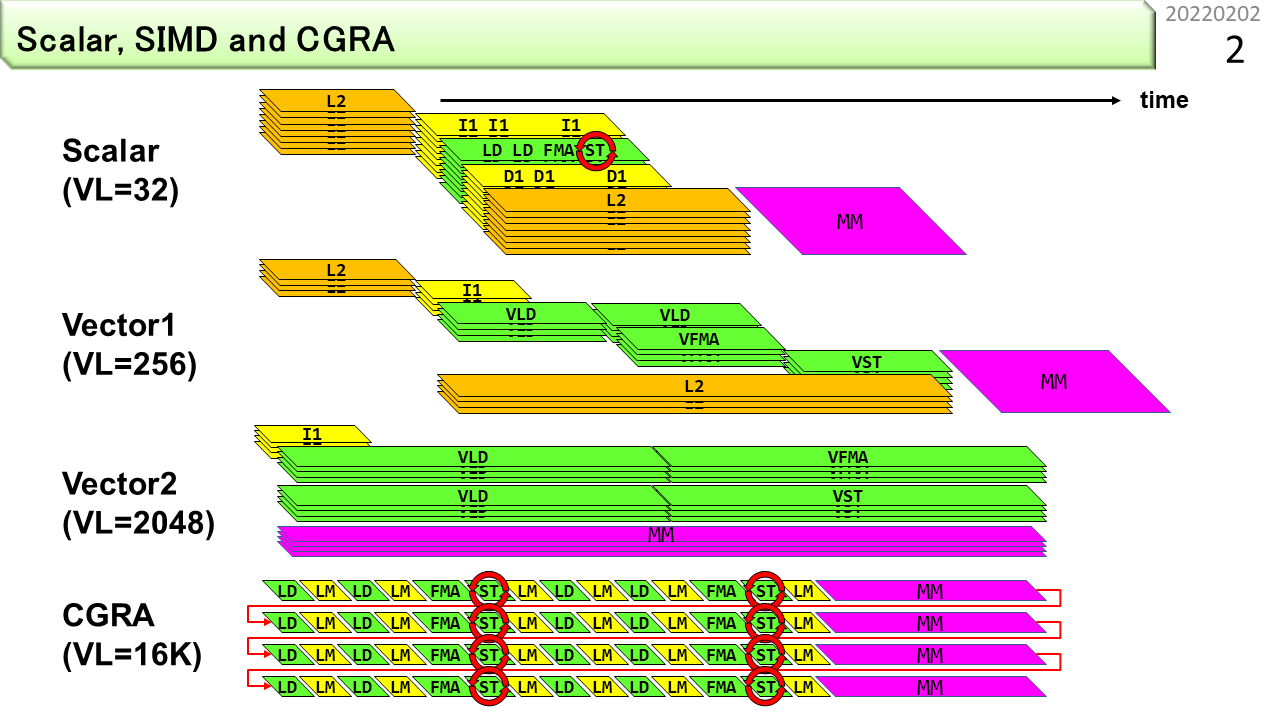
まず,高性能コンピュータのおさらいです.スカラ型のCPUにも、32要素くらいのSIMD命令はあります。コア数を増やすと性能が上がります。ただし、うまくプログラムしないと、キャッシュメモリに当たらなくなって、性能向上がすぐに頭打ちになります。256要素以上のSIMDは、ベクトルとも呼ばれます。ベクトルには2種類あります。ベクトル1は、キャッシュメモリにつながっています。キャッシュメモリは容量が小さいので、ベクトル演算の要素数は、256程度しかありません。ベクトル2は、主記憶につながっていて、要素数を2048くらいまで長くできます。昔,作りました.最後のCGRAには、様々な構成があります。この図は、演算器と64キロバイトのローカルメモリをサンドイッチ構造にしたものです。一度に扱える要素数は16000になりました。不規則なメモリ参照をローカルメモリが吸収することで、主記憶参照を規則的にして性能を上げます。また、複数の主記憶空間をパイプライン処理に組み込んで、全体として長いパイプラインを作ることもできます。要するに,ベクトル2の次は,CGRAしかないでしょ,です.ベクトル1に行っちゃった人がいますが,まあ,ちっちゃいのが好きな人は,どうぞ,です.
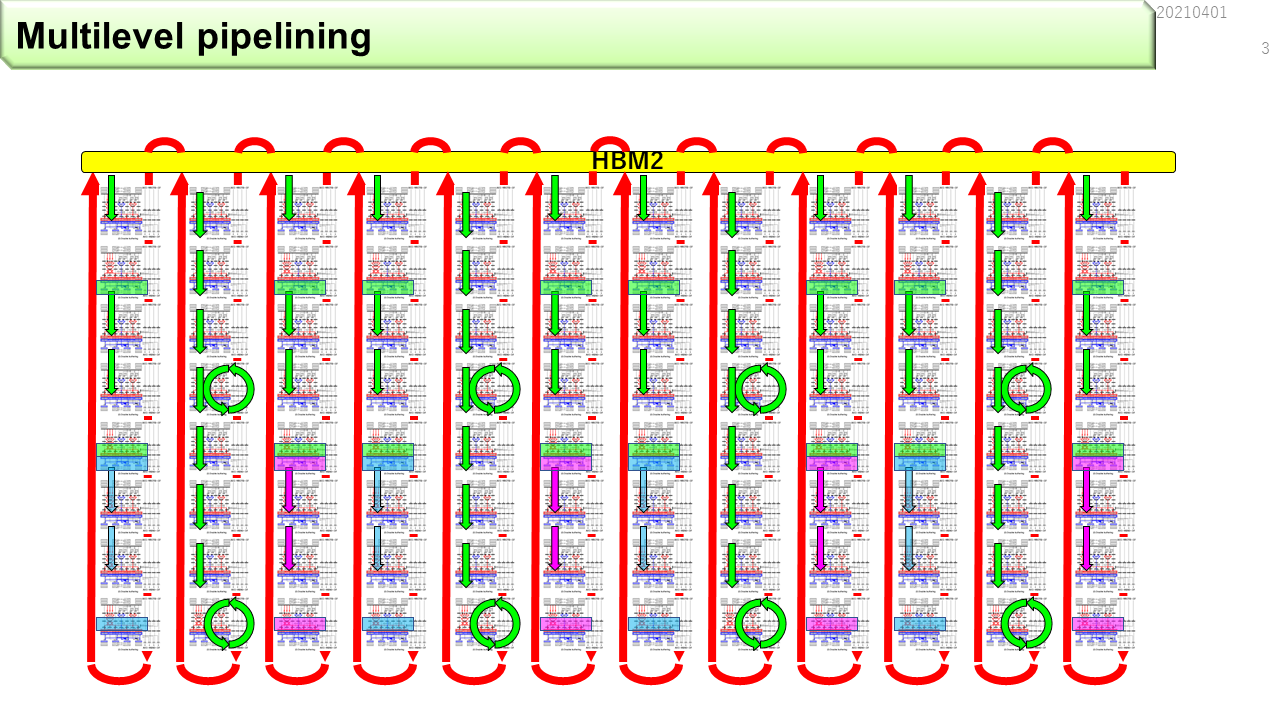
HBM2のような高性能メモリは,連続アドレスの割り当て方に何通りか用意されていて,連続アドレスがたくさんのポートを使うSIMD向けの構成や,連続アドレスを1つのポートに閉じ込めるCGRA向けの構成や,ある程度を1つのポートに閉じ込めるメニコア向けの構成などが可能です.CGRAを接続する場合,ポート毎にデータを分離して,間をパイプラインで繋ぐのがよさそうです.CGRAを使うと,HBM2によるマクロパイプライニングと,CGRA内のダブルバッファリングによるミディアムパイプライニングと,CGRAのユニット内のマイクロパイプライニングを組み合わせることで,複雑なプログラムに対しても,長いパイプラインを組み立てることができます.これは,IMAX3のマルチレベルパイプライニングです.
[2022/01/14]買ってきても使えない時代が来る?

あらためて,自己紹介。買えないものは自分で作る,ふつうの中学生でした。左上は磁界結合型ラジコンカー。技術家庭科の先生がスライドプロジェクタ(わかるかな?)のフィルムに保存してたのを卒業時にもらいました。隣は,当時科学朝日という雑誌に載ってた水トランジスタ。水を水でスイッチするという仕組みです。今思えば,これがCGRAの原点だったのかもしれません。実装するために高校では物理クラブというのに入りました。でも,特に何も活動がないので,ヨット部に。水つながりですね。しかも,使う環境に合わせてマシンをチューニングする楽しさは,最近のコンピュータと全く同じです。別にコンピュータやりたいとか思ってませんでしたが,結果的に情報工学をやってる大学に入りました。でも,3年生までおもしろい実験など何もないので,ハードもソフトも勝手に作って,勝手に雑誌に投稿して。とやってるうちにコンピュータ・アーキテクチャの研究室に配属になりました。VLIWを世界ではじめて作った研究室です。でも,当時,VLIWはマイナーだったし,そもそもCPUに関して体系的にまとまった教科書もなくて,何かを体系的に教えてもらった記憶がありません。そもそも教官側に教える気がなく,学生側に教わる気がない大学でしたしね。自分の手で何でも作って,できることを増やしていく時代だったということですね。今はそうじゃないんでしょうね。何でも体系化されてて,何でも検索・ダウンロードできる今の学生さんは幸せなんですかね。

体系的に教えたもらったこともないまま,1988年にメーカーに就職。なので,制約は,自分のスキルと,自然法則と,ユーザの要求だけ。作っても動かないものは動かないし,使えないものは使えない。コンピュータの世界というのは,とてもシンプルです。物理的に危険でさえなければ,技術的にやっちゃいけないことは何もないのです。メーカーでのスキルは今でもとても役に立っています。自分で体系化もやりました。今では似たような教科書が出回るようになりました。言っておきますが,企業に就職すると何でも教えてもらえるとか思ってないですよね。もちろん,明日の売上げに役立つ知識は教えてくれます。「いまだけ,金だけ,自分だけ」です。もっと大事な個人の基盤的スキルとか体系化の面倒なんか見ちゃくれません。そこそこのお金で何でも作れる基盤的知識とか体系というのは,日々意識して自分でものにするしかありません。何でもネットからダウンロードして,使い方だけ勉強してやれるふりをするのとは違います。1999年になって,失われた10年が経ち,新しいプロジェクトや組織が次々と消えていくのを見て,大学の先生になりました。
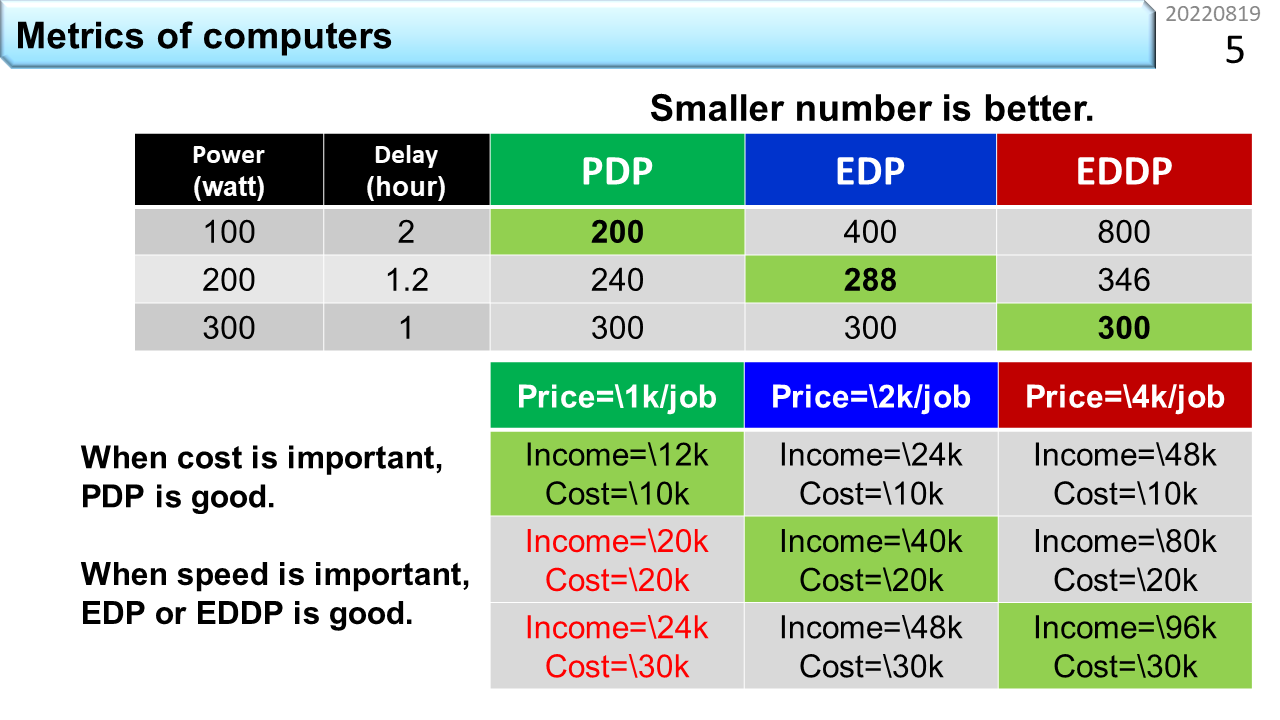
ここから本題に入っていきます。さっき,制約は,自分のスキルと,自然法則と,ユーザの要求だけと言いました。しかし,最近,制約が増えました。温暖化抑制です。コンピュータの消費電力なんて,誰かが省エネコンピュータを発明すれは済むことじゃないかと思うでしょう。今までも,コンピュータは小型化と高性能化を達成してきたんだし。では,ここでクイズです。上の表は,3種類のコンピュータの特性を一覧にしたものです。左から,消費電力(watt),同じプログラムを1つ実行するのに要する時間(hour),そして,残りのPDP,EDP,EDDPは,それぞれ,消費電力と実行時間をまとめて1つの数値で表現したものです。つまり,上から順に,100wattで2時間,200wattで1.2時間,300wattで1時間の処理能力があるコンピュータが並んでいます。どのコンピュータが最も優れているでしょうか。PDPは,Power-Delay Productの略で,watt数に実行時間を掛けた電力量です。これって電気代と同じ意味ですよね。PDPは,プログラムを1つ実行するのに必要なエネルギー消費量なので,温暖化抑制の指標として使えそうです。でも,利用者はPDPが小さいコンピュータを選んでくれるでしょうか。消費電力が4wattで実行に1時間かかるコンピュータと,消費電力が240wattで実行が1分で終わるコンピュータは,PDPは同じ数値ですが,電気代が同じなら後者を選びますね。いくら消費電力が小さくても遅いコンピュータには買い手がつきません。この実情を反映できる指標が,EDPやEDDPです。EDPは,Energy-Delay Productの略です。watt数に実行時間を掛けた電力量に,さらに実行時間を掛ける指標です。同じように,EDDPは,さらに実行時間を掛けます。これらの値が小さいほど,効率の良いコンピュータということですが,なぜ,指標がたくさんあるのでしょう。これは,利用者がどの特性を重視するかに応じて指標を変えないと,数値的な比較に意味がなくなるためです。通常はEDPを使います。スパコンのように極端に性能を重視する場合は,EDDPやEDDDPが使われます。
では,表に戻りましょう。緑色に塗られている部分を見ると,PDPが最小なのは100watt,EDPが最小なのは200watt,EDDPが最小なのは300wattのコンピュータです。次に,下の表を見ましょう。コンピュータを使ってお金を稼ぐサービスを比較しています。上から順に,さっきの100watt,200watt,300wattのコンピュータが並んでいます。第1列から第3列には,お客さんにプログラムを1回走らせるサービスを提供することで,各々1000円,2000円,4000円の売上げが得られる仮定をしています。そして,表の中身は,24時間のサービスを提供した場合の,売上げ(income)と電気代(cost)です。売上げは単価×24時間に動かせるプログラムの回数です。例えば,100wattのコンピュータは,2時間かかるので24時間では12回動かすことができます。単価が1000円なら,売上は12000円ですね。一方,コンピュータを24時間動かし続けるので,100watt,200watt,300wattのコンピュータの電気代は,1:2:3の比になります。電気代の計算を簡単にするために,10000円,20000円,30000円と仮定しましょう。このように計算すると,おもしろいことがわかります。下の表の1列目を縦に見ていきましょう。利益を「売上−電気代」と単純化した場合,例えばサービス単価が1000円だと,100wattのコンピュータの利益は,12000-10000=2000円です。200wattのコンピュータでは,20000-20000=0円,300wattのコンピュータでは,24000-30000=6000円の赤字になります。ところが,3列目のように,単価を4000円にすると,利益が最大になるのは,300wattのコンピュータです。これはとても示唆的な結果です。温暖化抑制と利益の追求とは相容れない関係にある,つまり,自由な経済活動に任せておくと,温暖化抑制に動く企業が現れることはないのです。みなさんの直感と合っていますか。省エネコンピュータは,技術革新だけでは普及せず,非効率コンピュータ利用税なり,炭素税などの外圧により,単価を下げる必要があるということですね。今はそんなものは存在しませんが,もし,そうなったら,みなさんどうしますか。高性能ゲーム機に非効率コンピュータ利用税がかかり,水没の危機にある国の支援に回る時代,ありえないと言い切れるでしょうか。
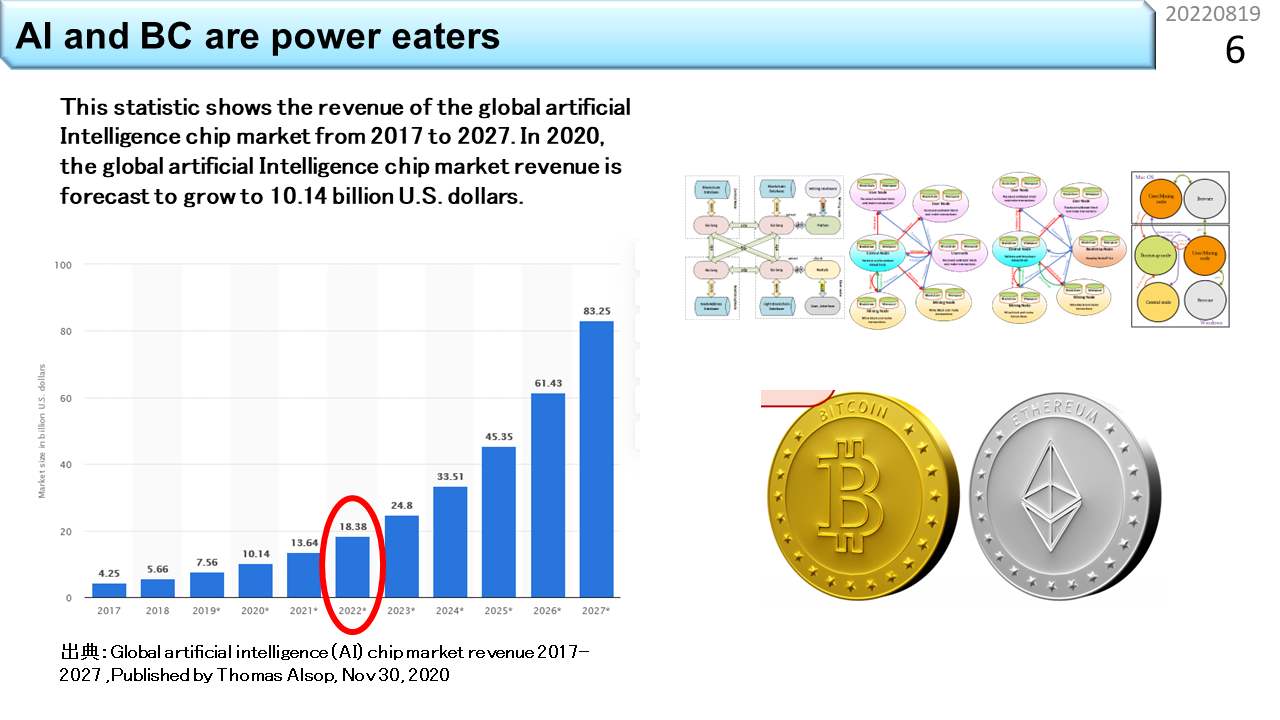
このグラフは,人工知能のマーケットの伸びを予測したものです。今は,2022年です。わずか5年後には,4倍以上に増えると予想されています。AIには大量の計算と電力を必要とします。AIすごいと言ってる場合ではありませんね。ビットコインで注目を集めるブロックチェイン(BC)技術も,大量の計算と電力を必要とします。最近,どこかの国が電力不足の大停電になって,マイニング禁止になりましたね。突然マイニング禁止になっても,困る人は少ないでしょうけど,将来,突然AI禁止になったら,社会インフラが機能しなくなる時代になっているかもしれません。温暖化抑制は,今は,主にエネルギーを作る側が対応を求められています。しかし,使う側がこのまま何の規制も受けないとは考えにくいですね。では,どうすれば,温暖化抑制に貢献しつつ,AIやBCも自由に使える社会を維持できるのでしょう。今のところ,AIやBCを規制する大きな動きはありませんから,いつもの通り,規制はいずれ,突然やってくるのでしょう。日本にはこの分野の技術の蓄積がないので,これまで通り輸入品に頼るしかありません。新型コロナワクチンと同じです。円安が進んで,とても高価になっていくでしょう。みなさんは,省エネコンピュータを手に入れるために,死にもの狂いで働かなければなりません。

ここからは,技術的な話に絞りましょう。規制が始まる時に現役世代になっている可能性が高い今の高校生は,何を理解しておくべきなのでしょう。まず,最近のコンピュータの消費電力がどのような要因で決まるのかを理解することが重要です。専門書を読めば,トランジスタ数,電源電圧,動作周波数など,様々なパラメータによって決まると書いてあります。でも,これは,コンピュータのハードウェアを実装する半導体のパラメータを基に計算しているだけで,本質的な回答にはなっていません。これまでは,誰かによる革新的実装技術のおかげで,半導体の微細化技術が進歩し,パラメータが変化し,ユーザから見れば,コンピュータの消費エネルギーは,勝手に下がってきました。残念ながら,半導体の微細化技術は頭打ちになっているので,これからは,勝手に下がることはほとんど期待できません。つまり,より広く,コンピュータを計算する機械と捉えた場合,消費電力は,別のパラメータによって決まると理解し直す必要があります。みなさんにとって,やっかいなのは,半導体の微細化レベルに代わって,コンピュータの使いやすさが,今後の消費電力を決める主要なパラメータに入ってきたという事実です。自分は関係ないと思っている人には,こう説明するのがいいかもしれません。小学生からプログラミングを勉強してきたとしても,知識がそのままでは役に立たなくなると。誰でも使えるコンピュータのプログラミング技術なんて,温暖化で融けてなくなってしまう氷山程度のものだと。最近では,コンピュータの消費電力が持続可能でないことは,多くの技術者はすでに理解していて,使い勝手を犠牲にする方向に舵を切っています。でも,老舗のメーカーに,そのような動きは見えないですよね。そりゃそうです。誰でも使えて高性能なコンピュータを売り続けなければ,会社がなくなるからです。たくさん売ろうとすればするほど,何にでも使える機能が必要であって,半導体の微細化なしに消費電力が下がる余地はありません。

これまで,情報分野に興味がある人には,2通りの勉強方法がありました。1つはプログラミングから入る方法,もう1つはハードウェアから入る方法です。でも,この方法には,ある大前提があります。プログラムとハードウェアのインタフェースに逐次実行型の機械語命令を使っていること。これをノイマン型コンピュータと呼びます。機械語命令とは,2つか3つ程度のデータを入力として1つの結果を出力させる,ハードウェアに対する指令のことです。四則演算であったり,データを移動したり,コンピュータによって様々ですが,少なくとも100種類程度の機械語命令が用意されます。みなさんが書いたプログラムは,機械語命令に翻訳・分解されて実行されます。そして,たくさんの機械語命令を1つずつ順番に実行する仕組みにした場合,逐次実行型と呼びます。これまでの勉強は,ソフトから始めても,ハードから始めても,機械語命令という普遍的な仕組みに到達するので,どっちから始めても,最後は同じ知識が揃います。でも,いつまで使えるでしょうか。図の左のように,温暖化の抑制と,指数関数的に増加するAIやBCに必要な電力の確保を両立しつづけることができるでしょうか。いつかは図の右のように,今までのような,誰でもできるプログラミング環境は諦めて,非ノイマン型に移行する動きが生まれるでしょうか。選ぶのは,未来の現役エンジニア,つまり,今の高校生のみなさんです。
[2022/01/15]何から勉強すればいいの?
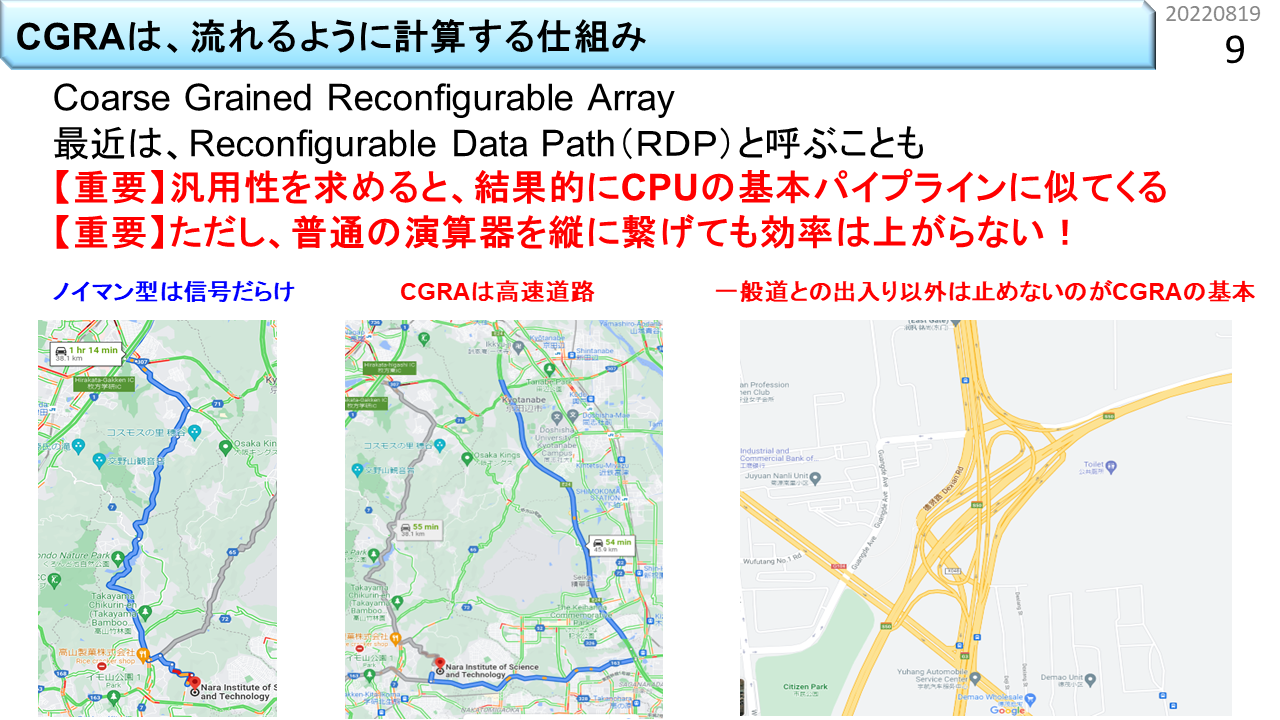
スマホも含めて,みなさんが使っているコンピュータではOSが動いていて,必要なら簡単かつ自在にプログラミングできます。これは,逐次実行型の機械語命令を使うノイマン型コンピュータであるおかげです。CPUは,Central Processing Unit(中央処理装置)の略であって,直接的にはノイマン型コンピュータを意味しませんが,中央は何でもこなす必要があるため,結果的に同じ意味に解釈されます。何でもこなすためには,様々な機能が必要で,同時に,多くの機械語命令を高速に処理する性能も要求されるので,CPUの構造は極めて複雑です。例えるなら,信号だらけの一般道(みなさんが好き勝手書いた複雑なプログラムのことです)を道を間違えながら,急発進と急停止を繰り返し,猛スピードで走り抜ける車です。CPUの高性能化技術の歴史は短く50年程度です。大学では,情報工学に関する学部や学科の講義や演習の中で学ぶことができるはずです。「はず」と書いたのは,そのような教育ができる人材が日本だけ急速に減っているためです。そりゃそうですよね。かつて隆盛を誇った国内半導体メーカーに見る影もなくなったことと無関係ではありません。一方,CGRAは,Coarse Grained Reconfigurable Array(粗粒度再構成可能デバイス)の略です。これも直接的に非ノイマン型コンピュータを意味しませんが,CPUの基本構成要素が空間的に多数配置されていて,結果的に逐次実行型の機械語命令を採用する必然性がないので,CPUとは対極の構成に位置付けられます。信号もブレーキも必要ない,理想的な高速道路(上手に書いたプログラムのことです)専用の大型超特急バスといったところです。でも,一般道はうまく走れないので,道路(つまりプログラムの性質)に合わせた使い分けが必要です。残念ながら,CPUの高性能化技術を学べる機会が減っている以上に,大学では,CGRAを実践的に学べる機会はまずありません。「教える人がいない=学ばなくて良い」という風潮が広がりつつあります。危機的ですが,知る機会がなければ,危機であることすら認識できないですね。何か大きな社会的問題が起こる時は,たいてい同じような状況が背景にあります。だから,今,これを書いています。大学生向けに10年前に書いた教科書にもCGRAの章が入っています。

では,CPUとCGRAの関係がだいたいわかったとして,これから,この目次に沿って説明していきます。元々,大学院生向け講義や,社会人向け技術セミナーに使うパワーポイントなので,用語が難しいかもしれません。正確に表現するために用語はそのまま使いつつ,わかりやすく解説を加えていきます。高校生は,社会人に比べて思い込み,偏見,先入観がないので,まずは一通り理解できると思います。もちろん,高校の授業では,こんな内容は絶対に出てきませんし,大学入試にも出ません。しかし,大学の授業というのは,小学校から高校までの授業の連続性とは比較にならないくらい,段差が大きいものです。そもそも学習指導要領なんてものはないですからね。高校生が何を勉強してきたかに関係なく,大学の先生は,教えたいことを教えようとするだけです。というと誤解するかもしれないので言い替えると,専門知識を学ぶのにたった4年しかありません,高校のレベルに合わせていたのでは全く時間が足りないということです。これから説明する内容も同じです。大学に入ったら最初の2年間でだいたい理解する必要があるレベルだと思ったほうがよいです。そのくらい,大学で勉強すべきことはたくさんあります。週休3日とか言ってる会社もありますが,それは,休みの間に自己研鑽に励めということでしょう。日本は1人負け状態です。勘違いしちゃいけません。
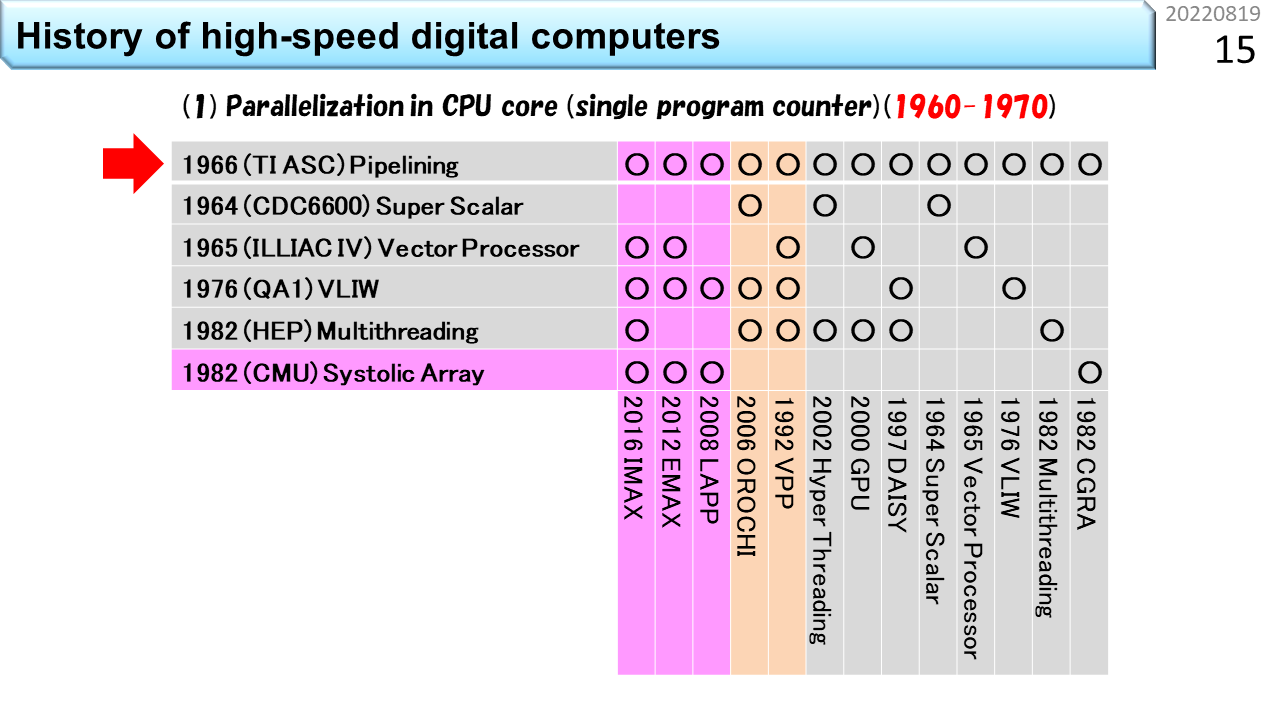
さっき,CPUの高性能化技術の歴史は50年程度と言いました。この表の左側には,6つの主要な要素技術が縦に並んでいます。下にはコンピュータの名称が並んでいて,各々,使っている要素技術の箇所に○が付いています。上から順に見ていきましょう。1番目は,「パイプライン」です。いきなり難しい用語が出てきましたね。でも心配いりません。100人の生徒が学校の食堂に行って,昼ご飯にうどんを食べる流れを想像してみましょう。ノイマン型コンピュータの中では,生徒1人が機械語命令1つに対応し,食堂のスタッフ数が同時に動作できるハードウェアの数に相当します。食堂のスタッフが1人しかいない場合,まず並んだ生徒から注文を聞きます。次にうどんを袋から出して熱湯に投入し,お湯を切って器に入れ出汁をかけて,具を載せて生徒に渡して,お金を受けとってお釣りを渡します。全部で5段階の仕事があります。最初の生徒からお金を受けとるまで,次の生徒は注文できませんから,5つの仕事の各々に12秒かかるとすると,60秒に1人の生徒しか,うどんを受けとることができません。生徒が60秒で食べてくれれば,テーブルと椅子は1人分で済みますから,お店はとても小さくできて,場所代が安くなります。でも,100人の生徒が食べ終わるまでに6000秒=100分かかるので,昼休み時間に全員が食べ終わることはできません。これでは,勉強どころではないですね。では,食堂のスタッフが5人いたらどうでしょう。1人は注文を聞く係,1人は熱湯に投入する係,1人は器に入れる係,1人は生徒に渡す係,最後の1人は会計係です。5人の作業時間がぴったり12秒に揃う場合,12秒に1人の生徒がうどんを受けとることができます。でも,解凍に60秒かかる冷凍うどんだと,5人雇っても,ちっとも速くならないこともわかるでしょう。流れ作業を使って5倍速にするには,すべての仕事時間が5分の1になることが必要です。12秒で食べ終わるのは無理なので,せめて椅子は5人分必要になります。場所代が5倍ということですね。ただし,注文を聞き間違えて作り直しになったり,食べるのが遅かったりすると,途中でつかえて5倍速にはなりません。コンピュータでも同じように,様々な要因で,速度低下が発生します。仕事を時間方向に5分割して,性能を5倍に引き上げる努力をする。これが「パイプライン」技術です。起源は,TI ASC(1966年),CDC7600(1969年),CDC STAR-100(1974年),CRAY-1(1976年)に見ることができます。
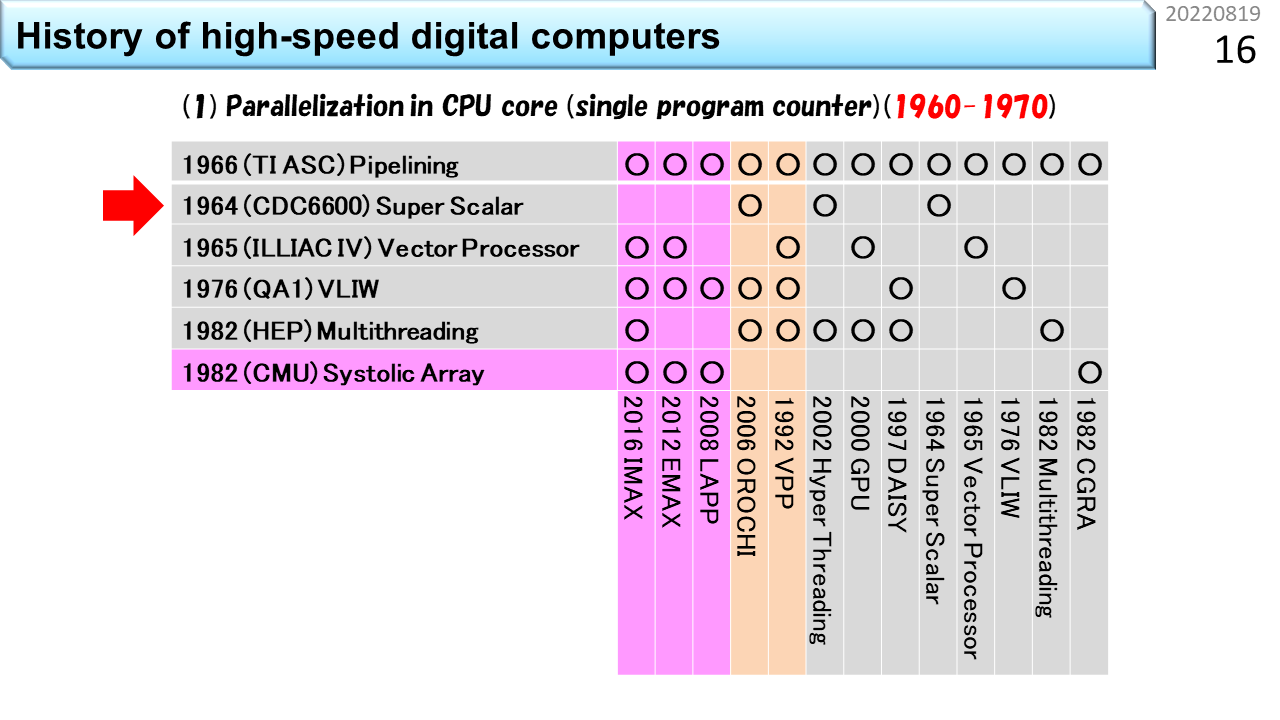
2番目は「スーパスカラ」です。スカラというのは,一度に扱う個々のデータが1つの数値のみを表現し,これに機械語命令が対応していることを指します。要するに,普通のコンピュータということです。スーパーというのは,ちょっとすごいという意味ですね。コンピュータの世界では,かなりすごいものを「ハイパー」と表現することがあります。でも,ハイパースカラという用語はありません。1つずつ逐次実行したりパイプライン実行できる機械語命令を例えば2つずつ実行する能力がある場合に,ちょっとすごいので,スーパスカラと呼びます。さっきの食堂で例えると,食堂のスタッフが10人いる状況です。生徒は2列に並んで,12秒に2人の生徒がうどんを受けとります。椅子も10人分に増えます。かなり大規模になりましたね。さらにスタッフを20人に増やせば,うどんパイプラインを4本に増やすことができます。では,スタッフ20人で,どのくらいスピードアップできるか計算してみましょう。100人の生徒が一度に並んだところでストップウォッチを押して計測開始です。スタッフが1人の場合,最初の生徒が食べ終わるまでの時間は60+60=120秒,最後の生徒が食べ終わるまでの時間は60x100+60=6060秒です。一方,スタッフが20人の場合,最初の4人の生徒が食べ終わるまでの時間は60+60=120秒です。あれ? おかしいですね。スタッフが増えたのに速くなっていません。でも,よく考えて下さい。スタッフが増えても,1つのうどんを作る速度も食べる速度も速くなっていないので,これは当然ですね。コンピュータの世界では,1つのデータが入って出ていくまでの時間をレイテンシと呼びます。では,最後の4人の生徒が食べ終わる時間はどうでしょう。生徒は4列に分かれているので1列あたり25人並んでいます。パイプラインの効果により12秒毎に列が進むので,25x12+60=360秒です。6060秒が360秒に短縮できました。つまり,16.8倍速くなりました。スタッフを20倍に増やしたのだから20倍速くなるはずですが,ちょっと足りません。理由は,もうわかりましたね。生徒が入りはじめた時は,後ろのほうのスタッフは仕事がありません。最後の生徒が入った後は,前のほうのスタッフから暇になっていきます。パイプライン処理の弱点はここですから,24時間営業で,生徒が途切れること無くうどんを食べてくれれば,ちゃんと20倍になります。コンピュータの世界では,単位時間あたりの処理能力をスループットと呼びます。つまり,パイプラインもスーパスカラも,レンテンシではなく,スループットを上げる工夫ということですね。スーパスカラの起源は,CDC6600(1964年)に遡ります。
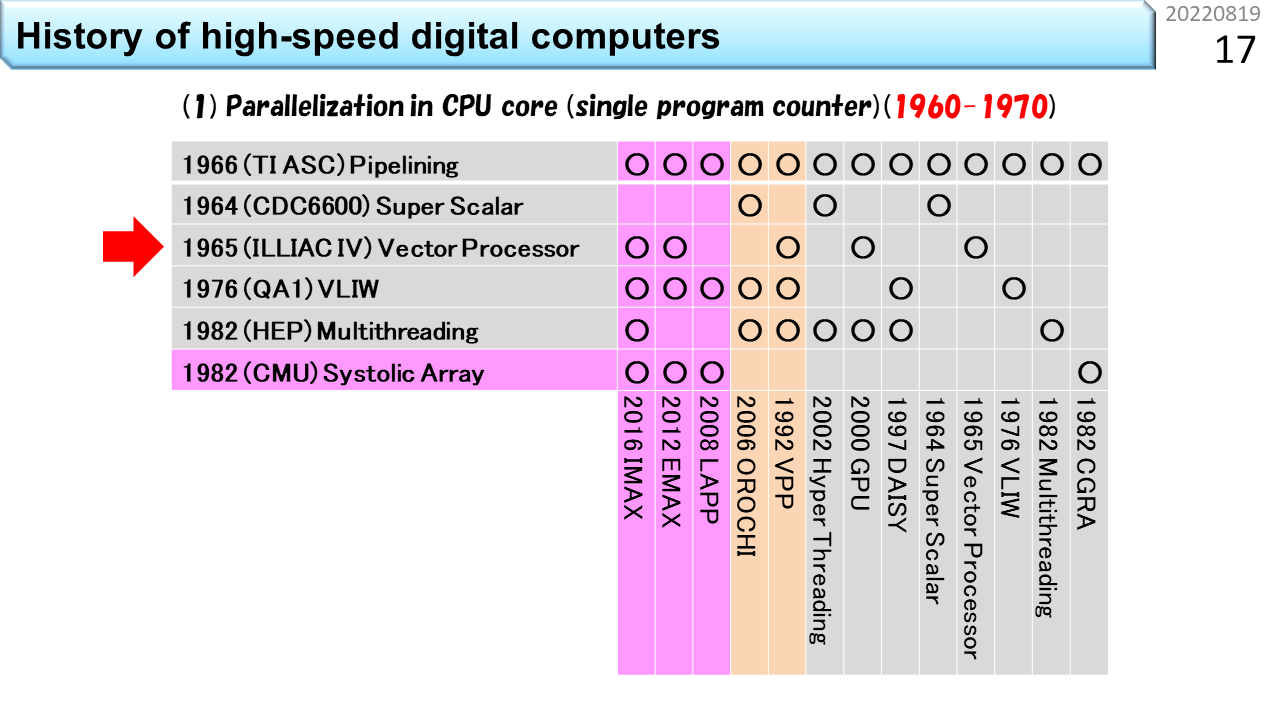
3番目は「ベクトル演算」です。複数の数値を並べてひとまとめにし,これに1つの機械語命令を対応づける仕組みをベクトルと呼びます。高校の数学では空間的に方向を持つ数値表現として2次元や3次元ベクトルを学びます。でも,コンピュータの世界では,規則的にならんでいるデータをベクトルと呼びます。個々のデータを1つの機械語命令が扱うのではなく,まとめて1つのベクトル命令が扱うことで,手間を減らすのがベクトル演算です。SIMD(Single Instruction Multiple Data-stream)方式とも呼びます。また食堂に例えましょう。ベクトル食堂には,80人のスタッフがいて,うどんパイプラインが20本です。あれれ? なぜスタッフが100人じゃなくて,80人なのでしょう。実は,ベクトル食堂では,100杯単位でしか注文できません。生徒代表が「きつねうどん100杯」と大声でスタッフ全員に伝えます。だから,注文を聞くスタッフがいらなくなって80人ということです。100人の生徒は,全員同じうどんしか注文できませんが,人件費が安くなって,スピードも上がります。だんだん工場のようになってきましたね。つまり,ベクトル演算は,小回りが効かないことは我慢して,効率を上げる仕組みです。起源は,ILLIAC IV(1965年開発開始)です。
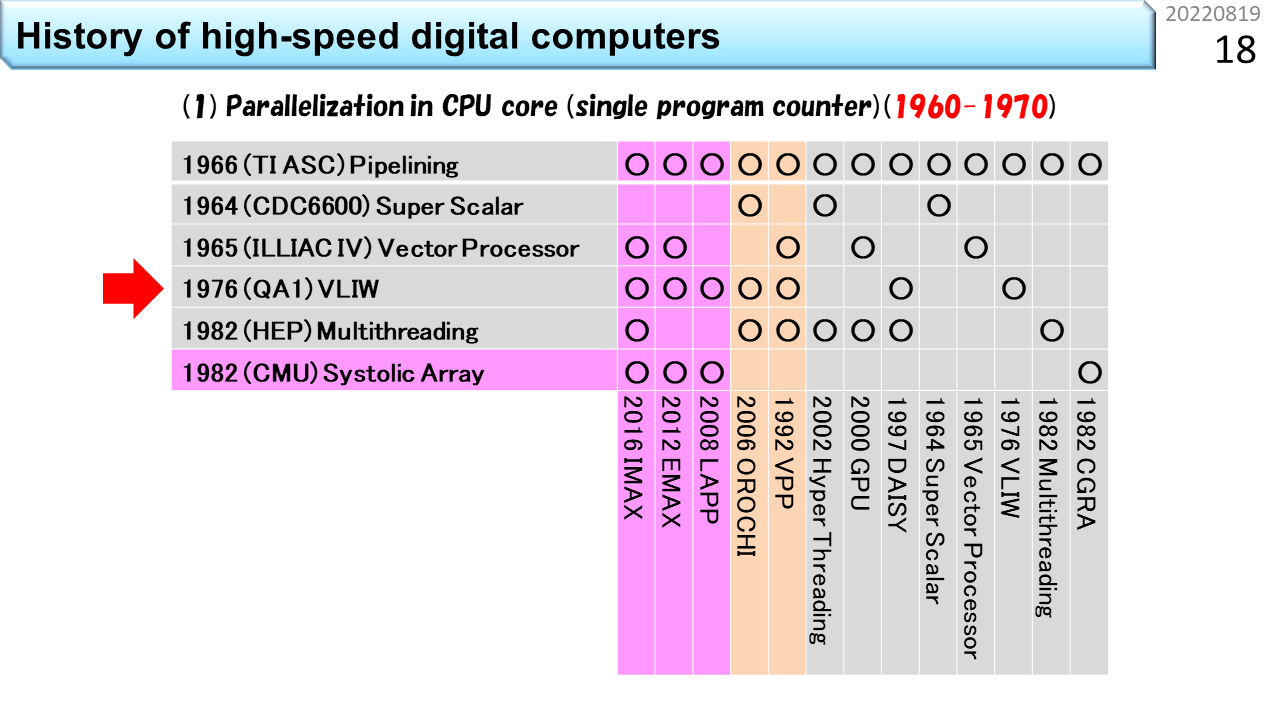
長くなってきましたが,もう少しです。4番目は「VLIW」です。Very Long Instruction Wordの略です。まず,スーパスカラのおさらいです。スタッフ20人のスーパスカラ食堂には,うどんパイプラインが4本ありました。このうちの1本で,誰かが超豪華鍋焼きうどんを注文して,列がつっかえたとします。他の列がどんどん短くなるので,食堂のスタッフは,「ごめん,こっちの列に移動して」と伝えるでしょう。つっかえた列に並んでいる生徒は,隣の列に並び直しますよね。このスタッフの声かけをコンピュータの世界では,スケジューリングと呼びます。実際の食堂では,うどん以外のメニューがありますから,この仕事は,食堂全体の状態を把握して効率を上げる仕事と捉えることができます,注文を聞いた後に,「次の生徒さん,こっちに並んで」と,常時,空いている列に生徒を誘導する仕事になります。つまり,スーパスカラをうまく機能させるには,5段階に分割した仕事に,さらにもう1段階,仕事を増やす必要があります。必要なスタッフは,20人ではなく24人です。一方,スタッフは20人のままで,同じ効果を出そうとするのがVLIW食堂です。列に並んだ後に注文を伝えるから,余計なスタッフが必要になるんですよね。生徒は,食堂に入る前に4人集まって,4人分の注文が書いてある食券を1枚だけ買います。ここで気を付けるべきは,うどんパイプラインが2本しかない場合,4人全員がうどんを注文することはできない点です。うどん2つとカレー2つといった具合にうまく4人を集めて,1枚の食券に書いてある4列に同時に並べば,列の長さがアンバランスになることなく,最初のスタッフは食券を受けとるだけで,列の振り分けをする必要はなくなります。事前にどの列に並ぶかを綿密に決めておく。これがVLIWです。4人分の情報を載せるために,機械語命令が長くなります。Very Long Instruction Wordは,とても長い機械語命令という意味です。まんまですね。パイオニアは,QA1(1976年発表),ELI-512(1983年発表),QA2(1983年発表)です。
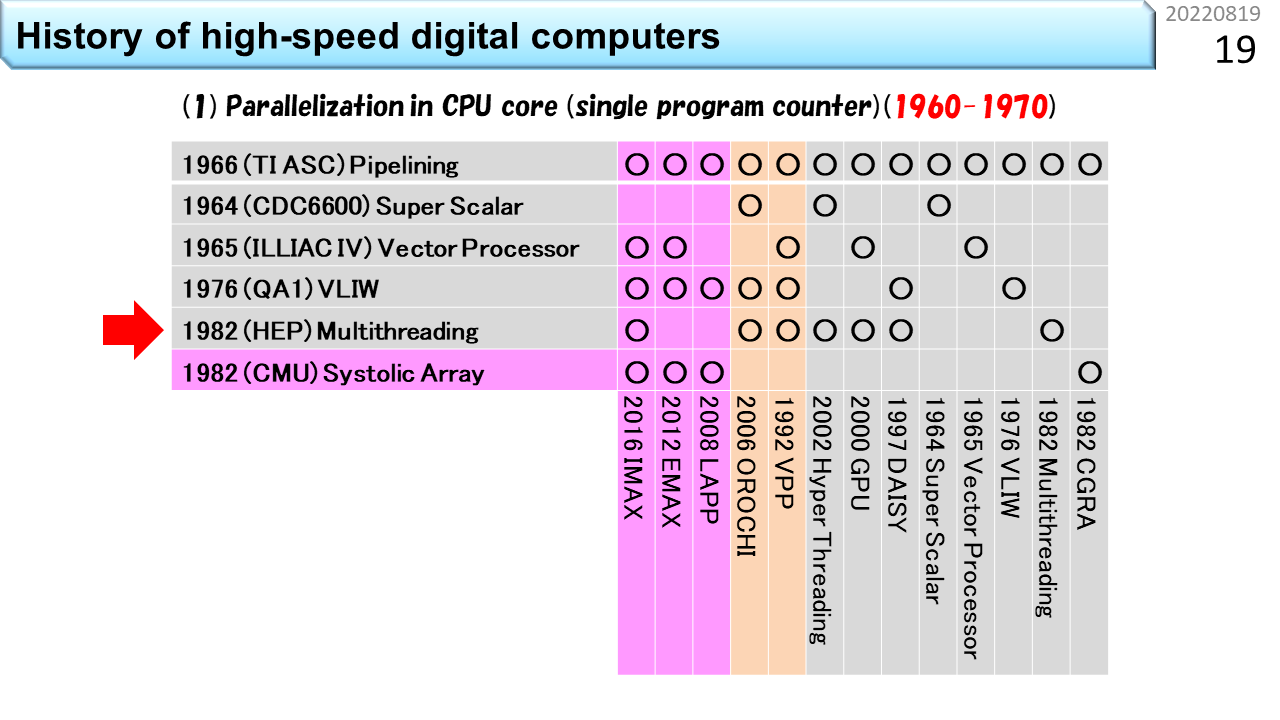
5番目は「マルチスレッディング」です。ノイマン型コンピュータに関してはこれが最後です。やれやれですね。ここまでの4つの高性能食堂は,スタッフを増やして昼ご飯時間を短縮することが目的でした。一方,マルチスレッディングは,要求されるサービスに合わせて,スタッフを減らす工夫です。今度はブラック食堂でしょうか。働き方改革的にはやばそうです。再び,スーパスカラ食堂との違いで説明しましょう。ブラック食堂は,美味しそうな日替わりメニューが100種類もあって,注文までにとても時間がかかる食堂です。しかも,鍋料理が付いているので,調理にも時間がかかります。生徒さんは,メニューの前で長時間悩み,決まった人から列に並びます。鍋に時間がかかるので,食堂のスタッフが20人いても,ほとんど暇ですね。だったら,4列の構造は維持するにしても,1人のスタッフが2列や4列を相手に交互に仕事をすれば,人件費が半分や4分の1にできますね。もちろん,全員が食べ終わるまでの時間は長くなりますが,スタッフの稼働率は上がります。商用機の起源は,HEP(1982年)です。
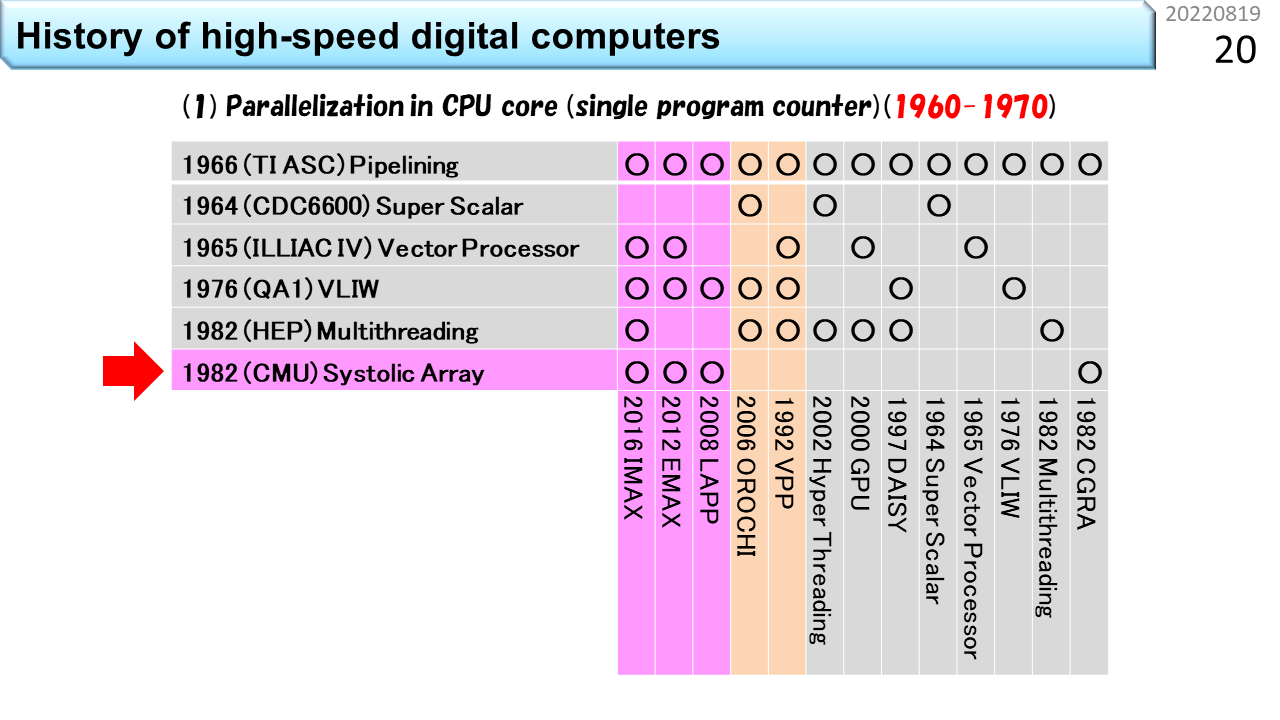
6番目は,「シストリックアレイ」です。表の中では,これだけが非ノイマン型コンピュータで,CGRAに最も近い祖先です。ノイマン型コンピュータでは,生徒1人が機械語命令1つに対応し,食堂のスタッフ数が同時に動作できるハードウェアの数に相当すると言いました。非ノイマン型は,機械語命令が次々にやってくる仕組みではありません。機械語命令に相当する機能はハードウェアに固定されていて,データだけが通過していきます。つまり,生徒は列に並んだり動いたりしません。これって,要するに,配達弁当のことですね。座っていれば,自分の席にお弁当が置かれていきます。なんということでしょう。食堂にかかるコストはゼロです。CGRAの細かな説明はあとでやるので,ここでは,高性能コンピュータに必要な6つの主要な要素技術の1つであることだけ覚えておきましょう。シストリックアレイは,1982年にCMUのH.T.Kungらが提唱しました。表に戻ります。○の有無を見ると,下に並んでいる各々のコンピュータが,どの要素技術を使っているかがわかります。別の見方をすると,全部に○が付いたものが全部入りということですね。この記事「高校生向け:今日からはじめるCGRA」は,左端に書いてあるIMAX(In-Memory Accelerator eXtension)を教材として,CGRAの理解を深めていきます。○がたくさんついていますね。大変そうです。でも,○がほとんど付いているということは,これ以上のものは考えにくいということです。ゴールが見えていれば,どんなに難しくてもなんとかなるものです。
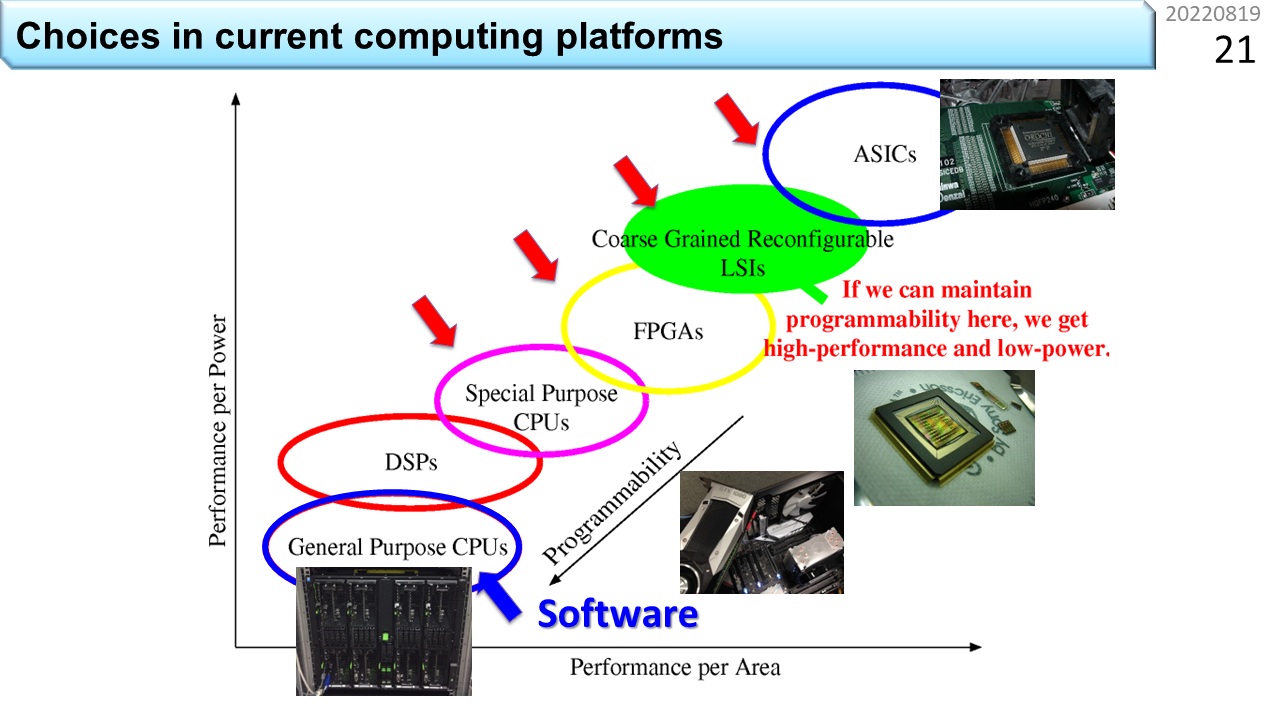
この図は,様々なコンピュータを消費電力あたり性能と,回路面積あたり性能の軸上に並べたものです。上に行くほど電力効率が良く,右に行くほど面積効率が良くなります。今は,ざっくりと,消費電力と回路面積は比例すると考えることにするので,コンピュータは,斜めの直線上に乗っかっています。まず,汎用CPUは左下にあります。前に言ったように,OSを走らせたり,何にでも使える機能が入っていると,消費電力あたり性能が低いということですね。その上のDSP(Digital Signal Processor)はどうでしょう。これは,CPUに似ていますが,OSを動かす機能は必要無く,信号処理に必要な乗算と加算に特化したコンピュータの部品です。あとで説明しますが,データの表現方法には,固定小数点形式と浮動小数点形式の2通りがあって,DSPは,より複雑な浮動小数点形式の計算が得意です。汎用性を削った分,効率は良くなります。同じような考え方に基づいて,さらに機能を削ったのが,専用目的CPUです。浮動小数点演算器を外してさらに小さく作るといった具合です。ここまでがノイマン型コンピュータです。さらに上のFPGAとCGRAが非ノイマン型コンピュータです。そして,右上の端にあるのがASIC(Application Specific Integrated Circuit)です。ASICは,ハードウェアビデオエンコーダなど,一度LSIとして作ってしまうと,機能の変更ができない仕組みです。コンピュータとは,本来,プログラムを入れ換えて別の機能を提供する機械にできる仕組みのことを指します。したがって,ASICは,厳密にはコンピュータとは呼びません。
これでだいだいの傾向がわかりましたね。前に,半導体の微細化レベルに代わって,コンピュータの使いやすさが,今後の消費電力を決める主要なパラメータに入ってきたと説明しました。同じことが図でも表現できるということですね。ここからは,コンピュータの使いやすさのことをプログラマビリティと呼ぶことにします。プログラマビリティが高いと消費電力が増える。低いと消費電力を下げることができます。おっと,まだ,FPGAとCGRAの違いを説明していませんでした。ちょうどいいタイミングなので,ここで説明しましょう。非ノイマン型コンピュータの特徴は,逐次実行型の機械語命令を使わない点にあります。でも,多少のプログラマビリティがないと,コンピュータとは呼びません。FPGAとCGRAでは,プログラマビリティの自由度に違いがあります。FPGAは,Field Programmable Gate Arrayの略です。ゲートというのは,正確には論理ゲートと呼び,2進数の1を高い電圧,0を低い電圧に対応づけて回路の入力とし,電圧の組合せに応じた出力電圧を使って,2進数の計算をする基本部品の名前です。つまり,1ビット単位で計算を表現することができる部品です。たくさんの論理ゲートをパズルのように組み合わせて必要な機能を作っていくので,細粒度再構成可能デバイスとも呼びます。対極にあるのが,CGRA(Coarse Grained Reconfigurable Array: 粗粒度再構成可能デバイス)です。ノイマン型コンピュータのプログラムが32bitや64bit単位でデータを扱うように,同程度の粒度でデータを扱うことにしたのがCGRAです。だから,プログラマビリティは,FPGAが高く,CGRAが低いとなります。CGRAは,ASICの一歩手前までプログラマビリティを犠牲にして,その分,効率を上げるという考え方に基づきます。
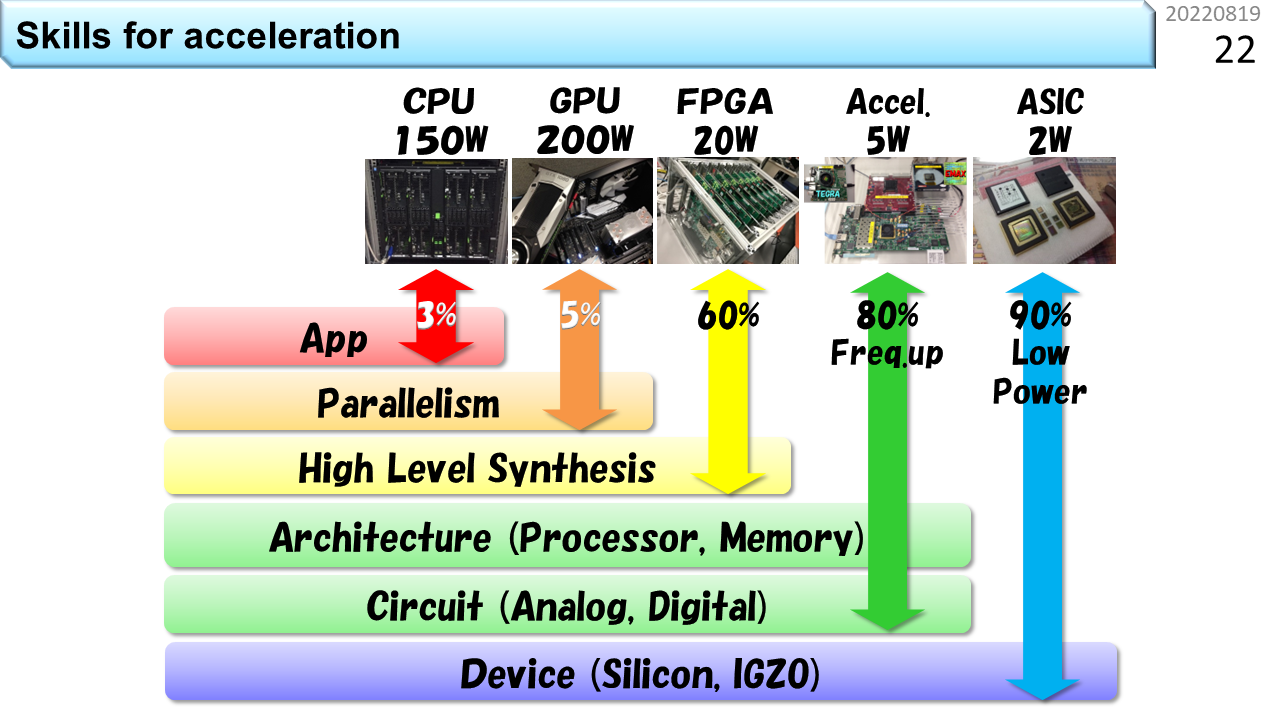
次に,様々なコンピュータを使うために必要なスキルを見ていきます。CPUは,150wattの電力を使って,どんなプログラムでも動かすことができます。必要なスキルは,C,Java,Pythonなど,与えられたプログラミング環境の使い方を覚えるだけです。小学生でもできますね。次がGPUです,元々は,2次元や3次元の物体を高速に画面表示するための専用ハードウェアでしたが,今では,大量の浮動小数点演算を行うために改良されて,AIやBCに利用されています。前に説明したベクトル計算の考え方に基づいて作られているので,制約を守りつつ,うまくプログラムを書けば,CPUよりも多くの電力を使って,かなり高速に処理を行うことができます。3番目はFPGAです。元々は回路設計の知識が必要でした。しかし,今では,Cなどのプログラミング言語と,回路に変換する高位合成ツールを組み合わせて,プログラムを少ない電力で高速に動かすことが可能になってきました。もちろん,GPUよりも制約が厳しいので,使いこなすためには,高位合成の仕組みや癖を理解しなければなりません。4番目がアクセラレータです。CGRAはここに該当します。FPGAまでは,市販品を買ってきて,使い方を覚えれば済みます。しかし,CGRAはFPGAよりも制約が厳しいため,適当に選んだ市販品で満足できる可能性は低いです。つまり,CGRAは,オーダーメイドのコンピュータと考えるのが妥当です。なので,恩恵を得るためには,自ら回路の知識を獲得する必要があります。もちろん,一旦作ってしまえば,しばらくはプログラムの変更で使い続けることができます。でも,使っているうちに,改良を加えたくなりますよね。CPUほど複雑ではなく,自分で改良を加えていける点がCGRAの利点です。同一性能を得るために必要な面積も小さいので,LSI開発に要するコストも下げることができます。いや,説明が逆ですね。お金が無いから大面積の特注CPUは作れないけど,同じ性能を出せるCGRAは小さいから,すこしの開発コストを払うだけで温暖化抑止に貢献できると言ったほうが,CGRAを使う理由をうまく説明できるでしょう。
[2022/01/16]結局のところAIって何なの?
AIが注目を浴びるようになったおかげで,今まで見向きもされなかった様々な計算手法のアイデアが見直されるようになりました。今までとの一番の違いは,AIに限れば,真面目に複雑な浮動小数点演算を使わなくても,使い方によっては,そこそこ役に立つものが作れるようになったことです。ただ,誤解してはいけないのは,「使い方によっては」の部分です。コンピュータの使用目的によっては,正確な計算ができる複雑な演算器が必要なこともあります。これからの時代,いい加減な計算をするコンピュータが,今までのコンピュータを駆逐するということではありません。温暖化抑制のために,無駄に高い計算精度を求めなくてよい部分には,電力効率の高い計算方法を使いましょうということですね。ただし,いい加減な計算をするコンピュータではOSが動かないので,今まで通りにコンピュータを使うためには,これまでのコンピュータに,いい加減なコンピュータを繋いで使うことになります。そして,いい加減なコンピュータは,OSを動かす必要がないので,非ノイマン型にして,思い切り小さく作ることができます。機械語命令もなくして,物理現象を直接使って,計算をさせましょう。これが,新しいコンピュータの考え方です。
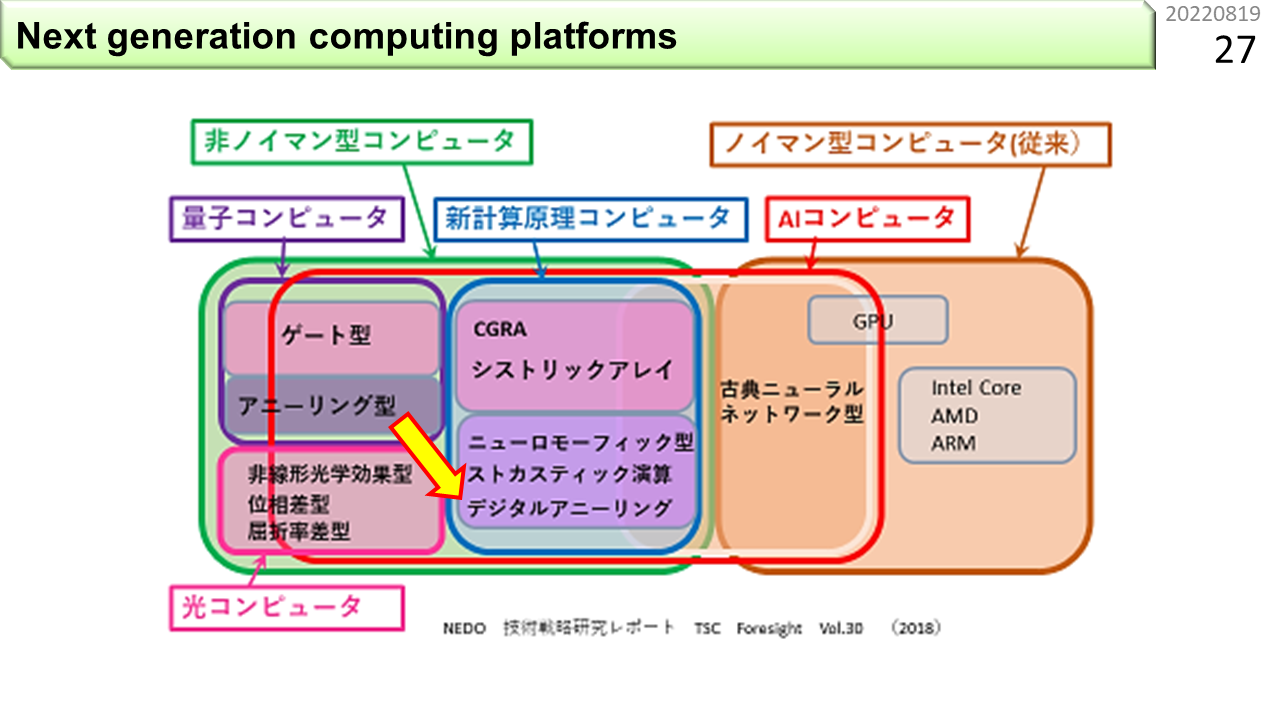
この図は,国の機関がまとめたものです。右端がみなさんの知っているコンピュータです。CPUやGPUがあって,ノイマン型コンピュータの枠で囲まれています。AIコンピュータという赤枠がありますね。ここが,今まで見向きもされなかった様々な計算手法を含んでいます。具体的には,量子コンピュータ,光コンピュータの一部と,新計算原理コンピュータという括りが入っています。もちろん,これは,今の時点で,将来的に実用化されるかもしれない技術を網羅しているだけなので,これからどれが使えるようになっていくのかは,全くわかりません。徐々に左に移行するという意味ではないので,高校生は,誤解しないように。特に,電力効率の観点では,まだ,量子コンピュータも光コンピュータも,評価できるレベルにありません。一方,新計算原理コンピュータには,CGRA,シストリックアレイ,ニューロモーフィック,ストカスティック,デジタルアニーリングというキーワードが並んでいます。これらは,実際にいろいろなプログラムを動かして,電力効率を評価できる段階に来ています。ただ,AIに限定せず,汎用的にプログラムできるもの,具体的には,次に説明する積和演算ができるものに絞る場合,デジタルアニーリングは対象から外れます。これは,最短経路探索や,巡回セールスマン問題など,最適化問題を解くのに特化した計算の仕組みです。参考文献
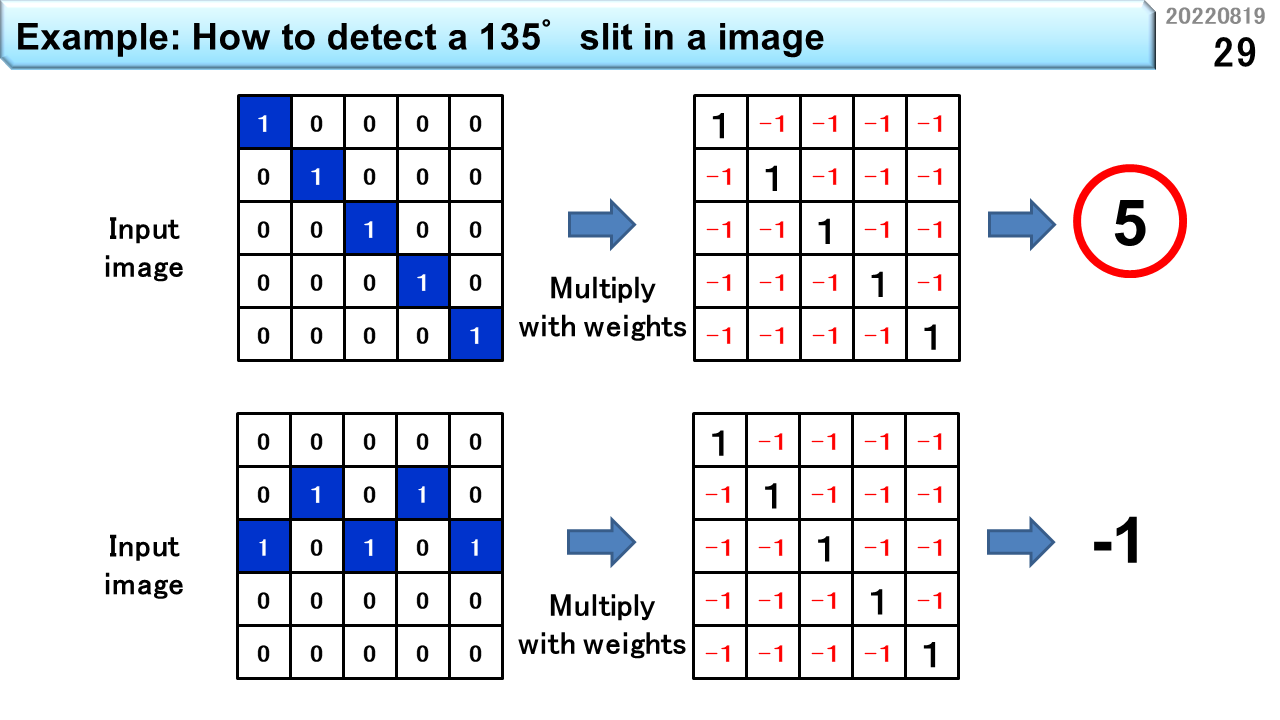
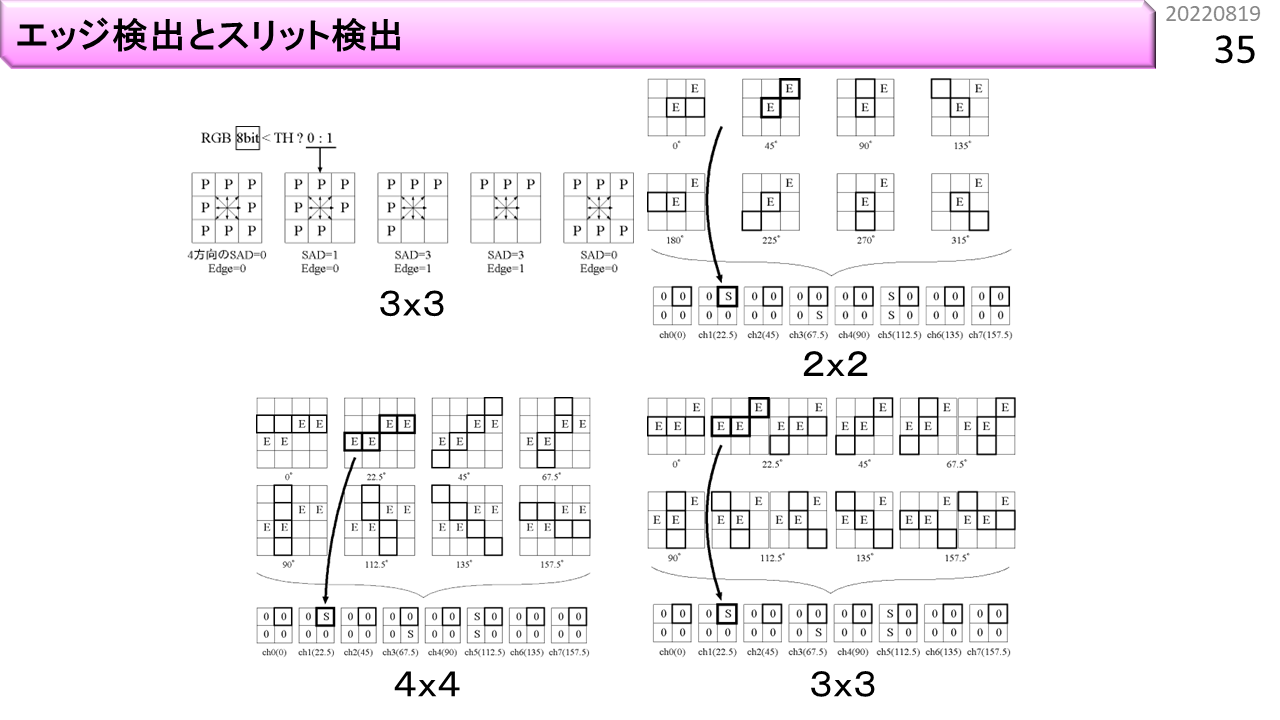
さて,AIという言葉が流行っていますが,高校生のみなさんは,中身を理解しているでしょうか。以前に,コンピュータの機械語命令は,四則演算ができると説明しました。実は,AIで最も利用されるのが,積和演算です。つまり,加算,減算,乗算です。これだけで,突然身近になりましたね。この図は,画像識別の前処理に必要な,スリット検出器の考え方を示しています。左上は,角度135度のスリットを含む,画素数5x5の輪郭情報です。つまり,青い画素は,入力画像そのものではなく,周囲の色とは異なる部分を検出する輪郭抽出を行った結果,輪郭が存在することを1で表現しています。スリット検出とは,輪郭情報の中に,特定の角度を持った1の集合が存在するかどうかを計算します。このために,右上の重みと呼ばれる値を用意します。輪郭情報が1である部分に1,0である部分に-1が入っていますね。同じ位置どうしを乗算し,5x5のすべての位置の乗算結果を加算すると5になります。もし,左上の輪郭情報の白い部分に1が余計に入っていると,どうなるでしょう。対応する重みは-1なので,さっきの加算結果5は,4に減ります。つまり,1であって欲しい場所の重みを1,0であって欲しい場所の重みを-1にしておき,輪郭情報と隅々まで突き合わせ,閾値以上の値になる部分を記録すれば,どこに135度のスリットが存在するかがわかるというわけです。同じ重みを使って,左下の輪郭情報に適用するとどうなるでしょう。結果は-1になるので,135度のスリットは存在しないと判断できます。このように,例えば22.5度刻みで様々な角度のスリットの有無を調べ,さらにこの情報を使って,もっと複雑な形状があるかどうかを同様に積和演算で調べることを繰り返すことで,あらかじめ教えた画像のどれに近いかをコンピュータに判定させることができます。
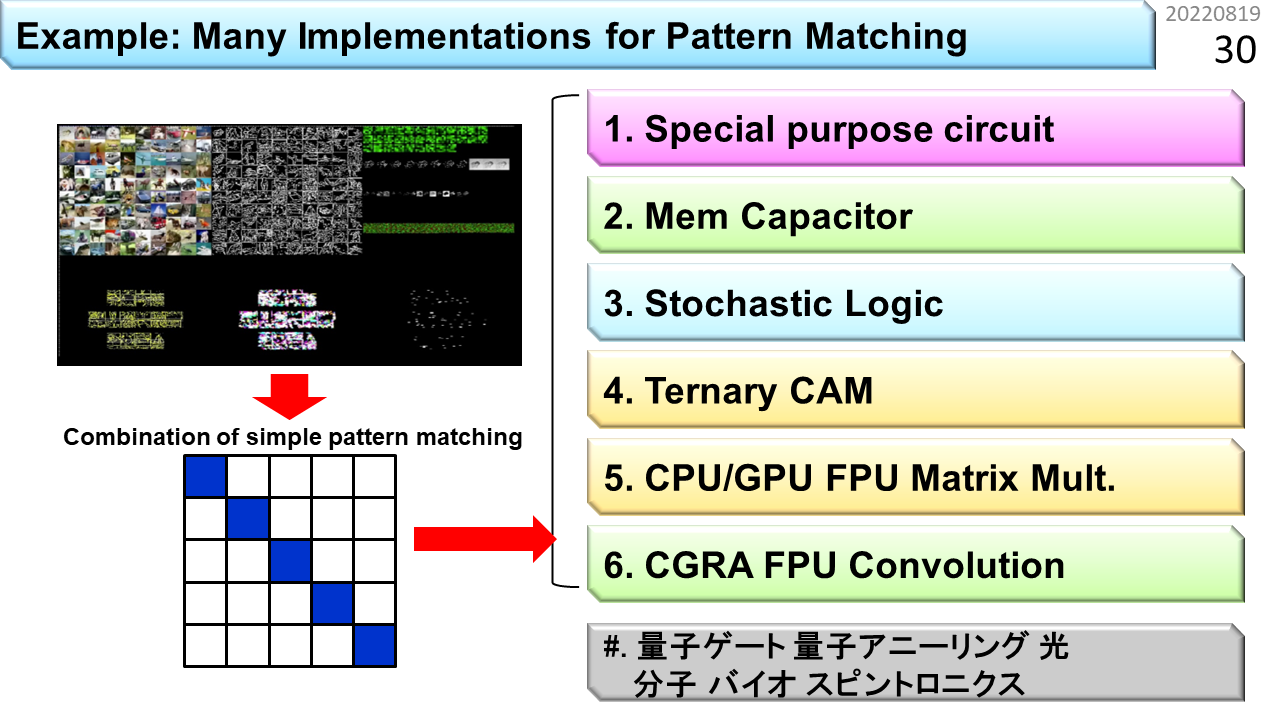
では,これから,スリット検出方法を6種類,紹介していきます。この中には,さっきの新計算原理コンピュータの枠に入っていた,デジタルアニーリング以外の方法が,全部入っています。この6種類を理解するだけで,コンピュータとAIの関係をかなり把握できるはずです。さらに下にあるのは.... まだサイエンスです。出口があるのかどうか,よくわかりません。

1つ目は,脳の第1次視覚野を模倣した専用ハードウェアです。以前にASICと呼んだものなので,厳密にはコンピュータじゃありませんが,最も小さく作れるので,知っておいて損はない実装方法です。
まず,輪郭情報からスリット情報を求めることができることは,すでに説明しました。前の例では,積和演算を使いました。演算器を作るには,たくさんの論理ゲートを組み合わせる必要があります。しかし,1であって欲しい輪郭情報を集めて,全部が1であるかどうかを確認するだけなら,5本の入力が1である場合に1を出力する論理ゲートを1つ使えばよいです。回路はとても小さくなります。さらにスリット情報と,左目,右目画像から,視差(物体までの距離)を求めたり,上下左右,および,奥行き方向の物体の動きを検出できます。実際,脳の第1次視覚野には,このような機能が入っているそうです。生き物の構造は本当に効率的にできています。不思議ですね。
これは,脳の第1次視覚野を模倣した専用ハードウェアを使った,画像識別の様子です。複雑なプログラムを使うことなく,とても小さく作ることができます。もちろん,プログラムで実現したものではないので,コンピュータとは呼びません。
[2022/01/17]ニューロモーフィックって何なの?

2つ目は,ニューロモーフィック型と呼ぶ,神経細胞を構成するニューロンとシナプスを模倣した構造です。第1次視覚野よりも汎用性が高く,重みを変更することがプログラミングに対応します。みなさんが知っているコンピュータとはかなり違いますが,コンピュータの一種と考えて差し支えありません。
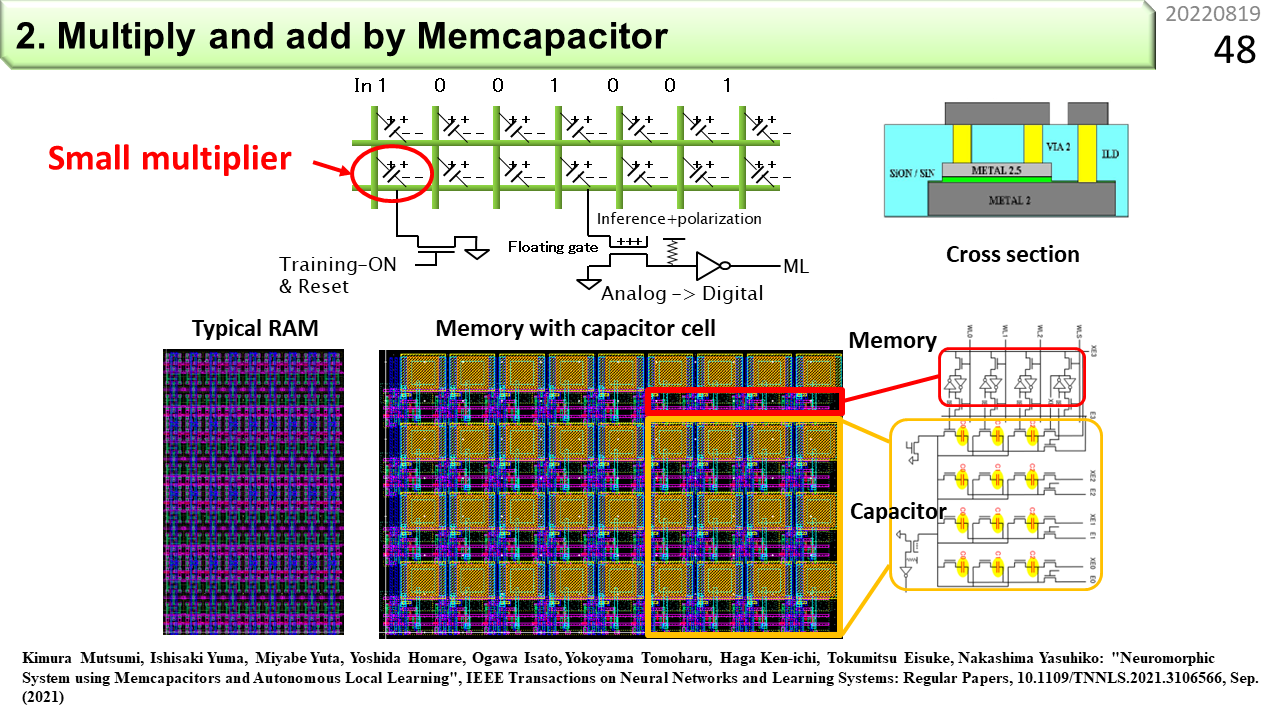
ニューロモーフィック型は,重みを記憶する素子と,素子を通過する配線から構成されます。そして,重みを記憶する素子には,抵抗器やコンデンサを利用することができます。抵抗器の場合,両端に同じ電圧を加えても,抵抗値(単位はオーム)が大きいと,流れる電流は小さくなります。最初に説明した積和演算に使えそうです。輪郭抽出結果を25個の抵抗器それぞれの両端に加える電圧,重みを25個の抵抗値の逆数(つまりコンダクタンス)に置き換えて,25個の抵抗器の片側を全部繋ぐと,流れ出る電流は,積和演算結果と同じになりますね。2進数を使わなくても積和演算器が作れました。もちろん,この方法では,-1を掛けて引き算することはできないので,少し工夫が必要です。でも,温暖化抑止の観点からはどうでしょう。抵抗器は,電圧をかけている間,電流が流れ続けるので,エネルギーを無駄使いしていると言えます。抵抗器は良くないですね。図は,コンデンサに置き換えた後のニューロモーフィック型です。縦の配線が入力である輪郭抽出結果,横の配線が積和演算結果,交差点に斜めに接続されているのがコンデンサです。重みは容量(ファラッド)に対応付けます。ところで,重みを変更することがプログラミングと言いました。ということは,抵抗器の抵抗値や,コンデンサの容量を自在に変更する手段が必要ですね。抵抗値を記憶して,必要に応じて変更もできる抵抗器のことをメモリスタと呼びます。コンデンサの場合はメムキャパシタです。まだ研究段階なので,お店には売っていません。でも,今の高校生が現役世代になるころには,実用化されていることでしょう。
コンデンサは,直流成分を通し難く,交流成分を通し易いので,縦の入力は,パルスで与えます。コンデンサの容量が大きいと,パルスを通し易くなり,多数のコンデンサの出口を繋いでいる横の配線に,パルスを集めた波形が出力されます。これも積和演算結果とみなすことができます。普段はパルスが入ってこないので,電流が流れ続けることもなく,無駄なエネルギー消費はなさそうです。1列目のコンデンサには135度のスリットに対応する重み,2列目のコンデンサには90度のスリットに対応する重みといった具合に多くの重みを一度に設定すれば,1組の輪郭抽出結果に対して多くのスリット検出を同時に行うことができます。計算精度はデジタルコンピュータにかないませんが,大規模化に向いていますね。脳もこんな具合に情報処理をしているのかもしれません。
[2022/01/17]確率的計算って大丈夫なの?

3つ目は,ストカスティック演算です。これもパルスを使う計算方法です。ただし,乱数を使うところが,おもしろい点です。乱数で積和演算なんてできるのでしょうか。答えはYESです。左側の図は,普通のデジタルコンピュータを使って行列積を計算した結果を可視化したもの。右側の図は,ストカスティック演算を使った行列積の結果を可視化したものです。輪郭はぼやけていますが,形は似ています。ストカスティック演算の別名は,確率的計算です。実行回数を増やして平均値を残すと,徐々に正しい結果に近付いていきます。AIの場合は,平均せずに1回の計算結果をそのまま使っても,うまくいく場合があります。
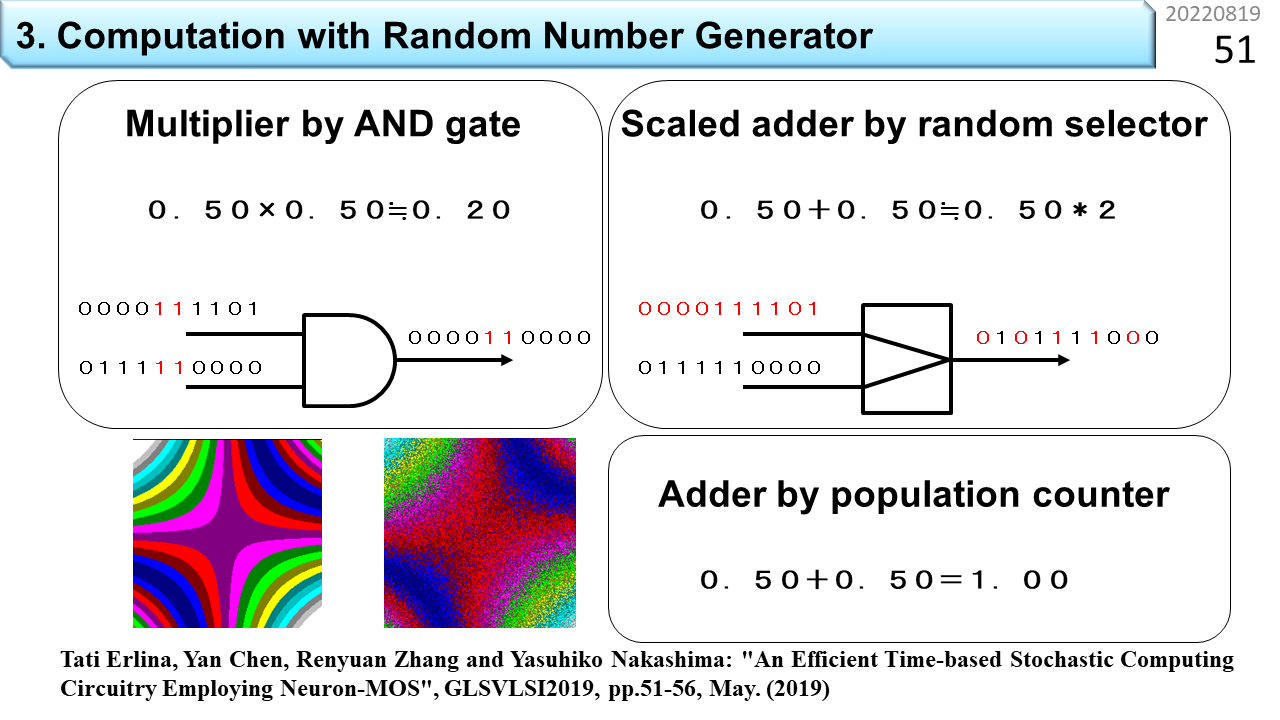
まず,2進数の乱数列を2系統用意します。乱数列は互いに独立している必要があります。上の乱数列を少しずらして下の乱数列にするといった手抜きをしてはいけません。乱数列に相関関係があると,偏った計算結果しか得られません。そして,図の左側から,論理ゲートに入力します。ここで使うのは,入力がすべて1の場合に1を出力するANDゲートです。上の乱数列が0000111101,下が0111110000です。配線は1本しかないので,右の桁から順にANDゲートに入力します。赤字の部分が,両方とも1の場合です。ゲートの右側には0000110000が出力されます。これが乗算結果です。仕掛けは簡単。上の乱数列では,1の確率が0.5,下も同じです。確率の授業を思い出して下さい。両方が1になる確率は,0.5x0.5と計算しますね。両方が1になる時に1を出力することと同じ意味です。ただし,正確な乗算結果は0.25ですが,ANDゲートの出力では1が2つなので,乗算結果は0.20になりました。少しずれています。でも,入力が独立した乱数列なので,何度も繰り返せば,0.25に近付くことがわかりますね。確率的とはいえ,これだけで乗算ができるなんて,便利ですね。
では,加算はどうでしょう。乗算の場合,0から1までの値を入力すると,結果も0から1の範囲に入ります。でも,たとえば,0.7+0.7の結果は1を超えてしまいます。乗算と同じようにできるでしょうか。そこで,ひとひねりです。平均値を思い出して下さい。加算結果を入力数で割ったのが算術平均ですよね。算術平均であれば,結果が1を超えることはありません。これを利用すれば,確率的加算器を作ることができます。右の図では,上の乱数列が赤字になっています。そして,出力には,上と下の乱数列から交互に取り出したビット列が並んでいます。上下のどちらを選ぶかを乱数で決めでもよいです。これが確率的平均値の求め方です。出力には1が5個あるので0.5ですね。入力数が2なので,結果を2倍します。運よく1になりましたね。これが加算結果です。でも,入力数が10だと,何が起こるでしょう。出力の1の数は,0から10までの10通りしかありません。平均値が10通りしかなく,最後に10倍するので,結果は,0,10,20,30,40,50,60,70,80,90,100のどれかにしかなりません。もう少し正確さが欲しい場合は,Population Counterを使って,1の数を正確に数えます。最後に,従来型のデジタル回路で加算をします。これなら,0から100まで100通りの結果になります。
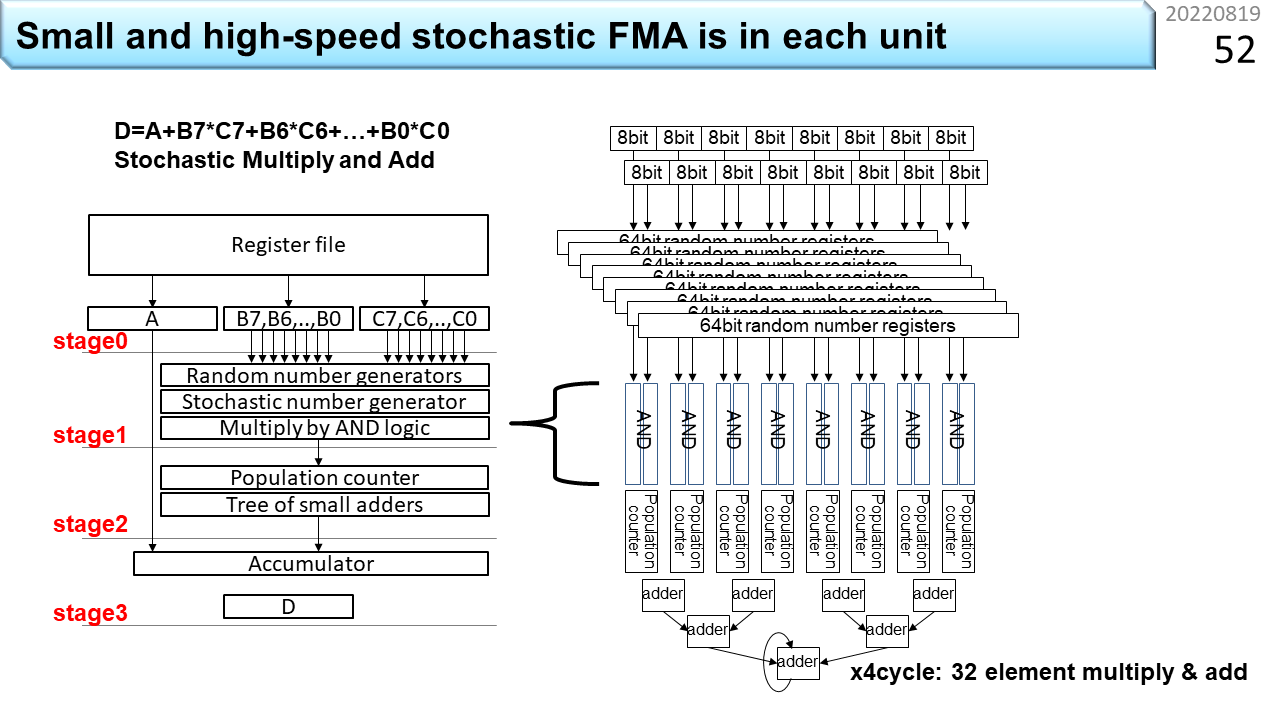
前の例は,ハードウェアは小さいですが,1本の配線を使ってデータを順に入れるので,計算にとても時間がかかります。確率的計算の考え方はそのまま使って,もっと高速にできないでしょうか。図は,配線数を増やして高速化する方法です。左の図を見ましょう。上にあるRegister fileが,普通のコンピュータで使う2進数で表現した,8個の被乗数B0〜B7と,8個の乗数C0〜C7が置いてある場所です。ここでは,D=A+Σ(BixCi)という積和演算を確率的に行うことを考えます。まず,B7とC7をそれぞれ,別系統の乱数列(Random number generators)を使ってエンコードします。元の2進数をさっき説明した確率的表現(Stochastic number)に変換する作業のことです。具体的な変換方法は,みなさんへの宿題としましょう。いろんな方法が見つかるはずです。変換できたら,B7とC7に対する確率的表現をANDゲートに入力します。さっきの例では10ビットの確率的表現と1個のANDゲートを使いました。今後は,10ビットの確率的表現を縦に並べて,10個のANDゲートに一斉に入力します。配線数は増えますが,一度に乗算できますね。そして,Population Counterを使って1の数を数え,2つずつ加算します。これを4回繰り返すと,32要素の確率的積和演算ができます。怪しげな計算方法ですが,コンピュータっぽくなってきましたね。
[2022/01/18]昔からある検索専用連想メモリは使えないの?

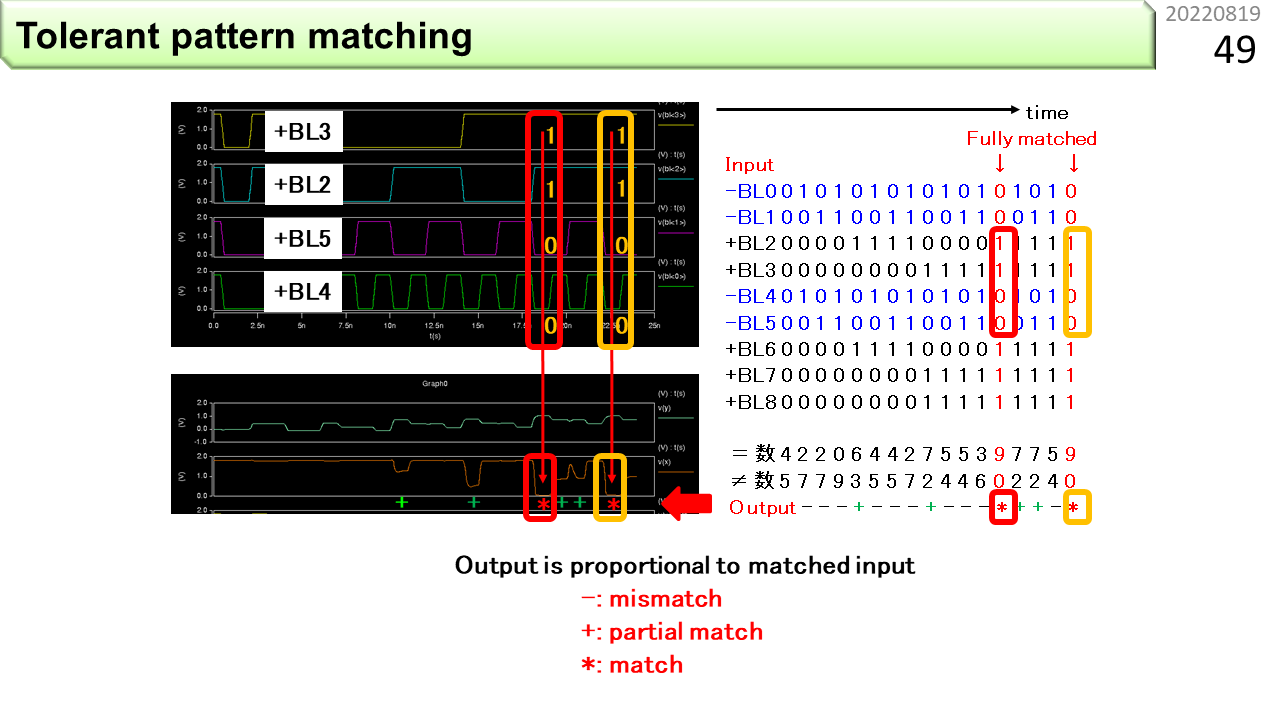
4つ目は,見つけたいパターンと直接比べる方法です。パターンを覚えさせて,あとから,似たパターンがあるかどうかを調べることができるメモリをCAM(Content Addressable Memory)と呼びます。さらに,特定の場所は比較対象外(マスクと呼びます)とできるCAMを3値CAM(Ternary CAM)と呼びます。
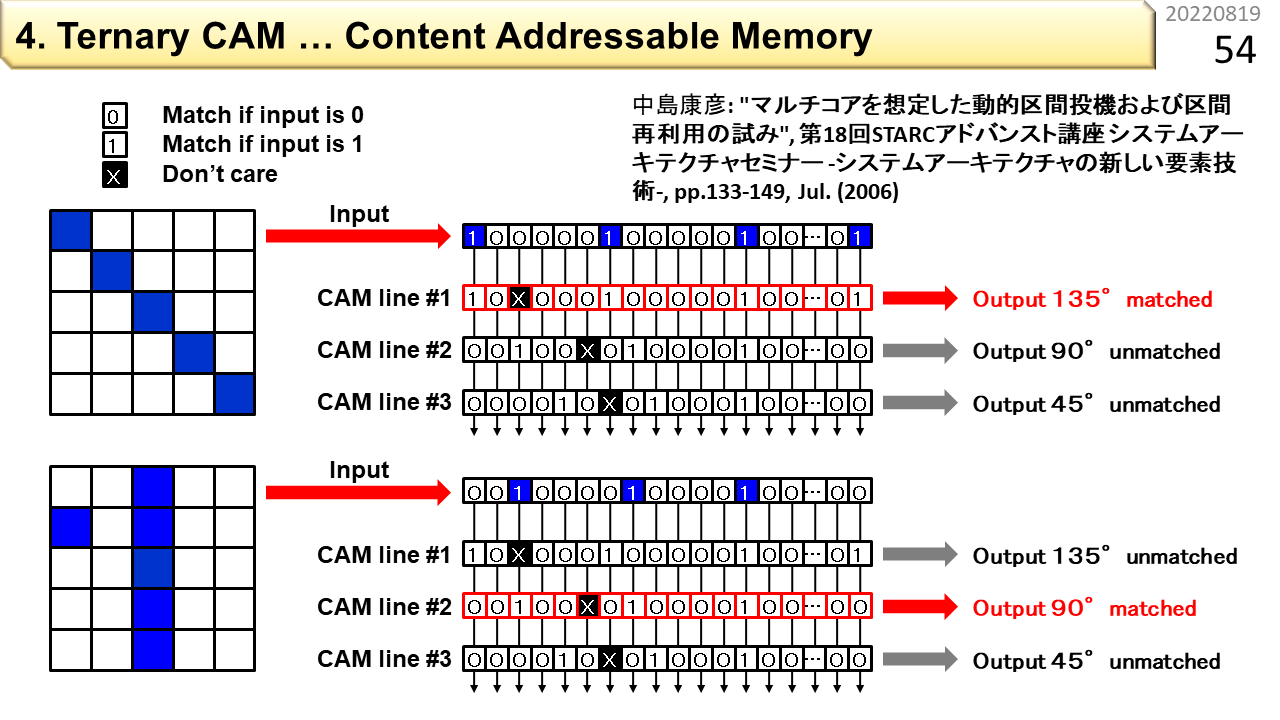
例を使って説明します。この図は,前に示したパターンをCAMに登録する様子です。CAMに登録する単位は1行なので,CAMに与えてチェックしたい5x5のパターンを1行に並べ直します。CAMの中には,あらかじめ,判定に使うパターンを同様に登録しておきます。1であって欲しい部分に1,0であって欲しい部分に0,比較しない部分には×(Don't care)を登録します。Ternaryは3種類という意味です。CAMの1行目には135度,2行目には90度,3行目には45度に対応するパターンを登録しました。このCAMに,左側の輪郭情報を入力すると,行ごとに,一致したかどうかの判定結果が出力されます。うまく使えそうですね。
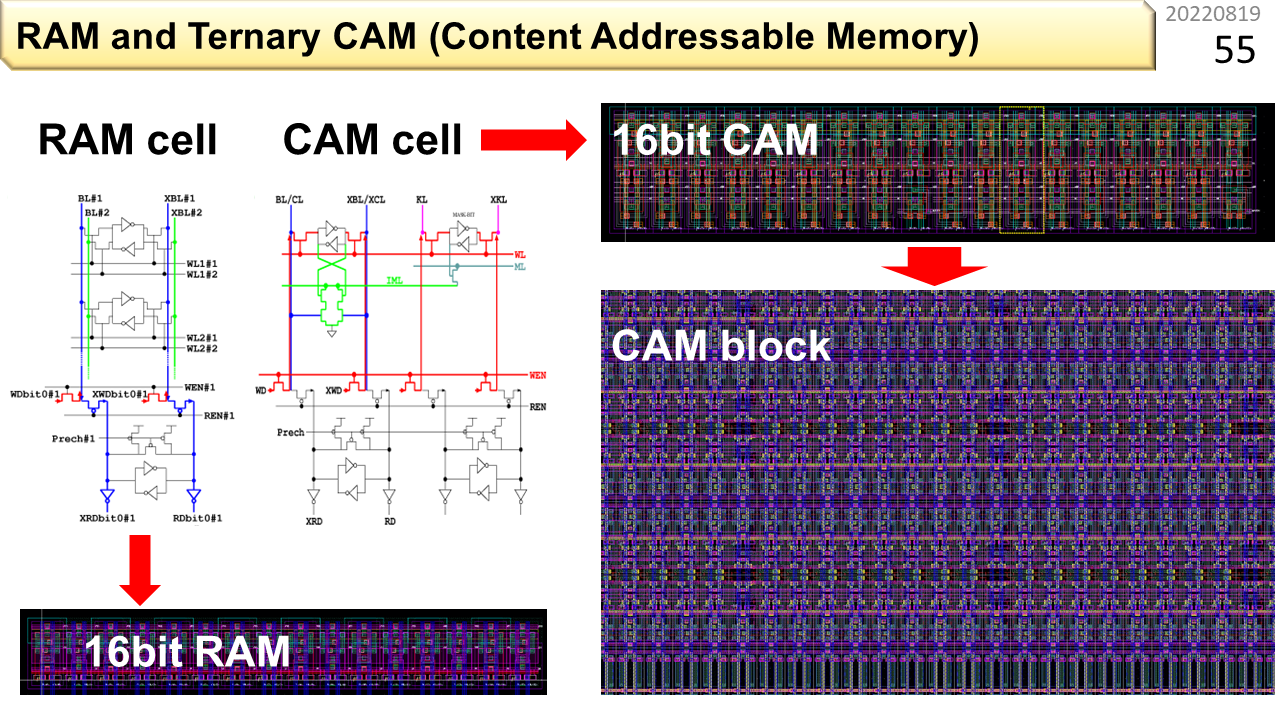
この図の左が普通のメモリ(RAM),右がCAMの内部構造を示しています。上のほうの,三角が輪っかになっている部分に探したいパターンが登録されています。CAMの中に,IMLと書いてある緑の配線がありますね。比較の前に,ここに電圧をかけて,IMLに電荷を溜めます。次に,縦の配線に,入力データを流します。登録されている0/1のパターンと,入力データのパターンに,1箇所でも不一致があると,IMLに溜った電荷が抜けて0Vになります。また,登録済で不一致の行だけでなく,使っていない行でも電荷が抜けます。電圧が保たれるのは,不一致が1つもない行だけなので,ほとんどの電力は無駄になります。このように,CAMは,AIに使えそうに見えますが,原理的に消費電力が大きいので,温暖化抑制のためには使い難いことがわかります。
[2022/01/18]ノイマン型コンピュータではどうやるの?

5つ目は,普通のコンピュータで計算する方法です。といっても,最初に説明した積和演算をそのままやるだけです。正確に計算するためには,浮動小数点数を使います。そして,浮動小数点数の乗算や加算を速く行うには,浮動小数点演算器を使います。
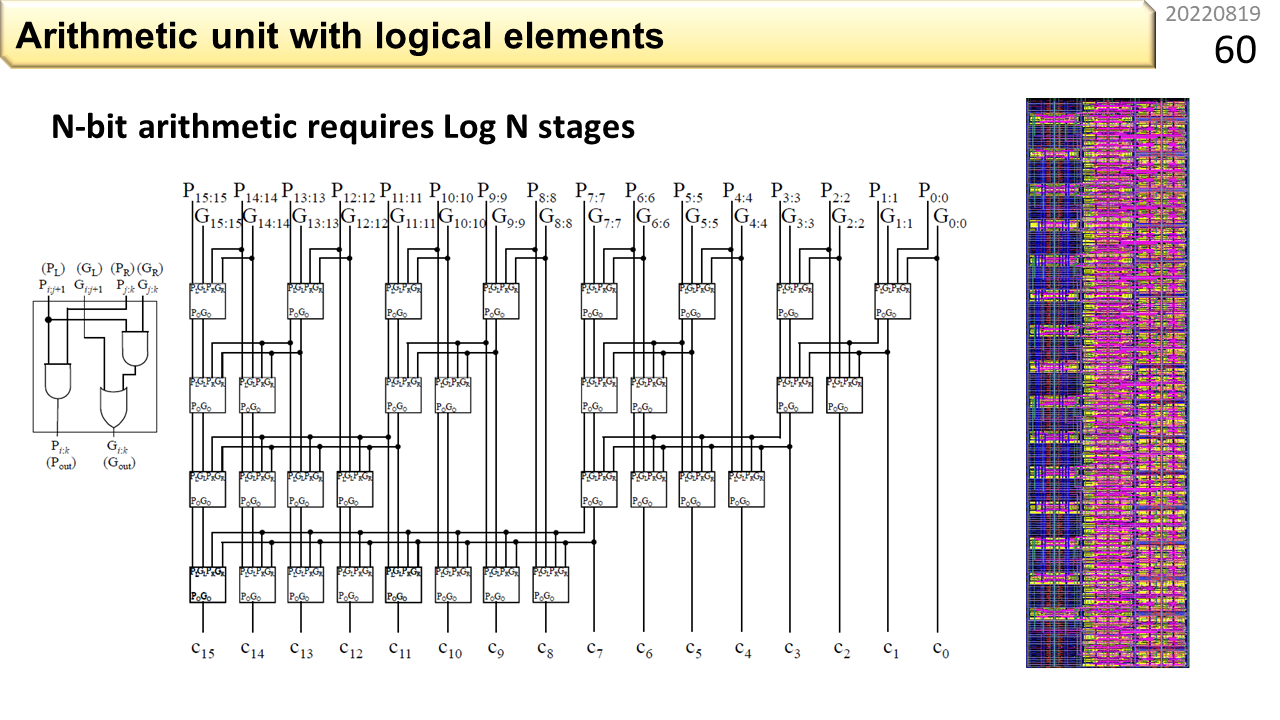
これは,16ビット固定小数点の加算に必要な,桁上げ生成回路です。論理ゲートが3つ入った四角の部品が規則的に並んでいます。さらに別の回路を組み合わせて,完全な加算器を作ることができます。32ビットや64ビットの加算には,もっと大きな回路が必要になります。

これまでの話から,みなさんは,固定小数点と浮動小数点の2種類の表現があることに気づいていますね。浮動小数点数は,符号と指数部と仮数部に分けることで,固定小数点数よりも,広範囲の数値を表現することができます。表現できる正確な数値は,このようになっています。IEEE754形式では,無限大や非数値も表現できます。非数値とは,例えば0を0で割った結果に対応します。高校生には,なんか複雑としか見えないでしょうけど,32ビットでも64ビットでも,有限の桁を無駄なく使えるように,よく考えられています。ここは大学の授業ではないので,細かい話は省略します。ノイマン型コンピュータでも,非ノイマン型コンピュータでも,正確な計算のためには,こんな複雑なデータ形式が必要なんだと思ってくれれば十分です。

では,実際にはどの程度正確に,数値を表現できるでしょうか。円周率で試してみましょう。今の高校生は,何桁まで覚えていますか。私は,3.1415926535897932までです。図の左が単精度浮動小数点数,右が倍精度浮動小数点数です。単精度の場合,3.141592までしか正確に表現できません。倍精度は64ビットもつかうんだから,覚え切れないくらいすごいだろうと思うでしょうけど,実際には,3.141592653589793までです。これ以上覚えても,コンピュータには無視されるので意味がありません。
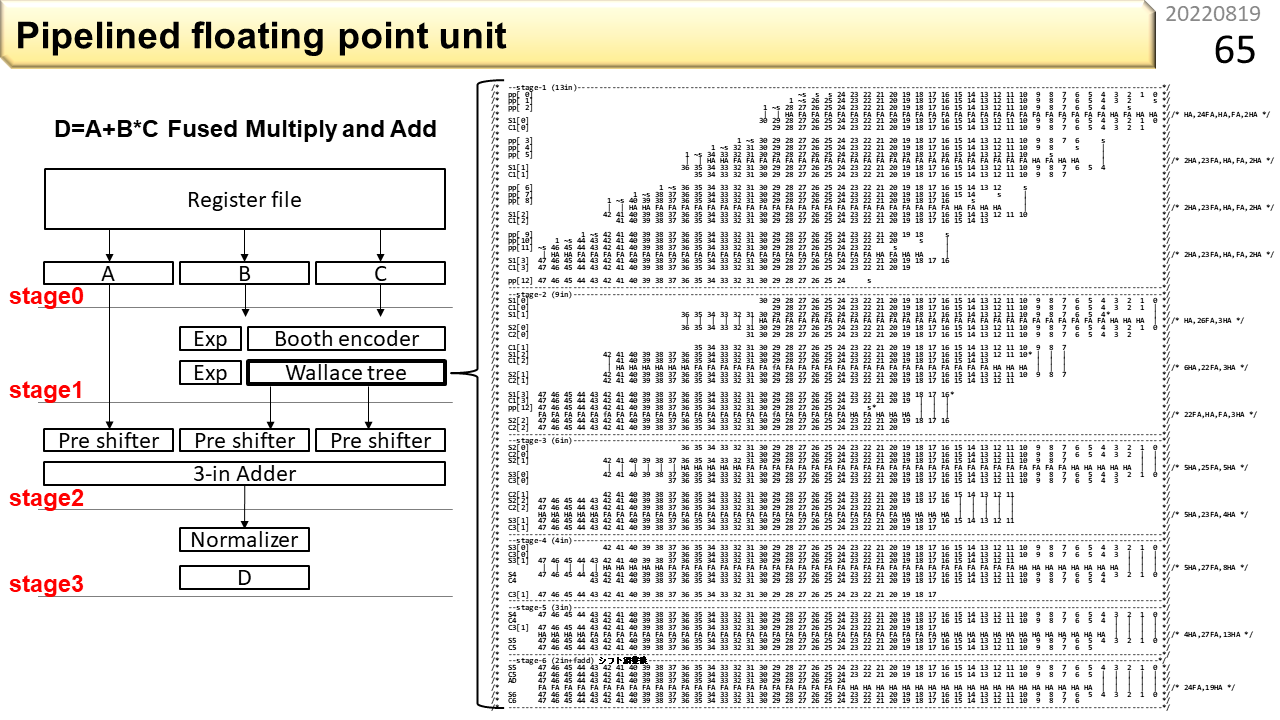
単精度浮動小数点数の精度はこの程度ですが,積和演算回路を作るとなると,数千の論理ゲートが必要です。え,コンピュータってそんな程度のものなのと思うでしょうけど,実際そうです。この図は,Wallace treeと呼ぶ,乗算器の主要部分の構造です。さらに,様々な部品を組み合わせると,ようやく,単精度浮動小数点積和演算器が1つ作れます。そして,積和演算のスループットを上げるために,前に説明したパイプライン技術を使います。例えば,計算の手順を時間方向に3分割して,速度を3倍に上げるわけです。
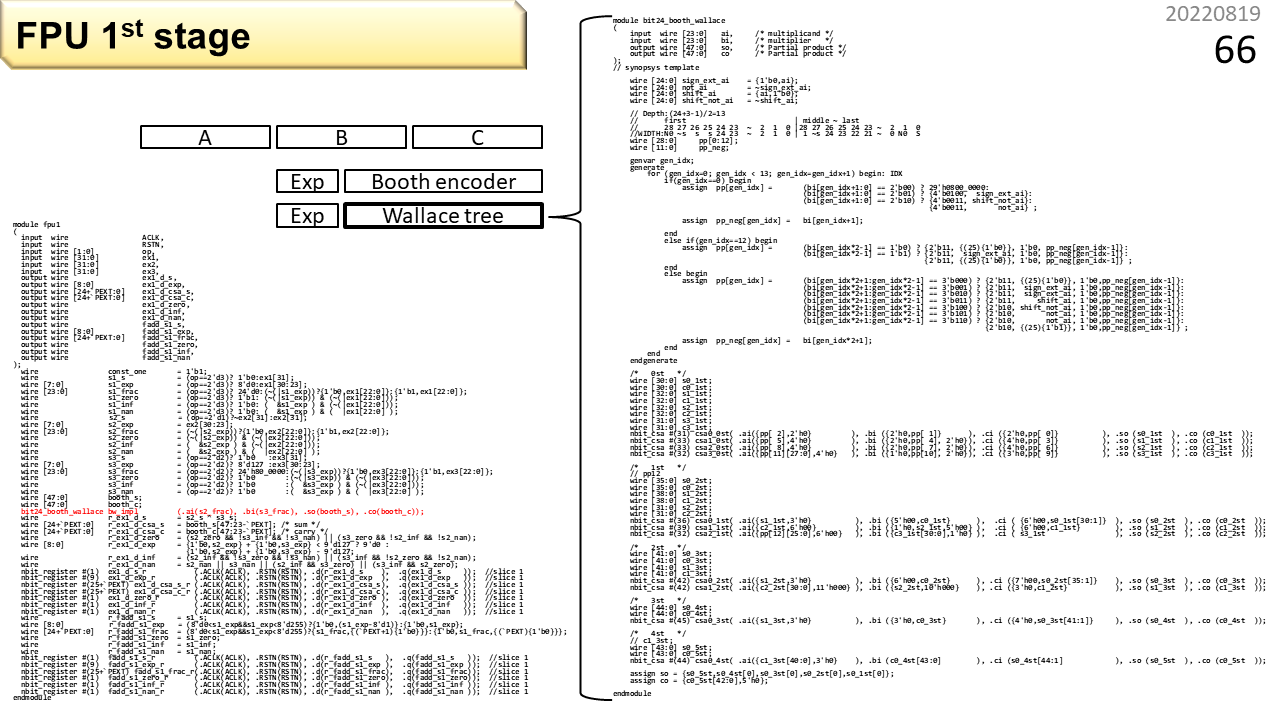
これが1段目。プログラムっぽく見えますね。これはハードウェア記述言語と呼ぶもので,ツールを使うと回路生成ができます。FPGAでも動かせるし,ASICも作れます。ハードウェア作りなんて,ちょっと勉強すれば,誰でもできるものです。すごい技術者が,すごいメーカーの秘密の工場で作っているわけではありません。
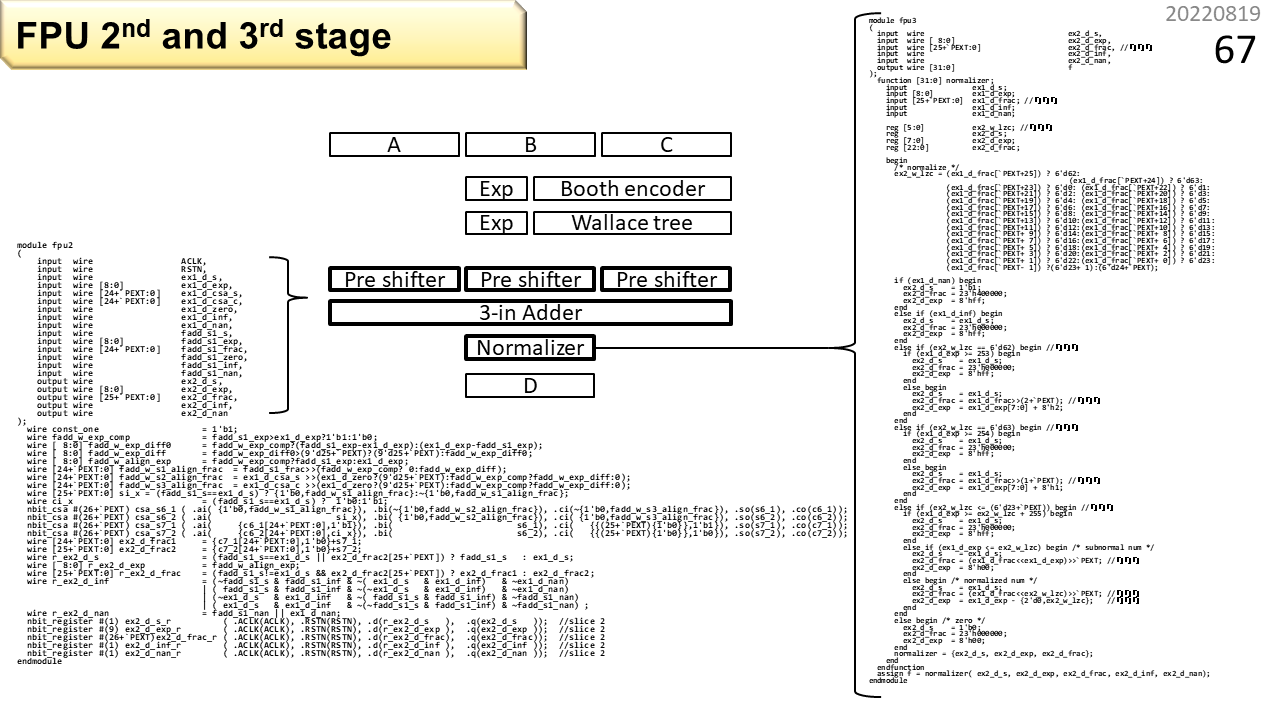
これが2段目と3段目です。
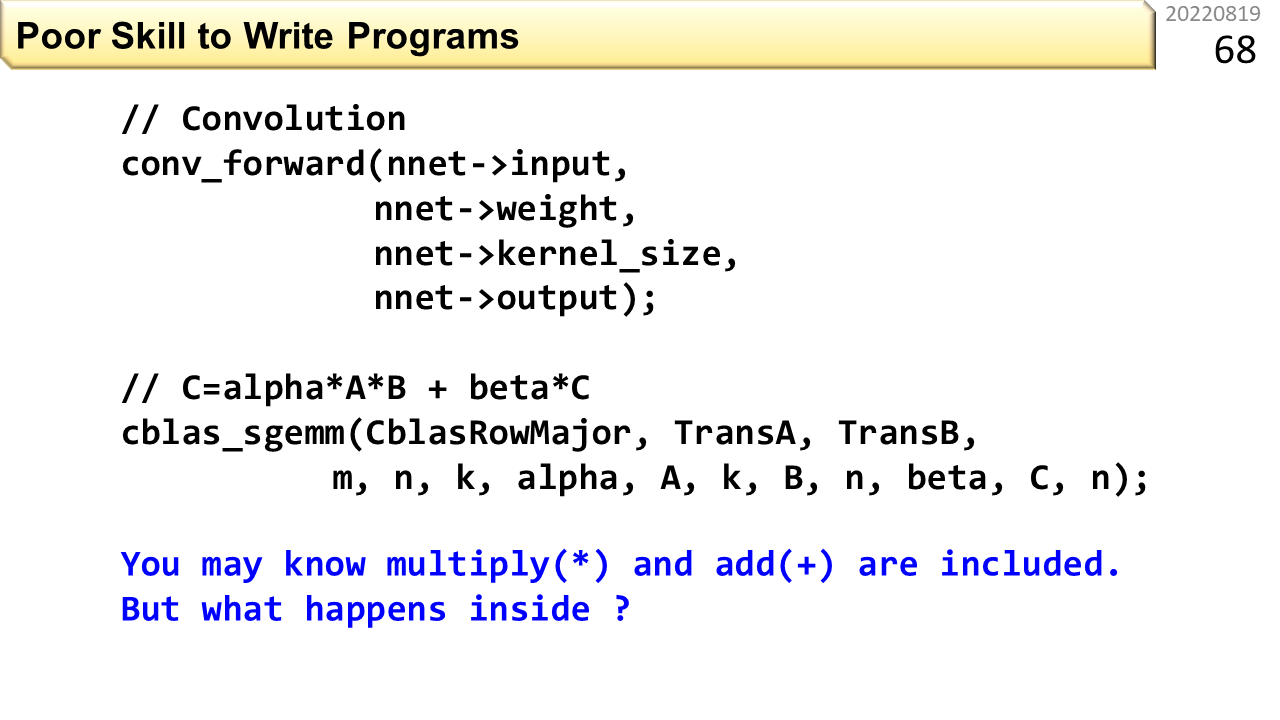
さて,ハードウェアの雰囲気がわかったとして,みなさんは,そんなことは気にも止めずに,プログラムを書きますね。どんなプログラムを書くでしょう。「AIやったことある」という高校生もいるでしょう。こんなプログラムじゃないですかね。肝の部分は,convolutionというサブルーチンを呼び出して,sgemmというサブルーチンを呼び出しておしまいです。それぞれのブラックボックスの中で,膨大な数の積和演算が実行されます。実行される場所は,CPUだったり,GPUだったり,どこで動くかは,使っているコンピュータに入っている,AIフレームワークに依存します。
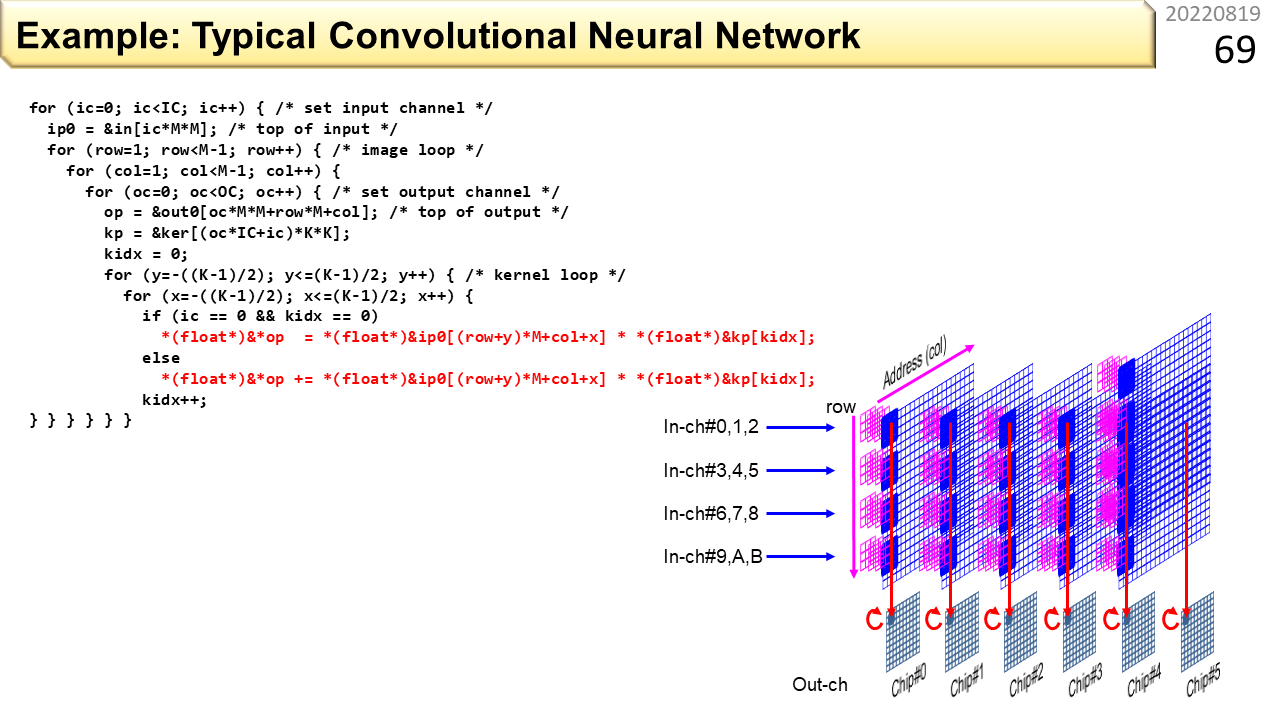
でも,真剣に温暖化抑止を考えるのであれば,ブラックボックスのまま使うのは無責任ですね。だって,どれだけ電力を使っているのかも知らずに,ただ便利だから使っているだけですから。ある日突然,コンピュータを取り上げられるかもしれませんね。一方,積和演算が見えるように,ブラックボックスに頼らずに書いたプログラムがこれです。プログラミングをしたことのある高校生なら,とても深い多重ループ構造になっていることがわかります。そして,赤字の部分が,最も実行される部分です。よく見ると,規則的に並んだデータを使って,ひたすら積和演算をしているだけのプログラムだとわかります。ここでも積和演算器が大活躍です。
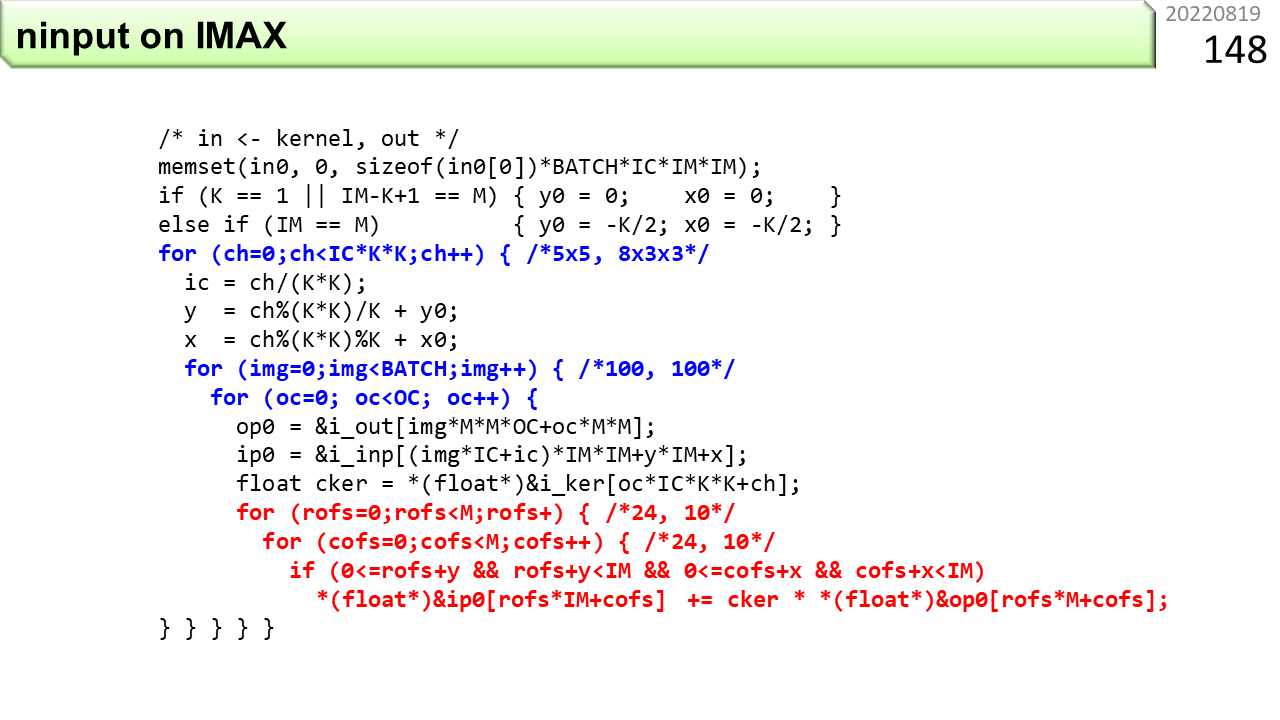
コンピュータは,規則的に並んだデータを扱うのが得意です。ただ,AIのプログラムには,特にノイマン型コンピュータにとって不都合な性質があります。300人の生徒が,修学旅行で飛行機に乗るとします。空港の出発ゲートに一列に並んで,そのまま機内に入ったとします。前半の生徒の座席番号が通路側で,後半の生徒の座席番号が窓側だったら何が起こるでしょう。先に入った生徒が通路側に座ると,あとから来た生徒が窓側に入れないので,大混乱しますね。ノイマン型コンピュータには,キャッシュメモリと呼ぶ,一時的にメモリの内容を保存して,CPUの中で高速にデータを供給する仕組みがありますが,狭いので,必要なデータが互いに追い出し合うことがあります。特に,AIのプログラムは,データが規則的に並んではいますが,必要なデータの場所がとびとびなので,追い出し合いが簡単に起こって処理速度がものすごく下がってしまいます。そこで,とびとびのデータを一旦,きれいに並べ替える作業が必要になります。余計な作業が増えますが,全体として見ると,実行時間が短くなります。ただし,1つのデータを複数の場所にコピーすることになるので,メモリの使用効率は下がります。メモリをたくさん使って,代わりに,実行時間を短くすることになります。
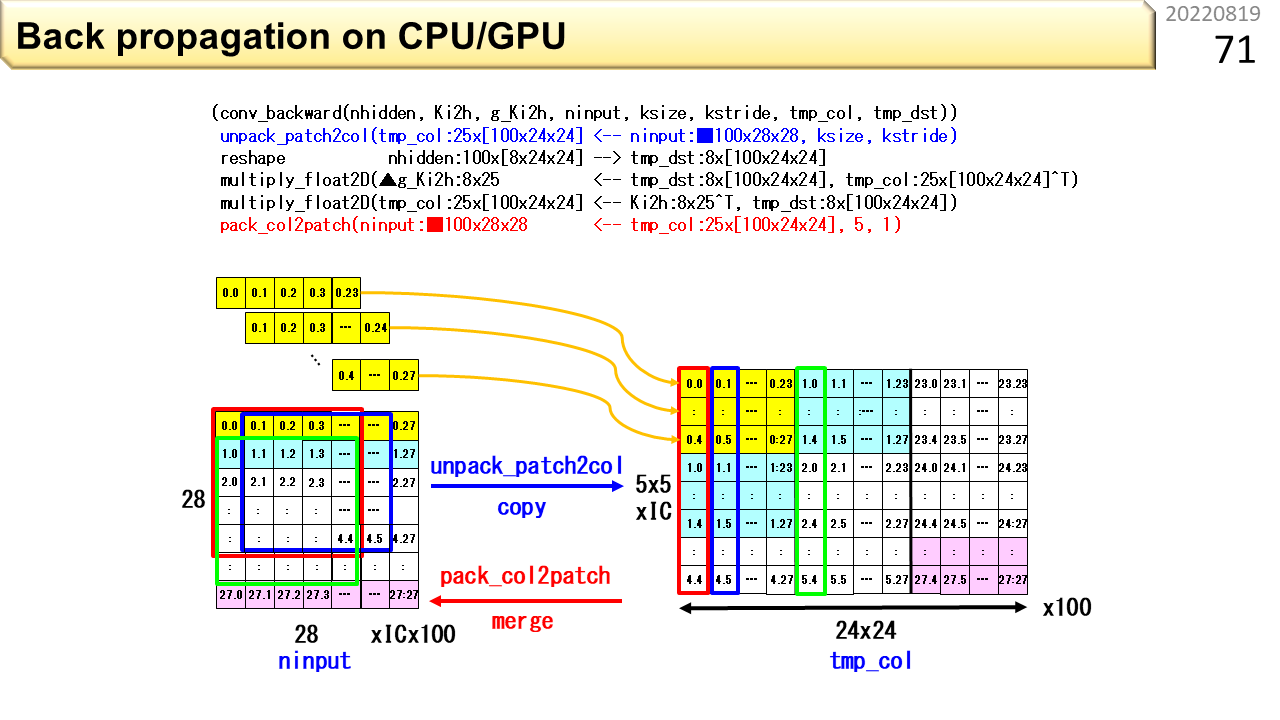
さっきの図は,あらかじめ計算しておいた重みを使って,画像識別を行う畳み込み演算でした。この図は,重みを計算で求める,バックプロパゲーションと呼ぶ計算です。ここでも,データがとびとびなので,コピーと並べ替えが必要です。コピーによるデータの増え方は,識別よりも学習のほうが激しいです。また,学習のほうが,計算時間も消費電力も圧倒的に大きいので,別の学習で作った重みを流用するなど,なるべく学習しない工夫をしたりします。
[2022/01/19]いよいよCGRA登場!でもCGRAはどこがおいしいの?
ここから,社会人も合流です。冒頭の繰り返しです。周りが使い始めたら教えてもらおうとか,未来の**コンピュータが全て解決するとか思考停止するのはやめましょう。ところで,CGRAには大きく2種類あります。FPGAを拡張したものと,CPUを拡張したものです。この記事は,後者を取り扱います。なぜって? そりゃ,前者はコンパイルに長時間かかるので,役に立たないからです。CGRAは,まだ研究レベルだし,同業者がやらないからまだ安心と,いつまでも寝ている技術者は,追い付くのに10年かかるので,もう手遅れです。

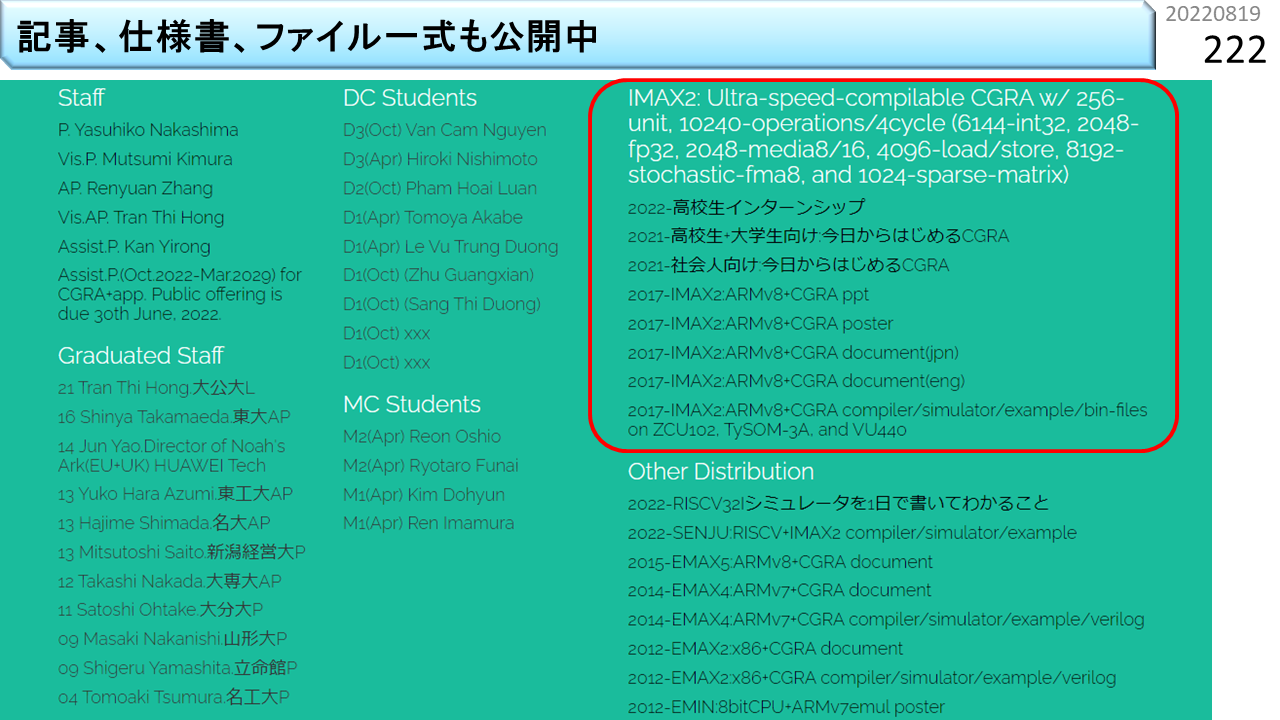
プロトタイプが各種揃っています。予算に応じてFPGAボードを買って,FPGAにIMAX2の構成ファイルをダウンロードすれば,CGRAの実機が手に入ります。ボードの値段は,上から順に,50万,150万,850万,1650万です。なお,OS調整や高速I/O実装などを含むシステム全体の開発費は15000万です。それがボードの購入費だけで手に入るのですから格安です。海外から結構な件数ダウンロードされています。現在,さらにパワーアップしたIMAX3の開発に着手しています。
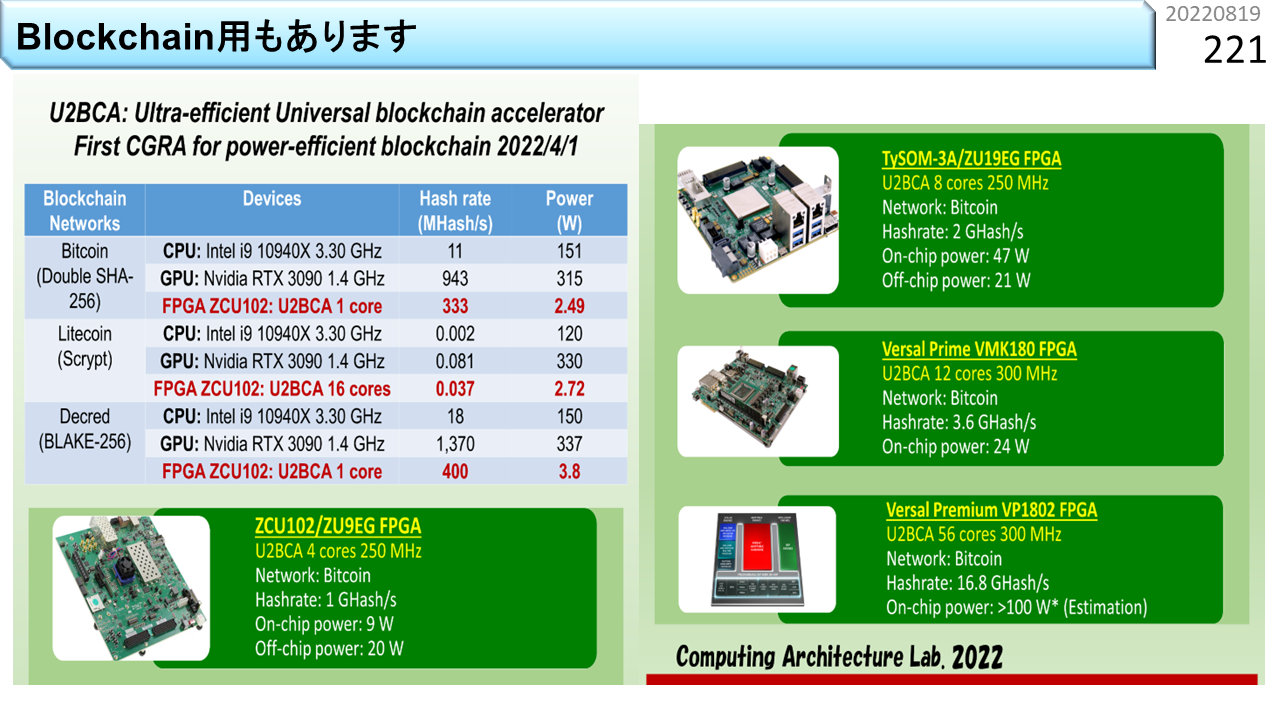
関連して,ブロックチェインアクセラレータも各種揃っています。問い合わせも来ています。
再度宣伝。うちのCGRAは,一味違います。様々な機能が高密度実装されていて,かつ,コンパイル速度が速いので,JITコンパイルも可能です。

6つ目は,いよいよCGRAです。浮動小数点積和演算器を使いますが,ノイマン型とは,考え方を含めて,いろいろ違います。
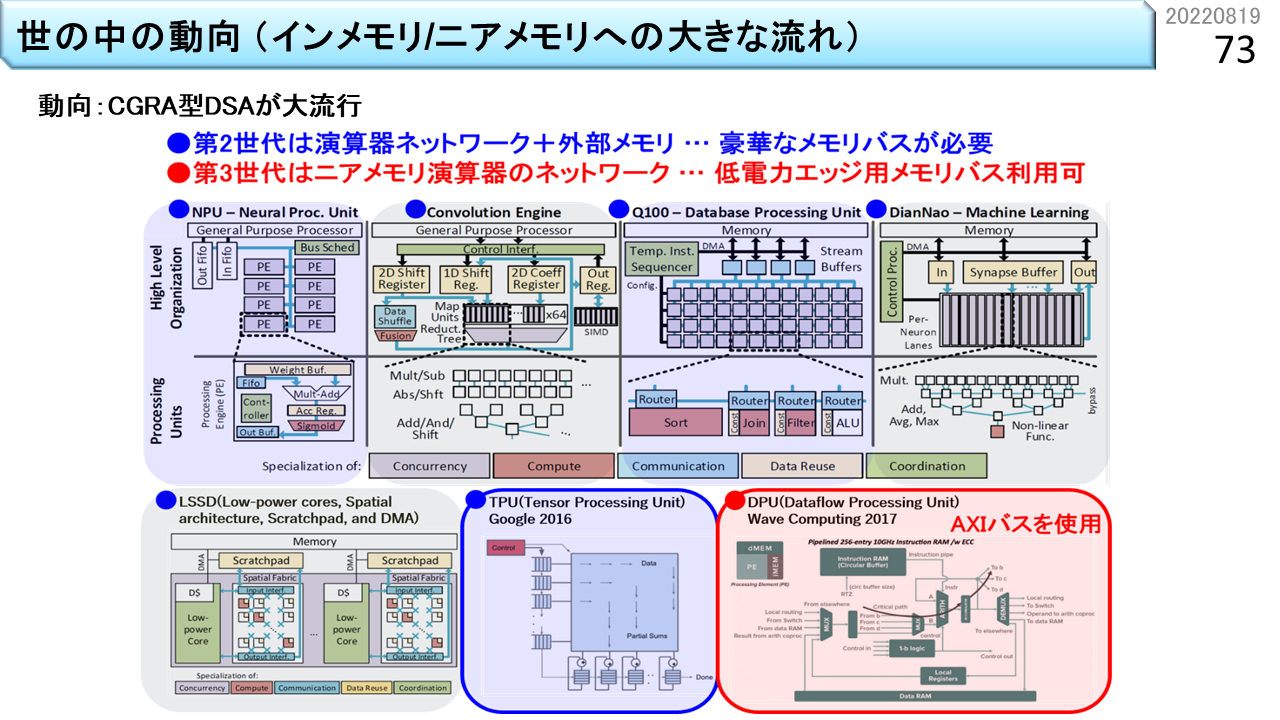
CGRAの歴史はシストリックアレイに遡ります。でも,最初は絵に描いた餅で,多くの回路を規則的に並べる手段がありませんでした。半導体の集積度が低かったので,1つのLSIパッケージにCPUを1つ実装するのが精一杯でした。1つのパッケージに複数のCPUを実装できるようになったのは1990年代からです。多くの演算器を並べて実用的なCGRAを作れるようになったのは2000年代からですね。つい最近のことです。そもそも,CGRAは使う人が好きに設計するので,使う人の数だけ種類があります。国内でも相当数のメーカーが独自CGRAを開発していました。でも,当時は,キラーアプリがなかったんですね。キラーアプリというのは,そのハードウェアと組み合わせることで,無敵の力を発揮するプログラムのことです。とにかく,国内のCGRAは,ほぼ消滅して,今では見る影もありません。ところが,その後,AIが注目を浴びるようになって,AIとシストリックアレイを組合せたのが,2016年にGoogleが発表したTPUです。これで,シストリックアレイの知名度が一気に上がりました。そして,2017年には,ほとんど名前が知られていなかったWavecomputing社がCGRAを発表しました。これで,CGRAを実用的にするための雛型が世の中に知られるようになりました。未だに,様々なアイデアが乱立していますが,演算器とメモリを組にして,たくさん繋ぎ合わせる構成が,標準になってきました。
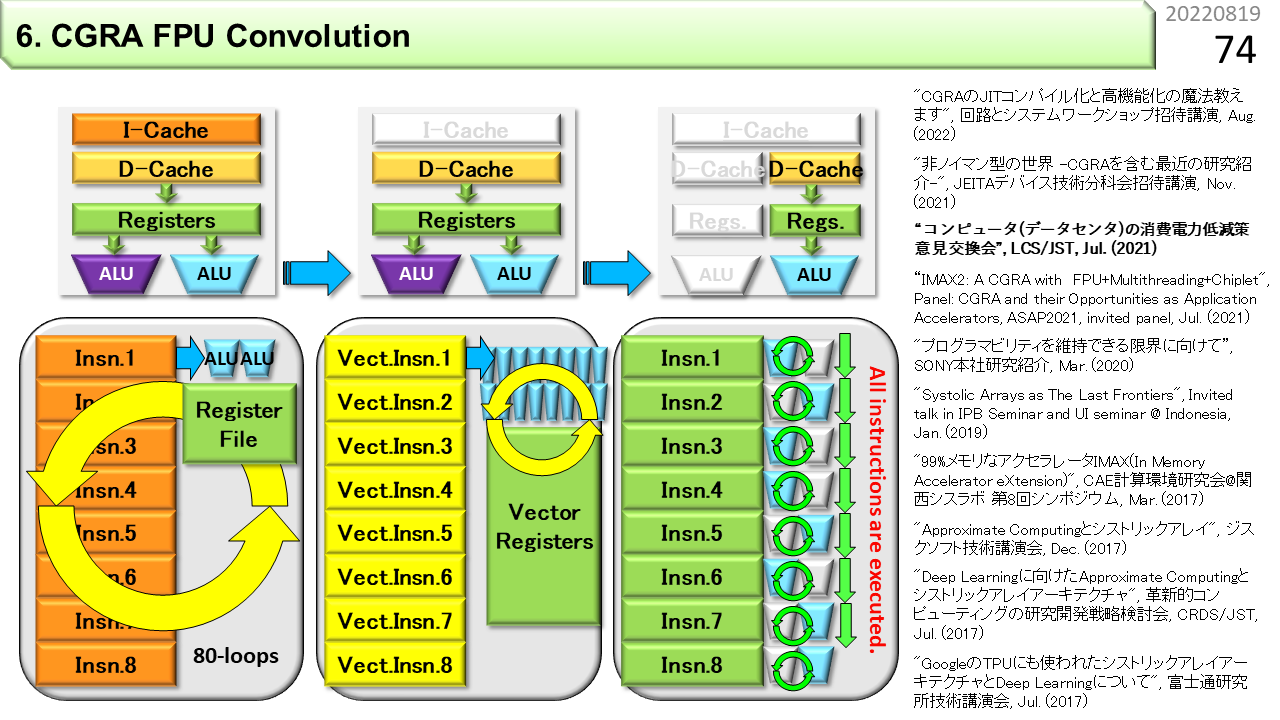
CPUとSIMDとCGRAがプログラムを実行する様子を比べてみましょう。左から順に,CPU,SIMD,CGRAです。CPUは機械語命令を順に実行します。SIMDも同じです。ただし,1つの機械語命令が多くのデータを処理できます。ここまでがノイマン型です。一方,CGRAは,機械語命令レベルの機能をたくさんのALUにセットした後に,データを流し込みます。1つのデータ流に対して様々な演算を行うことができます。1つのALUに着目すると,連続して投入されるデータに対して同じ演算を行います。CGRAは非ノイマン型です。
プログラムの視点から見てみましょう.CPUの場合,ループのイタレーションに従って,機械語命令を順に実行します.スーパスカラやVLIWは,複数の機械語命令を同時に実行しますが,基本的には,距離が近い命令が同時実行の対象です.
ベクトルは,複数のイタレーションの,同じ位置にある機械語命令をまとめて実行するモデルです.ベクトル長を長くできるベクトルプロセッサでは,ループ構造そのものをなくすことができます.ところで,ベクトル長が256程度しかないものをベクトルプロセッサと呼ぶ人がいますが,そもそもベクトルプロセッサは,16要素を一度に演算できたりするので,256要素程度のベクトル演算は,たった16サイクルで終ってしまいます.主記憶遅延が数百サイクルもある時代に,16サイクルで終ってしまうベクトル演算は,せいぜいキャッシュメモリを相手にするしか出番がありません.キャッシュメモリに入ってしまうようなオモチャのアプリを相手にしても,未来はありません.ベクトル長を長くできないベクトルプロセサには,存在価値がありません.
一方、CGRAは、レジスタや演算器がたくさん並んでいて、ループ構造の中の機械語命令をそのまま貼り付けることができます。CGRAの動きは、CPUとも、ベクトルとも違っていて、イタレーション間をパイプライン動作します。CPUは、イタレーションの中でパイプライン動作するので、命令間に依存関係があると、スーパスカラやVLIWの効率が低下します。しかし、CGRAは、命令間に依存関係があってもパイプラインが止まることはありません。同様に、ベクトルは、複数イタレーションを同時実行する際に、連続データの先頭主記憶アドレスをベクトルレジスタの先頭に合わせる、アライメント機構が必要になります。しかし、CGRAは、複数イタレーションをパイプライン実行するので、複雑なアライメント機構を必要としません。CGRAの欠点は、ループ構造の中の機械語命令が、一度に写像可能な数を超えると、分割が必要になることです。しかし、CISCのような高機能機械語命令を採用し、さらに、位置制約をなくしたリング構造とすることで、欠点を克服することができます。
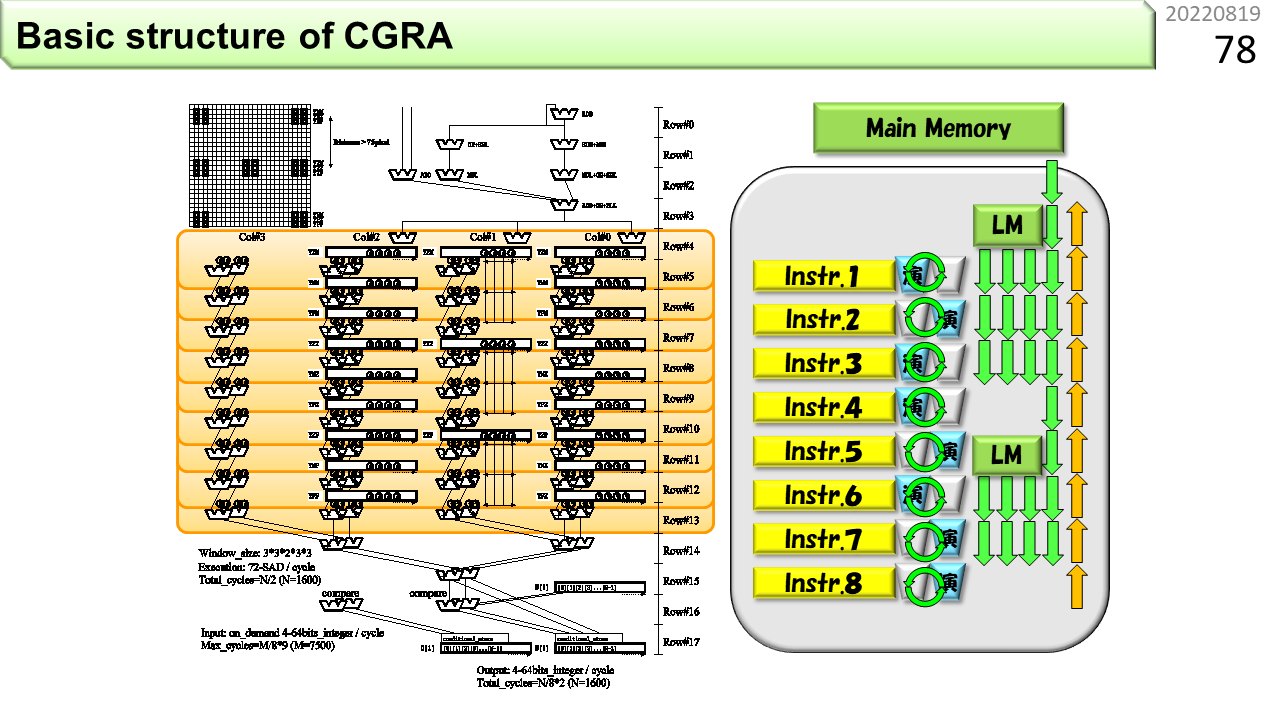
もう少し,CGRAを詳細化しましょう。図の左側では,山形のALUと長方形のメモリが組になっています。重みのように繰り返し使うデータは,ALUのすぐ側に格納しておくと,データを遠くから届けずに済みます。データの移動を最小限にすることが,消費エネルギーの節約に貢献します。
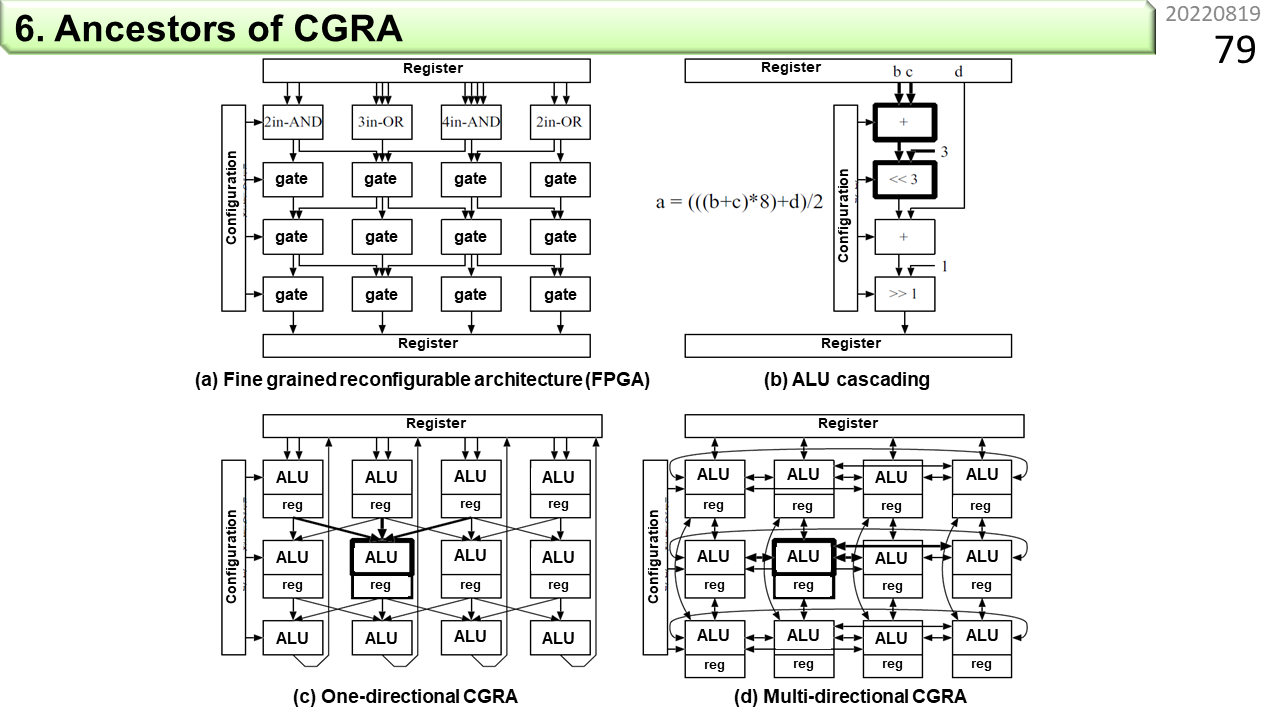
CGRAの祖先をいくつか見てみましょう。(a)は前に説明したFPGAです。(b)はノイマン型の演算器を多段構成にしたALUカスケーディングです。通常のALUは,1つの結果をレジスタに格納します。一方,カスケーディングは,引続き次のALUに結果を送って,別の計算に使ってもらう仕組みです。この考え方を多くのALUに適用することが,CGRAの設計思想の1つと言えます。(c)は初期のCGRAの構成です。ALUを基本構成要素として,データを上から下に1方向に流します。(d)は上下左右に流すことができる構成です。初期のCGRAでは,たくさんのALUが格子状に接続されて,全体が協調して動作します。
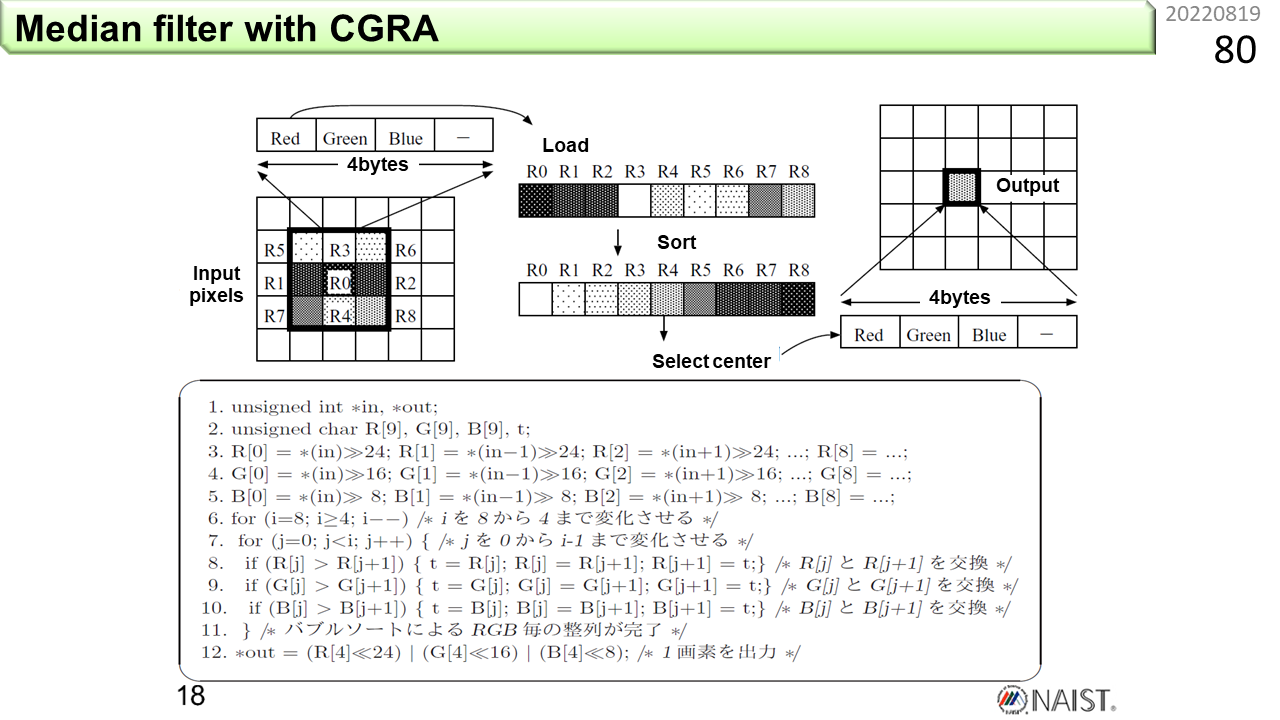
では,どうやってプログラムするのでしょう。まず,ノイマン型コンピュータを使った,メディアンフィルタと呼ぶ画像処理プログラムの例を示します。C言語で書いてあります。メディアンフィルタは,3x3の領域の色成分(赤・緑・青)を明るさ順に並べて,中央の値を計算結果とすることで,輪郭をぼかすことなく,色だけをぼかすことができる便利な画像フィルタです。ただし,明るさ順に並び替える作業が必要です。3x3の領域から9個の画素値を取り出します。そして,各々8ビットの色成分ごとに比較をして,並べ替えていきます。並べ替えには,わかりやすいバブルソートを使っています。隣どうしを比べて,逆順なら入れ換えることを繰り返すだけです。クイックソートのように,より高速なアルゴリズムもありますが,要素数が9しかないし,まん中の値が求まった時点で,残りを打ち切ることができるので,これで十分です。6行目と7行目に2重ループがありますね。ループの中の比較と入れ換え処理が8,9,10行目です。この3行が,合計8+7+6+5+4=30回繰り返されます。これでようやく1つの出力画素が求まるので,全体ではかなりの計算量になります。

次がCGRAの場合です。前の例では,2重ループを使って並べ替えていました。でも,CGRAの構成図を見ると,データが1方向に流れるように変形する必要がありそうです。そこで,8ビット単位に大小比較をして,指定した順番の値を出力する5つの基本操作を新たに定義します。max3(A,B,C)は,3つの画素値(各々4バイト)を入力とし,3つの赤成分(8ビット)から最大値,3つの緑成分(8ビット)から最大値,3つの青成分(8ビット)から最大値を選択して出力する操作です。同様に,mid3(A,B,C)は中間値,min3(A,B,C)は最小値を出力します。max2(A,B,C)とmin2(A,B,C)は,2つの画素値を入力とし,Cは無視します。これらを使うと,2重ループを使わずに済みます。プログラムでは,3行目で,9個の画素値をr0からr8に取り出しています。4,5,6行目が図(a)に対応しています。まず,縦に3画素ずつまとめます。r5とr1とr7をmax3,mid3,min3に与えると,最大値,中間値,最小値が計算できます。これを改めてr5とr1とr7に代入すると,3つの画素の並べ替えが完了です。同様に,r3とr0とr4も並べ替えます。さらに,r6とr2とr8を並べ替えます。これで,9個の画素値を図(a)の関係に並べ替えることができました。次は,横に3画素ずつまとめます。r5とr3とr6をmax3,mid3,min3に与えて並べ替えます。同様にr1とr0とr2,r7とr4とr8を並べ替えます。結果,図(b)の関係に並べ替えができました。さて,この時点で何がわかるでしょうか。(a)の時点で,上の3つの画素値は,各々のグループで最大です。そして,下の3つの画素値は,各々のグループで最小です。(b)では,3つの最大値の中の最大値,つまり全体の中での最大値が右上角に移動します。同様に,3つの最小値の中の最小値,つまり全体の中での最小値が左下角に移動します。最後に欲しいのは,全体の中の中間値なので,右上角と左下角の値は捨てることができます。以上を繰り返すと,最大値と最小値が順に捨てられて,最後の(g)に到達します。画素値が3つだけ残っているので,18行目でmid3を実行して,中間値r0を取り出します。この方法を考えたのが2008年,本にしたのが2012年。まさに光陰矢の如しです。
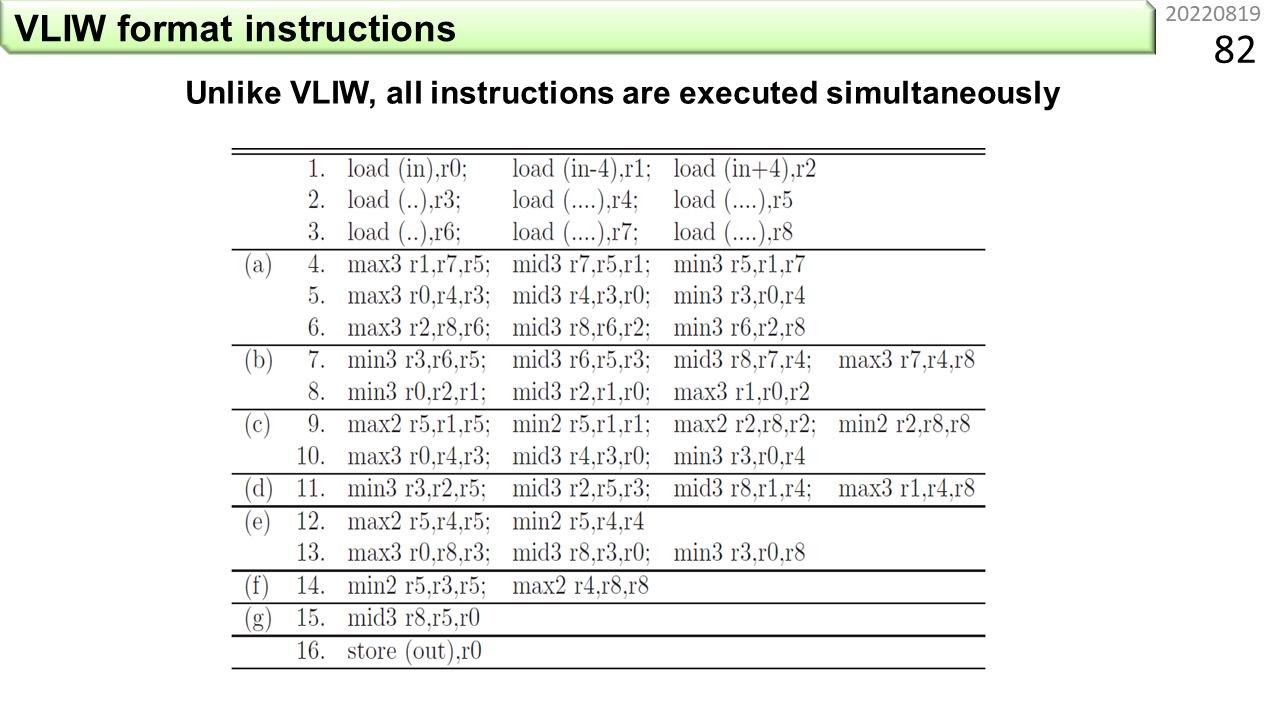
この図は,さっきのプログラムを機械語命令に書き換えて並べたものです。max,mid,minは,3入力演算器を使って1命令で実行できるとします。(a)〜(g)は,前の図の各状態に対応しています。ループ構造がなくなって,データが上から下に流れるように,機械語命令が並んでいますね。この機械語命令列は,横1列を1つのVLIWにまとめることができます。ということは,1つの出力画素が,わずか16命令で求まることになります。そして,CGRAの場合,全ての機械語命令が,2次元構造に配置された多数のALUに一度にセットされます。上から水のようにデータを流し込むと,下から,途切れることなく出力画素が生成されます。つまり,VLIWの16倍速になりました。元々のノイマン型コンピュータのプログラムからは想像もつかない速度です。高校生の時に,水トランジスタが気になったと言いましたが,ここに至って,水に戻ってきたわけです。高校生の時に気になったことには,ずっと影響を受け続けるのかもしれません。
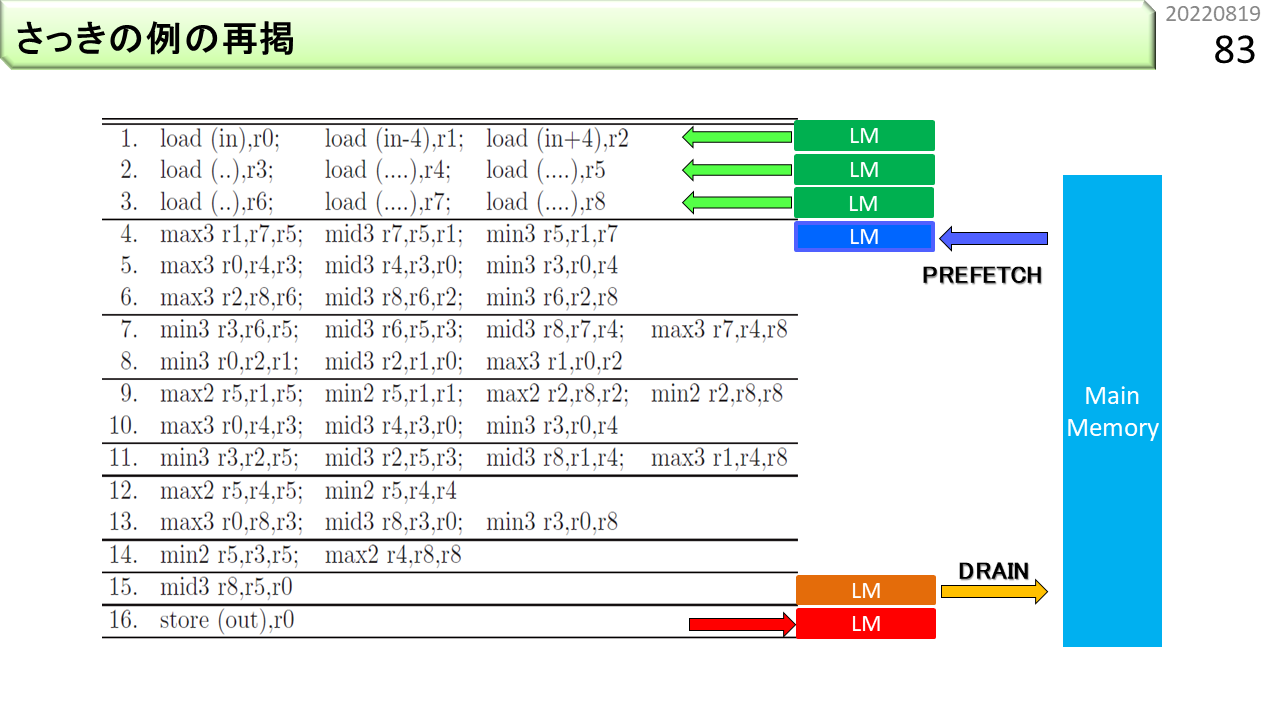
さらに,1から3行目の命令に入力データを供給するメモリを接続します。16行目の命令には演算結果を格納するメモリを接続します。
このビデオは,ハードウェアと同じ動きをするCGRAシミュレータが動作する様子です。画面が小さい場合は,ブラウザの幅を狭くすると,逆に大きくなるはずです。再生ボタンを押してみましょう。最初,画面の上のほうで,ちらちら色が変わります。CGRA起動準備のためにVLIWが動いている状態です。一瞬,水色の部分が更新されます。ハードウェアがVLIWをCGRAにセットした瞬間です。そして,紫色のデータが上から絶えまなく流れ落ちてきます。CGRAが動作している状態です。新しいコンピュータを作る時には,まず,仕様書を書きます。どういう思想のコンピュータなのか,機械語命令はどうするのかなど,他の開発者にも理解してもらえる文書を書きます。そして,仕様書を見ながら,プログラミング言語を使って,ハードウェアそっくりに動くシミュレータを作ります。回路設計だけがコンピュータ開発ではありません。シミュレータを使って,仕様書が間違っていないか,また,思った通りに動くかどうかを確認します。ここはとても大事なポイントです。人が作るものには,必ず間違いがあります。検証する手段を何重にも用意しておかなければ,いつまでたってもまともに動くコンピュータができません。全く新しいコンピュータであれば,コンパイラやライブラリといった,プログラミングに必要な開発環境も全て自分で作らなければなりません。VPPも,OROCHIも,LAPPも,実際にそうやって作りました。
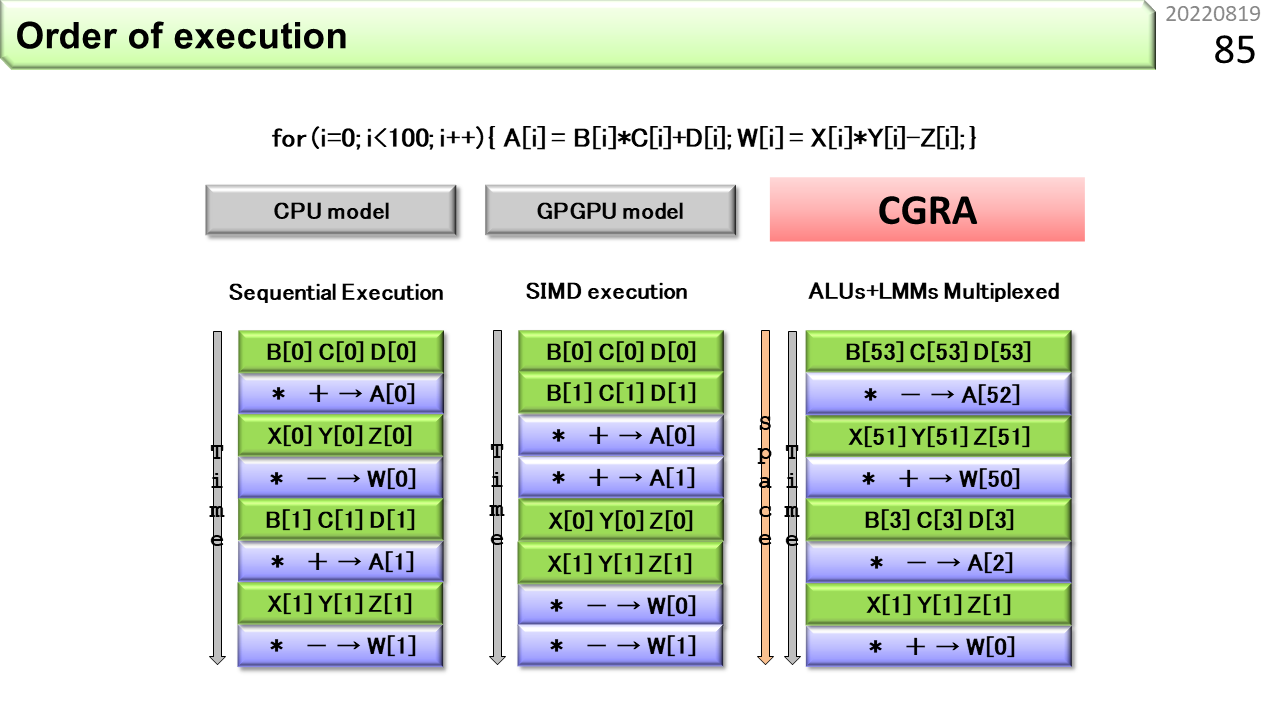
これは,計算の順序を示しています。左はCPU,中央はGPGPUです。上から下に向かって,時間順にデータが処理されていく様子を示しています。一方,右はCGRAです。縦は時間順であると同時に,空間的位置も示していて,ある瞬間のスナップショットになっています。先行する計算は下のほうに進んでいて,後続の計算が上から入っていきます。ある一つのデータに注目すると,正しく上から順に処理されていきますが,次のデータが即座に投入されるので,スナップショットをとると,様々なデータが,異なる場所で同時に処理されている様子がわかります。
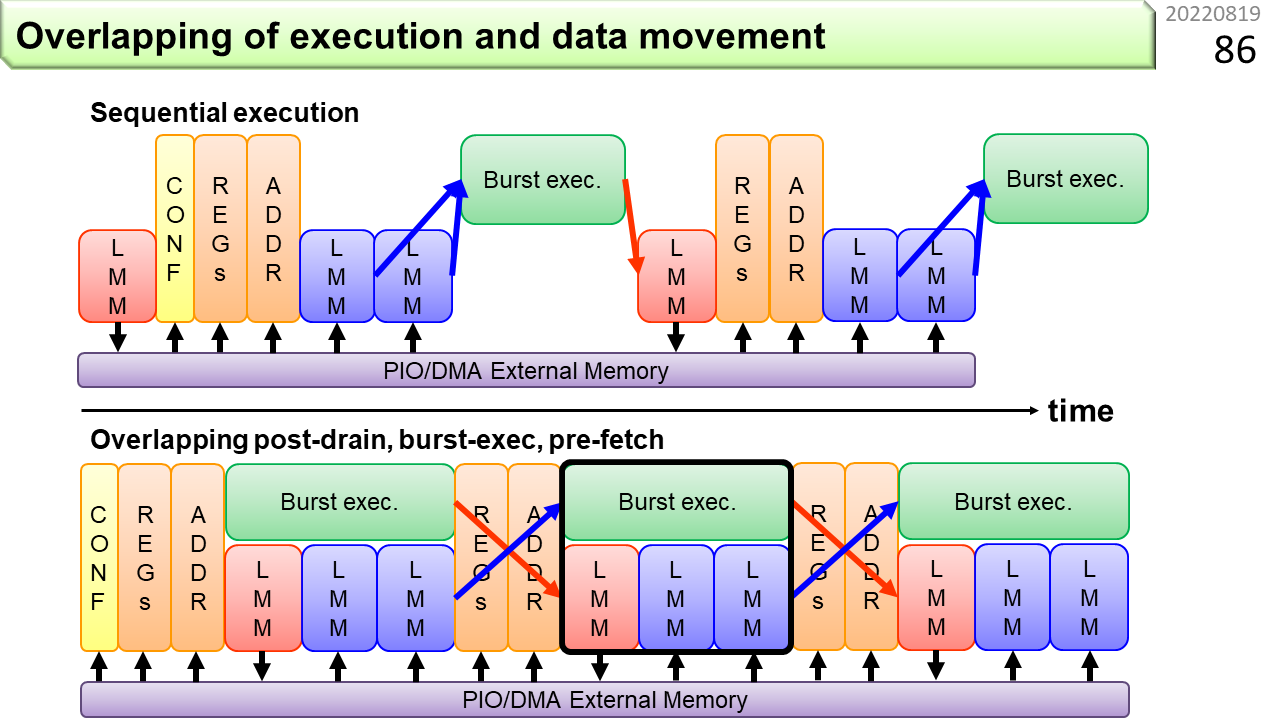
さらに,計算と同時に,空いているメモリに次の計算に必要なデータを供給したり,前回の計算結果が格納されたメモリからデータを取り出すこともできます。
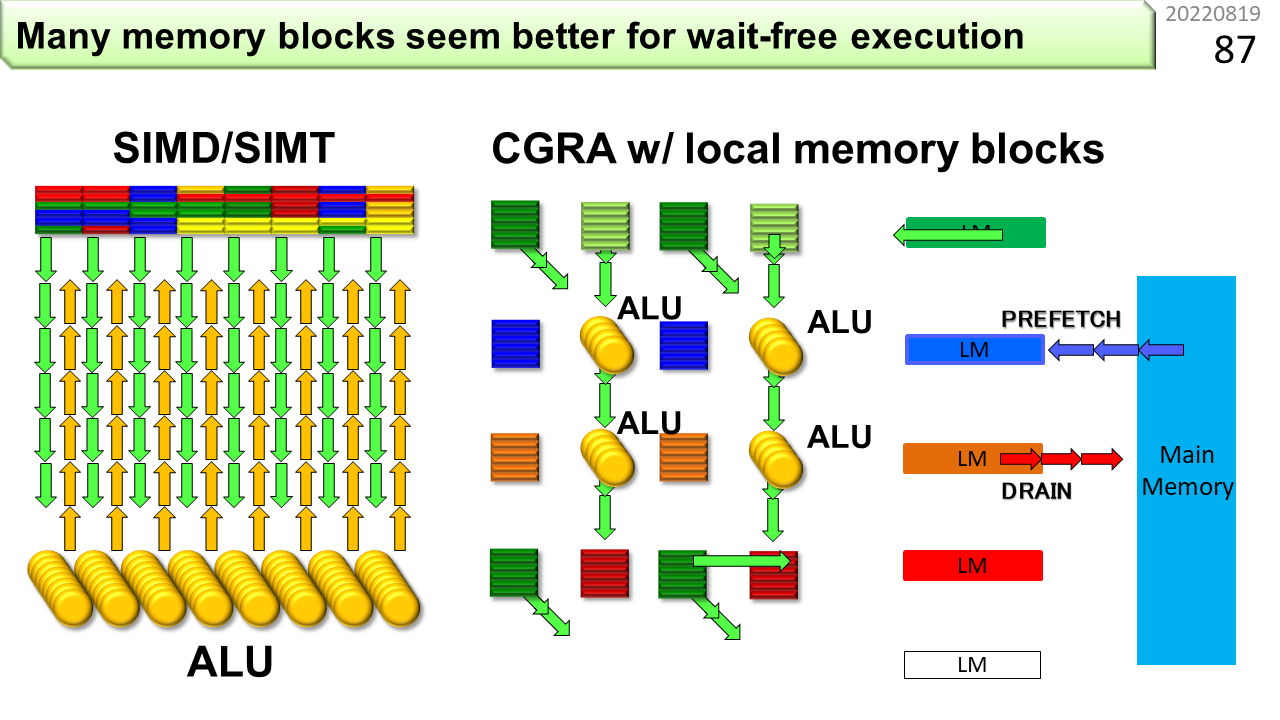
左がGPUやSIMD,右がCGRAです。そして,●がALU,■がメモリです。CGRAでは,ALUの側にメモリを配置し,計算に必要なデータを近くのメモリから供給することで消費電力を下げます。
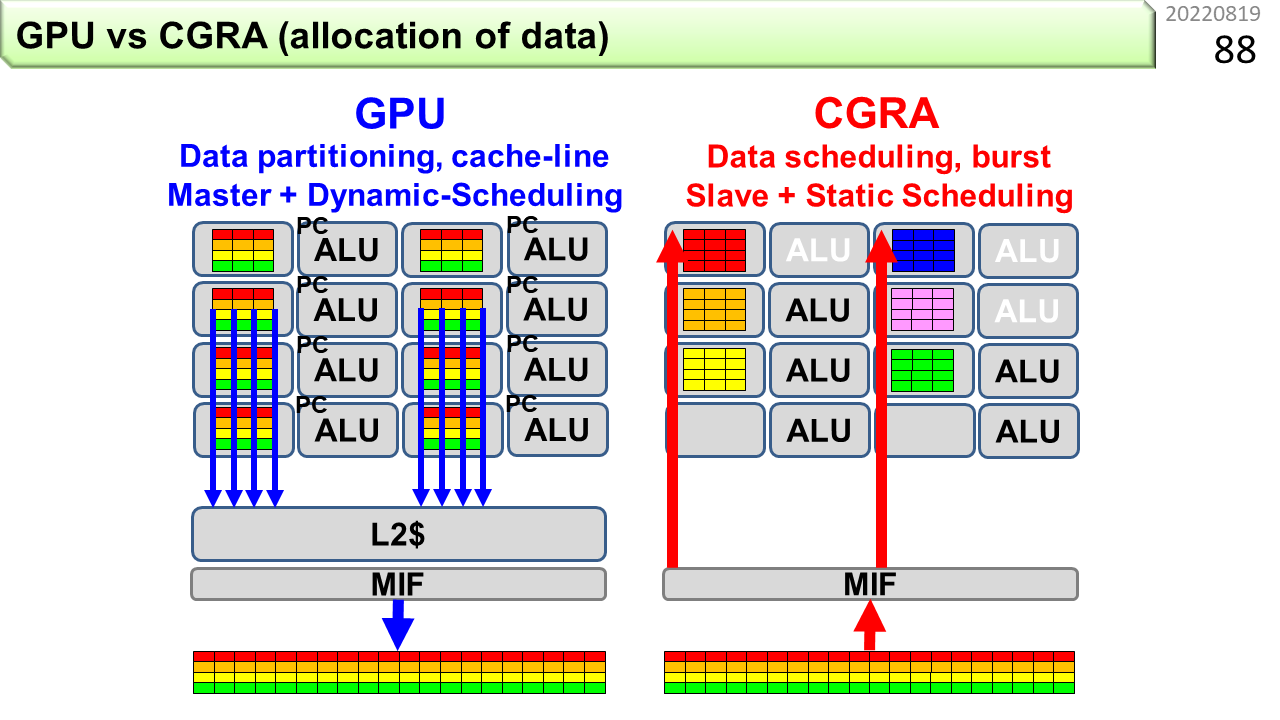
データの配置の観点から,GPUとCGRAを比べてみましょう。GPUはSIMDのように動作しますが,実際には,大量のノイマン型コンピュータが搭載されていて,それぞれが機械語命令を実行します。D=A+BxCといった積和演算のためには,A,B,C,Dの全てがALUに揃っている必要があります。一方,CGRAでは,ALUは自身に必要なデータを近くのメモリから取り出すだけで良く,1つのメモリに全部詰め込む必要がありません。このため,以前,飛行機の座席を例に説明した,データの追い出し合いが起こり難い利点があります。また,GPUと違って,CGRAの各ユニットは,自ら主記憶までデータを取りに行くことはしません。各ユニットは外部からデータが一斉に届けられるのを待つことで,メモリからの一斉送信を整然と受け取ることができ,主記憶動作を減らすことができます。さらに,あらかじめ,データ転送の順番を決めておくことができ,お互いに邪魔することもないので,高速かつ性能予測が簡単です。

さて,はじめのほうで,CGRAはオーダーメイドのコンピュータと言いました。標準品というのがないんですね。だから,自分で作るしかありません。でもLSIを作るのには相当のお金がかかるので,何度も作り直すことができません,もちろん,CGRAは小さいので,企業なら作り直しができるでしょう。でも,大学は貧乏なので簡単には改良できません。そこでFPGAの出番です。あれれ? FPGAは細粒度で,CGRAは粗粒度といったじゃないかと思ってますよね。もちろんそうです。プログラマにとって,FPGAは,高位合成を使って,プログラムをハードウェア化するための道具です。でも,元々は,書き換え可能なハードウェアの仕組みであって,あらゆるコンピュータのプロトタイプとしても使うことができます。動作周波数はLSIの数分の1しかありませんが,いろいろ実験して仕組みを評価するには便利な道具です。この写真は,CGRAをFPGA上に実装して,実際に使えるようにしたシステムです。リング構造が2つ重なっている図がありましたね。このシステムには,4基の★CGRAが入っています。つまり,リング構造が4つです。あとで詳しく説明しますが,1つのCGRAに,★SIMD型★パイプラインALUとメモリブロックの組(物理ユニットと呼びます)が64組入っています。1つのALUでは最大6命令を同時実行でき,メモリブロックでは最大4つのデータを読み書きできる,★VLIWとして使えます。さらに,★マルチスレッディングにより,1つの物理ユニットが,4つの論理ユニットに相当する機能を持っています。つまり,1つのCGRAに対して,(6+4)x4x64=2560命令に相当する機能を一度にセットできます。CGRAが4基あるので,合計,10240命令に相当する機能を一度にセットできることになります。かなり大規模な実験ができますね。ところで,ページ番号14に,○が並んだ表がありましたね。★の数は,左端のIMAXについている○の数と同じです。つまり,この写真がIMAXです。パイプライン,SIMD,VLIW,マルチスレッディング,そして,シストリックアレイの全部が入っています。これ,いくらするんでしょうね。ひみつです。😀
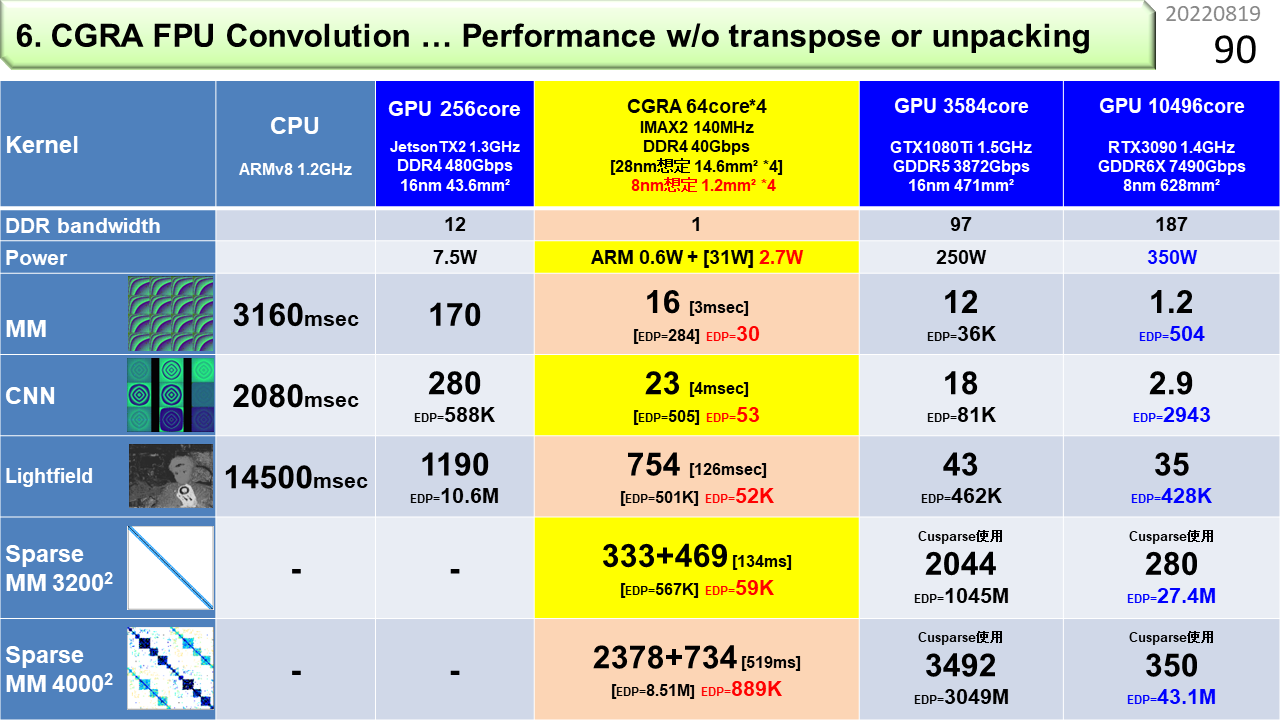
FPGA上に実装したIMAXを使って,性能を測定してみたのがこの表です。左から順に,CPU(1.2GHz),小型GPU(1.3GHz:メモリ性能480Gbps),IMAX(140MHz:メモリ性能30Gbps),大型GPU(1.6GHz:メモリ性能3872Gbps)です。IMAXはFPGAに実装しているので,動作周波数は他の6分の1以下です。また,メモリ性能も小型GPUの1/16,大型GPUの1/130しかありません。縦には5種類のプログラムが並んでいて,順に,転置を使わない行列積,畳み込み,距離画像生成,疎行列積です。転置を使わないのはメモリ節約のためです。距離画像というのは,2台のカメラ映像から得られる視差を使って,物体までの距離を画像にしたものです。表の値は実行時間です。どうです。周波数もメモリ性能も桁違いに最低なのに,小型GPUよりも高速で,大型GPUにも肉薄しています。さらに,IMAXをLSI化できたら,面積は大型GPUの1/100,周波数とメモリ性能ともに6倍になると見積もっています。わくわくしますね。面積が小さければ,消費電力も小さいので,温暖化抑止に貢献できそうですね。
CGRAというと、まず演算器だけ並べてしまうひとがいますが、コンパイルに必要なデータパス探索にとても時間がかかってしまい、コンピュータとして役に立たなくなります。
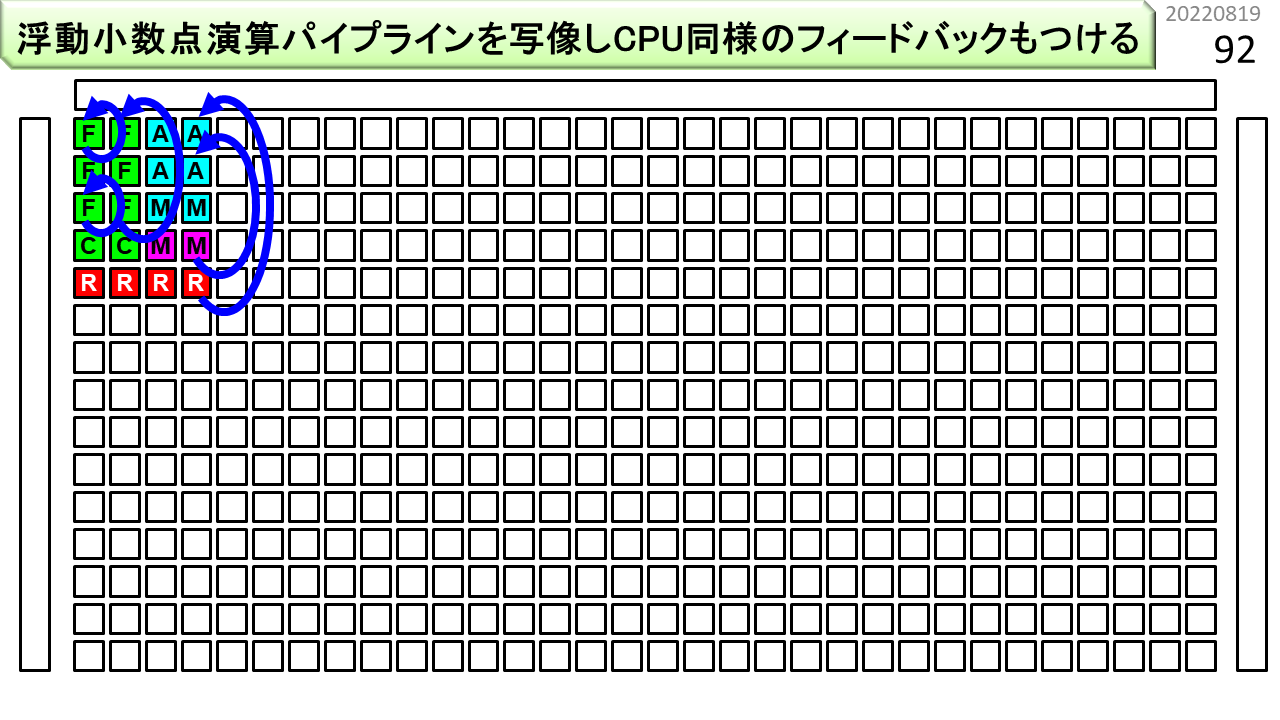
そこで,まず,このように,CPUの構造を基本部品とすることで、複雑さのオーダーを下げることができます。
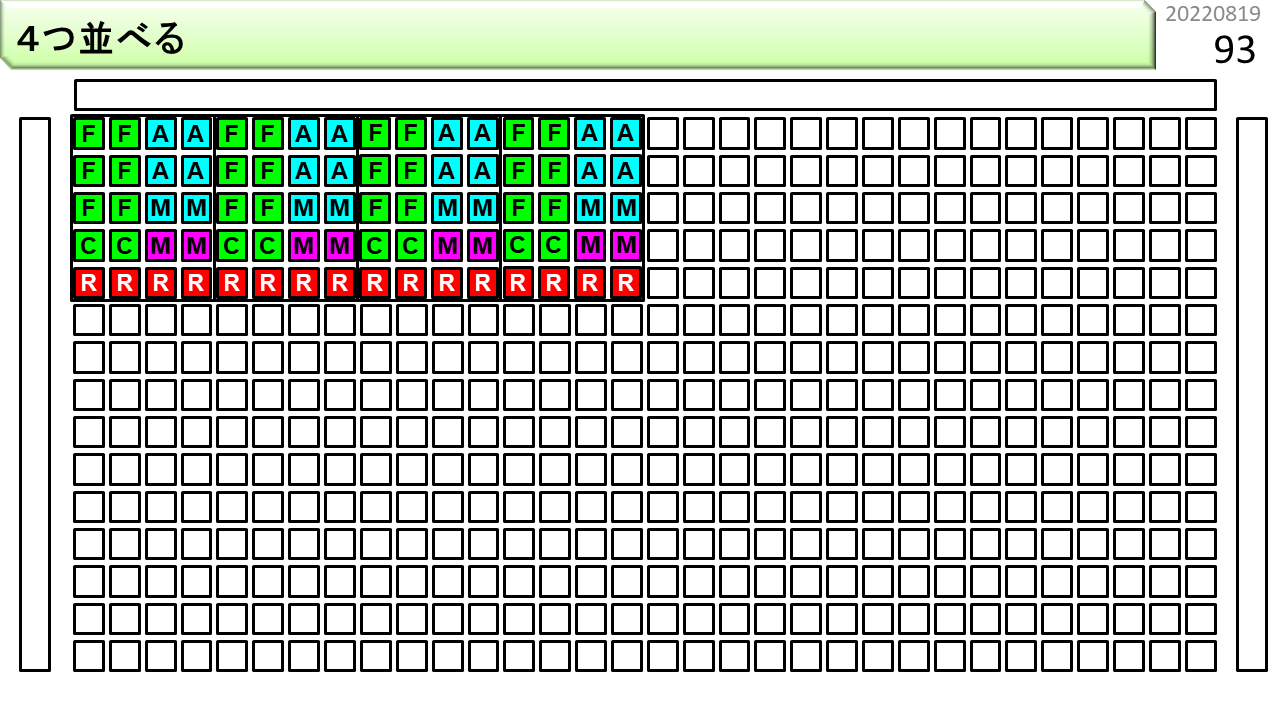
そして,横に並べます。
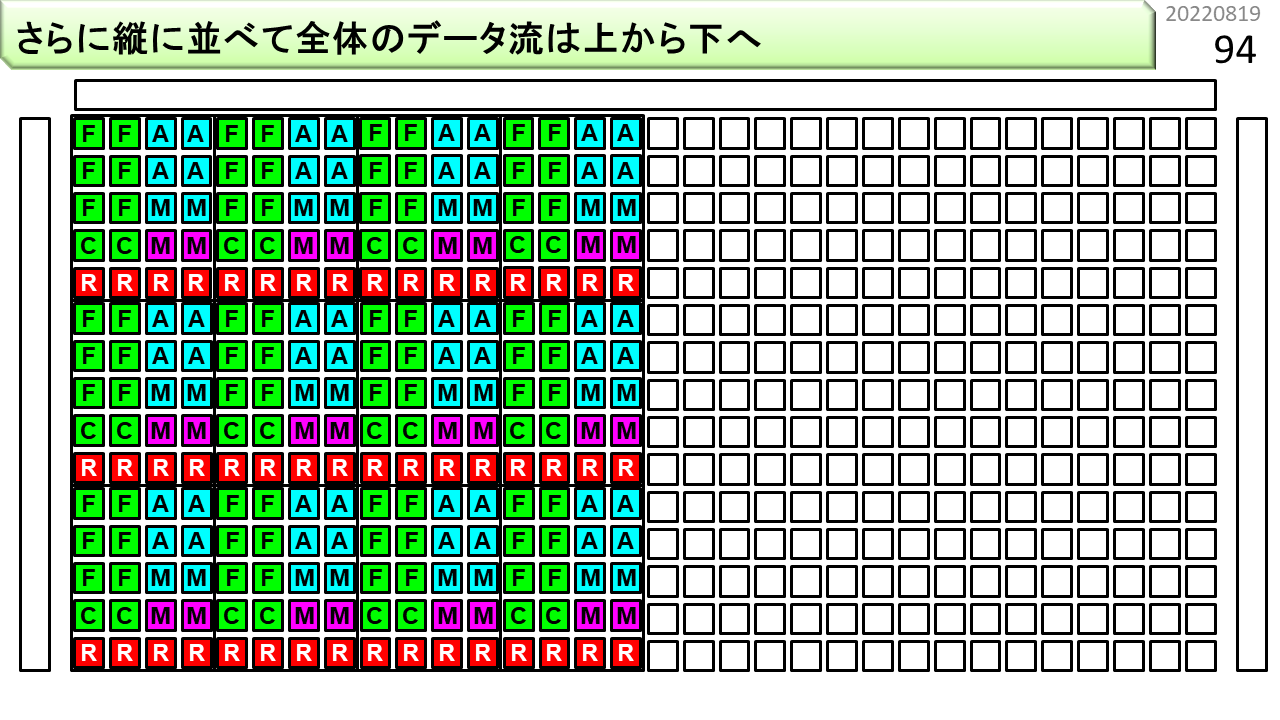
次に,縦に並べます。
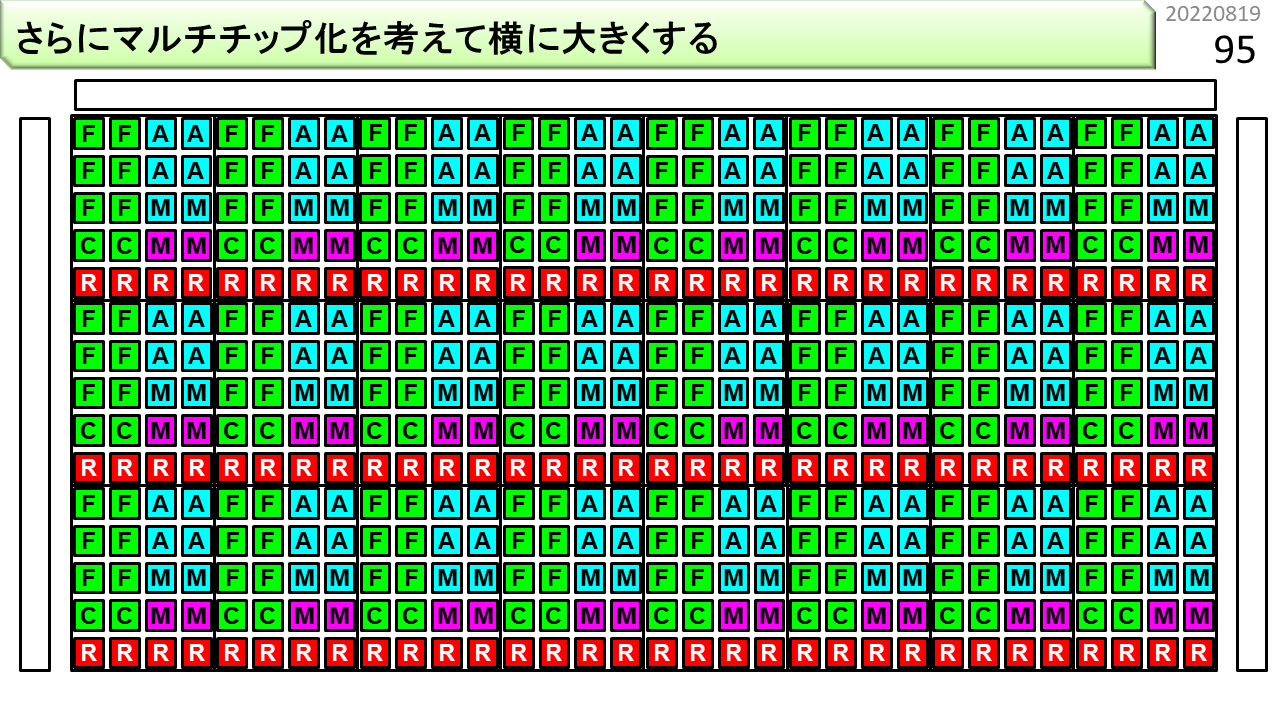
マルチコアに似ていますが、各々が独立に動作するのではなく、全体がデータを加工しながら、一方向にデータを流していきます。
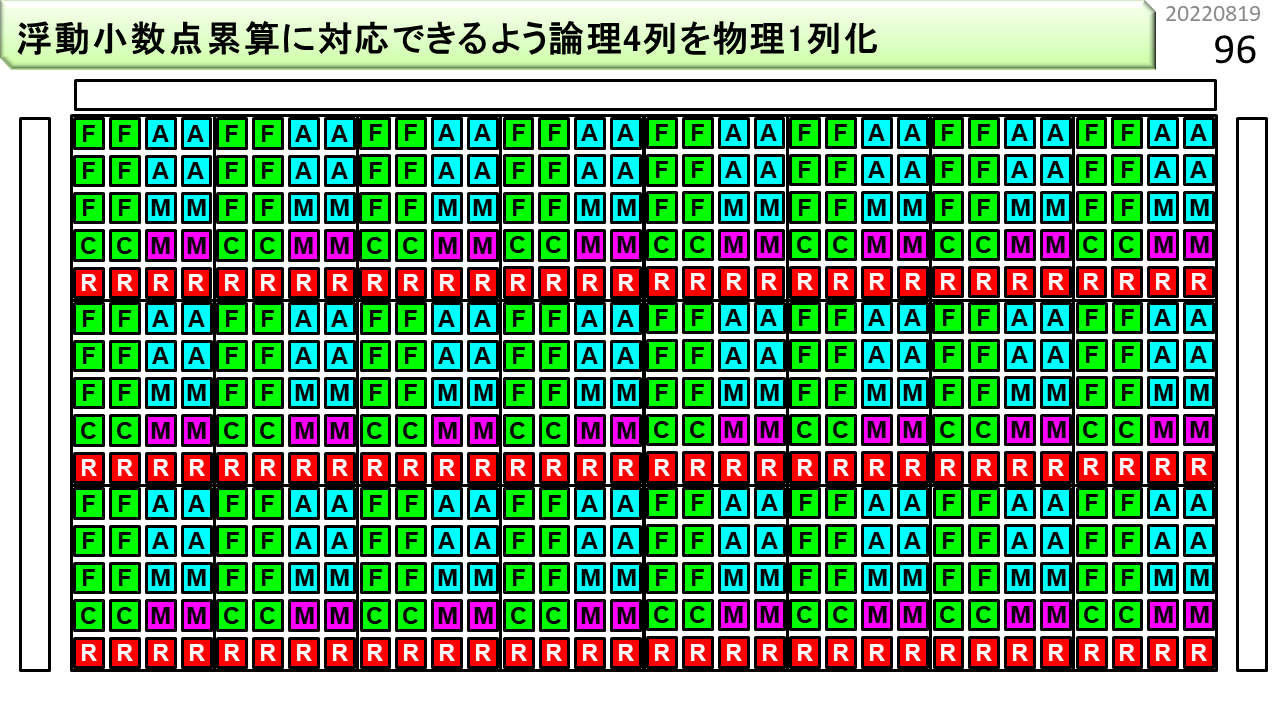
浮動小数点演算を効率よく実行するために、論理的な4列構造を物理的1列構造に束ねます。
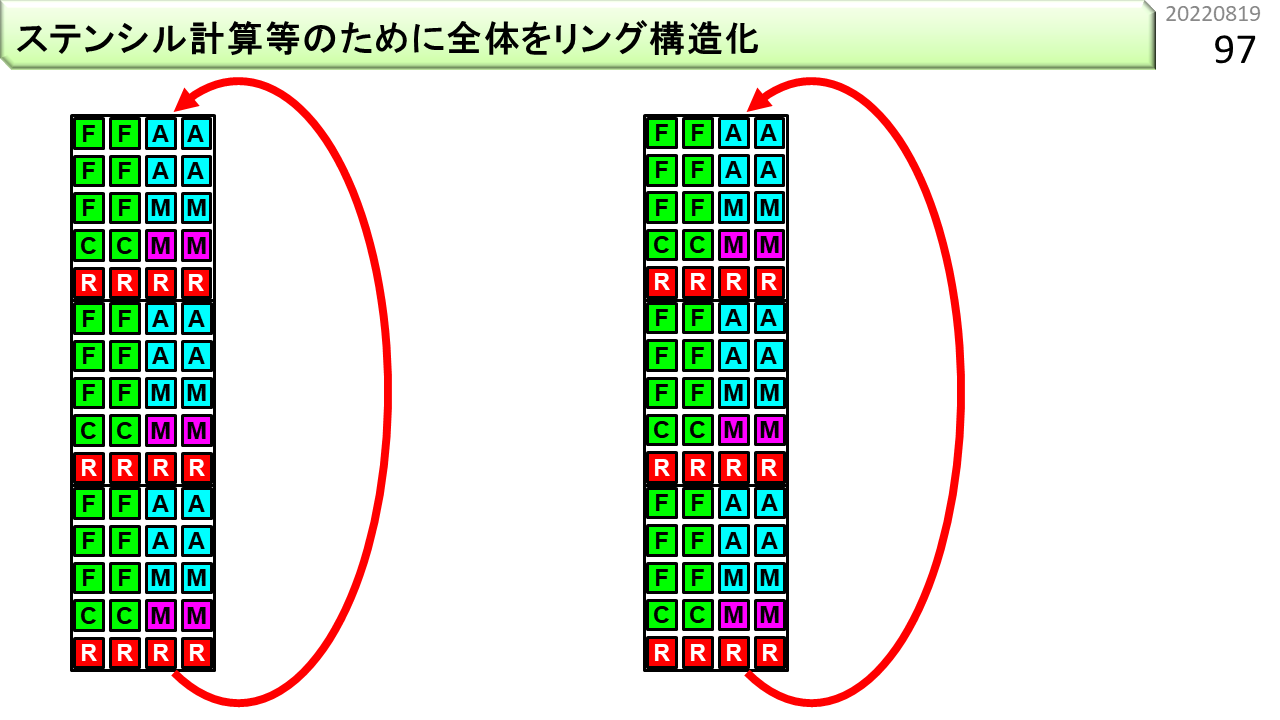
位置制約をなくすために、リング構造にします。
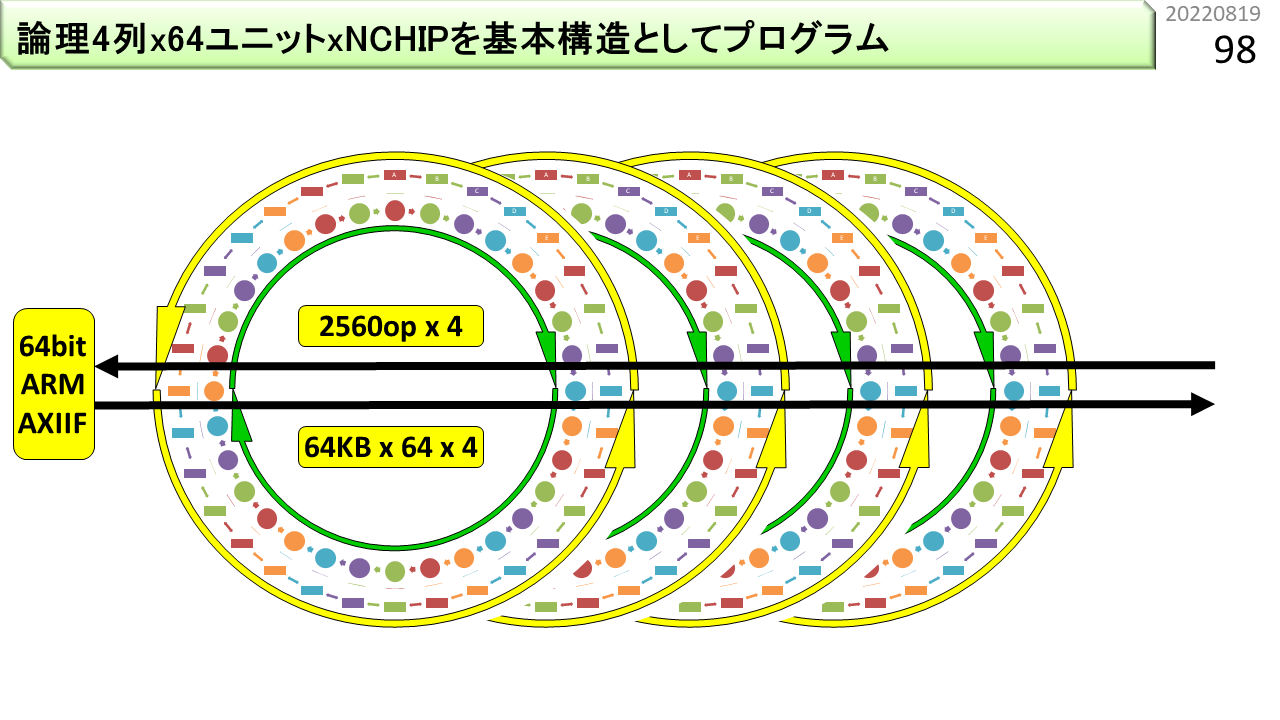
メモリバスにたくさん刺します。
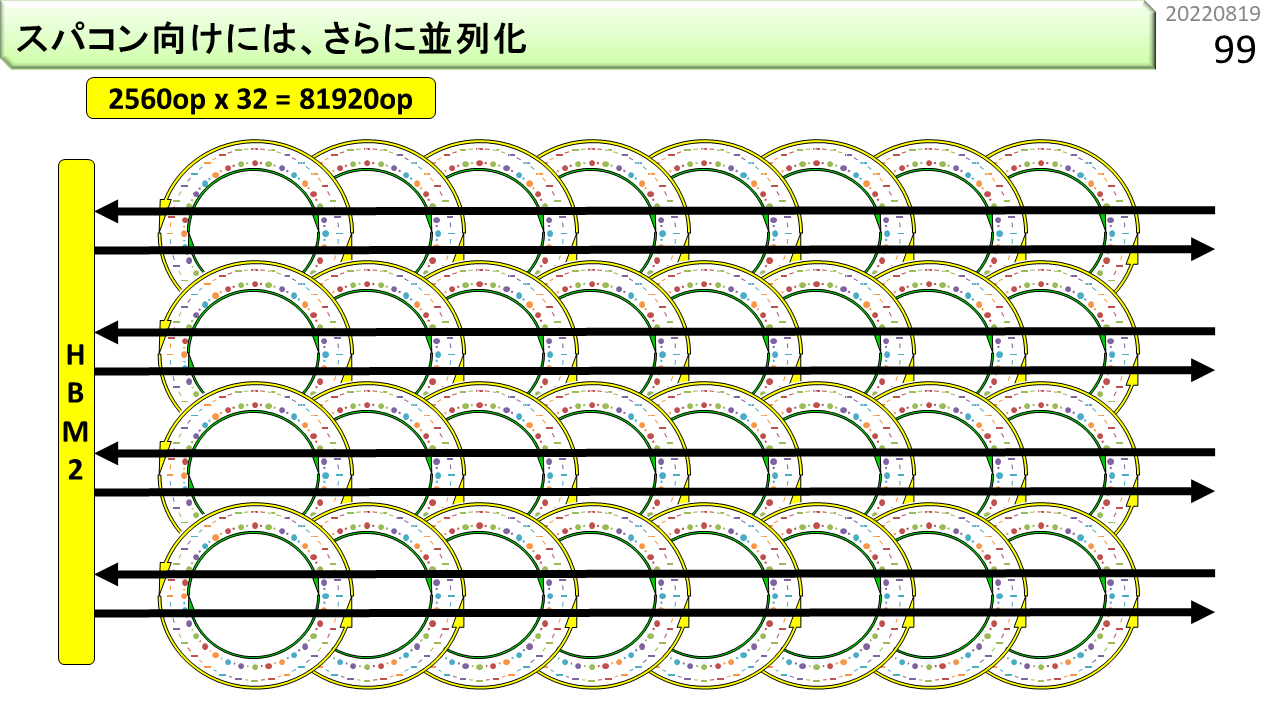
これで、8万オペレーションを同時実行できます。
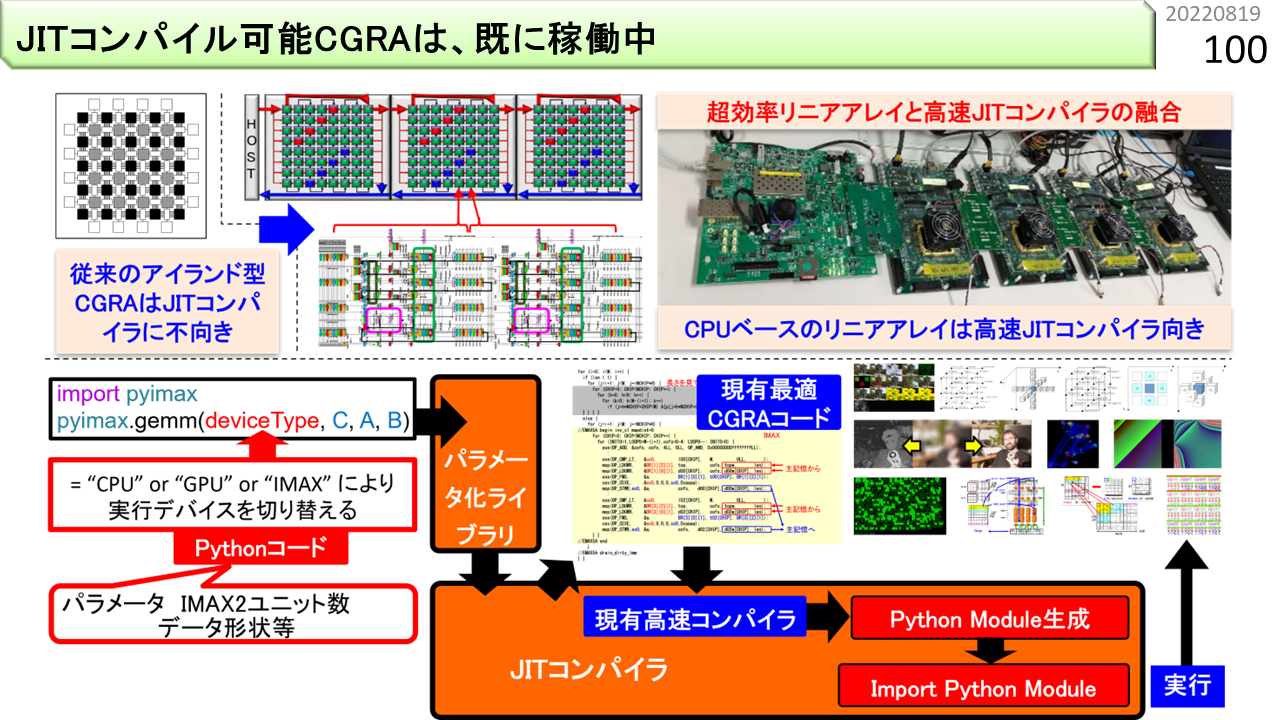
冒頭に,CGRAには大きく2種類あると言いました。この図の左上は,FPGAを拡張したもの,その他は,これまでに説明した,CPUを拡張したものです。コンパイルが高速だと,Pythonに組み込んで,実行しながらコンパイルすることもできます。
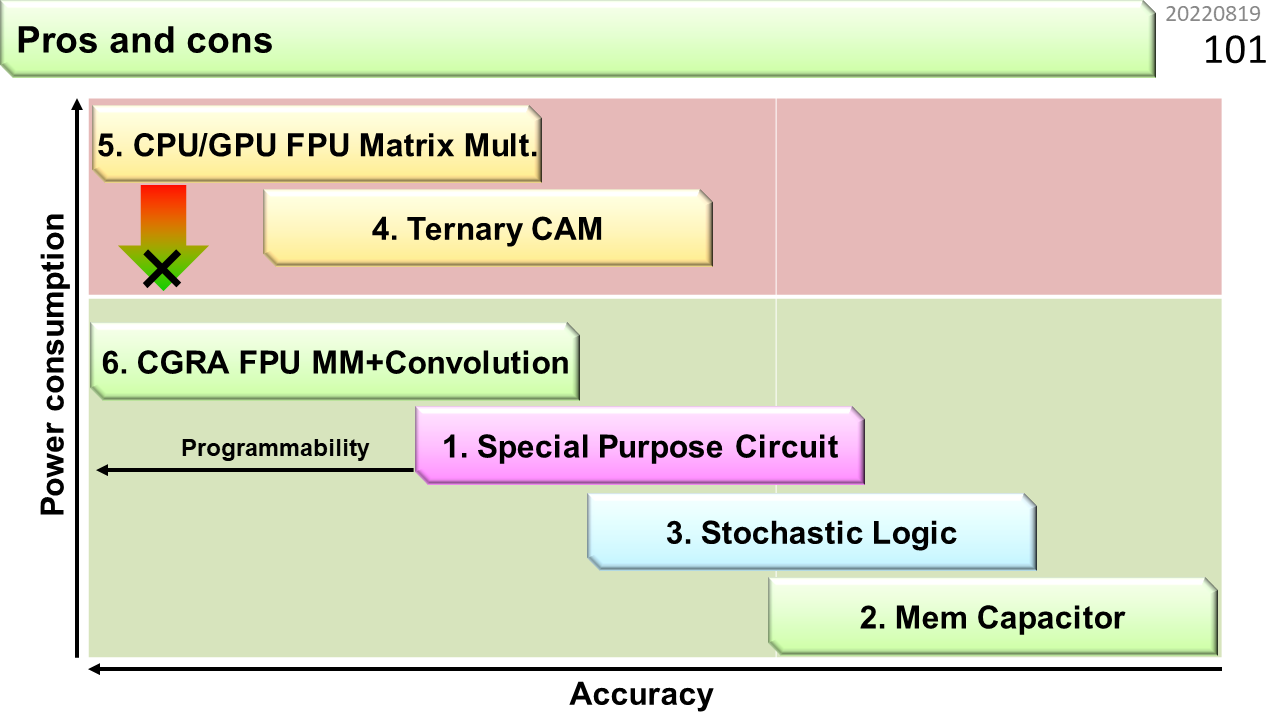
以上で,スリット検出器の6種類の実装方法が揃いました。図は,おおまかな特性をまとめたものです。上に行くほど消費電力が大きく,左に行くほど計算が正確です。左上には,ノイマン型のCPUとGPUが入ります。CAMも近くに入ります。これまでは,半導体微細化のおかげで消費電力が下がっていたので,微細化が止まると真下に移動することができません。下に行けるのは,非ノイマン型だけということですね。あとは,計算の不正確さをどこまで許容できるかで,どこまで消費電力を下げられるかが決まります。お金の計算をするコンピュータはどうでしょう。不正確は許されませんね。CGRAが限界です。天気予報や衝突シミュレーションなどの科学技術計算も同様です。AIはどうでしょう。精度が低いコンピュータでは,まだ,複雑な識別のために必要な大量の重みを計算することが困難のようです。重みが計算できたとして,識別に使うだけであれば,そして,大規模化と省電力化がうまく達成できれば,使う場面によっては,一番下までいけるかもしれません。一番下は,人間の脳のレベルです。20wattと言われています。いずれにせよ,今,ノイマン型コンピュータで走る様々なプログラムを移植して,みなさんが実験することができる非ノイマン型コンピュータは,CGRAだけです。未来のコンピュータと称して,この図にはない,様々な物理現象を利用するものが研究されています。でも,競争相手は,もはやCPUではなく,CGRAです。CGRAに勝てるものが出てくるでしょうか。そして,みなさんが使える日が来るでしょうか。それは何十年後のことでしょうか。
[2022/01/19]この先も読まないといけないの?

いいえ。普通の高校生は,ここでおしまい。頭が硬くなってしまって,定年まで何とかなればいいやと思ってる現役エンジニアも管理職も,ここでおしまい。ここからは,本当に興味を持った人だけの世界。日本に何人いるでしょうね。このパワーポイント,社会人向け技術セミナーに使うと言いました。でも,予想では,全国から参加者3人くらいでしょうね。1人しかいないと,セミナー自体が取りやめになります。参加費高いし。そのくらい,日本は横並びが大好きです。他がやらないから自分もやらずに済むと安心する,半導体工場も消滅する,白色矮星的世界です。参加者が誰もいないことがわかったら,この記事を書く気も失せます。そしたら,この知識は誰にも知られることなく,ホームページも6年後に消滅します。なかったことになります。だから,今,書いています。たまたま見つけて気に入った高校生が3人いれば,この記事を書いた甲斐があったというものです。3人いれば文殊の知恵です。では,ここからは,3人しか読んでいないと思って続けます。大学の授業に出席しても,学生が数人しかいないことが結構ありました。先生の他には誰もいない教室を見たこともあります。そんな雰囲気,嫌いじゃありません。真剣に聞く学生しかいないのですから。そういえば,日本では,国が,半導体復活をかけて,すごいお金を投入するそうです。枯木に水をやるよりも,3人の高校生に全部あげたほうがいいですね。6年経てば現役社会人です。すごいCGRAを作ってくれるはずです。他の人は,ただ,邪魔をしなければいいのです。
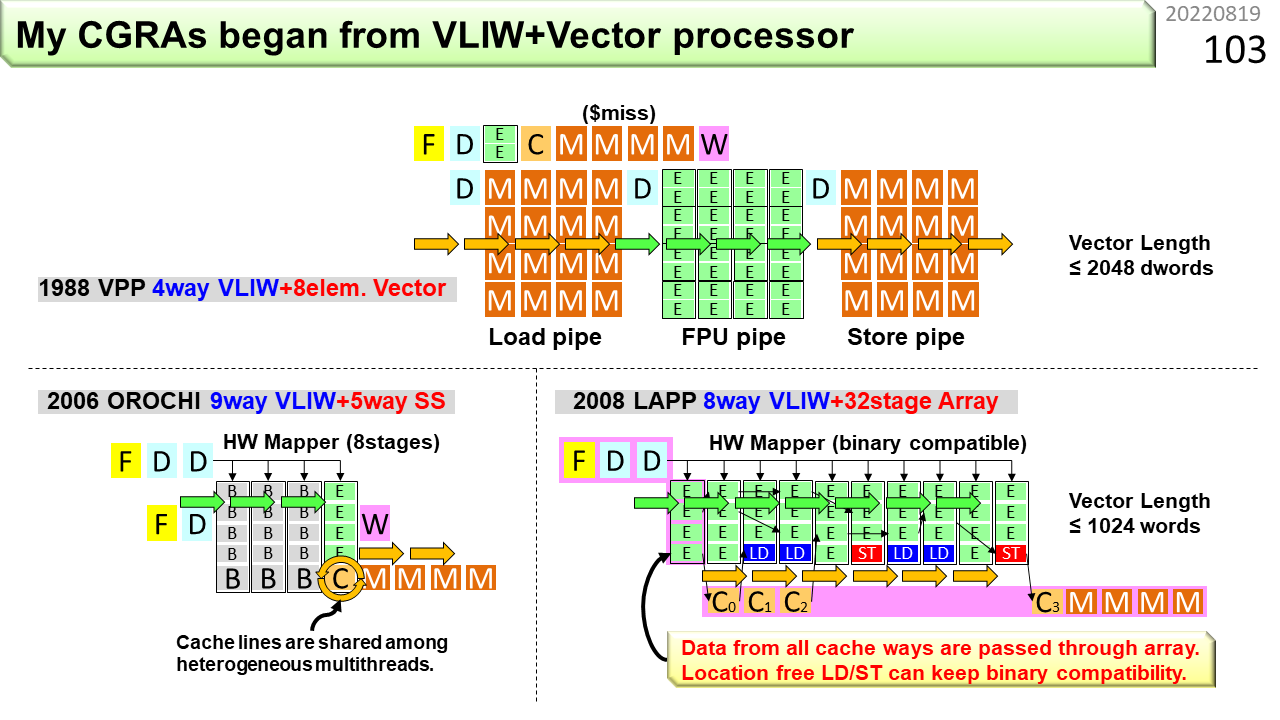
では,初級編をはじめます。え? と思った人は,覚悟が足りません。さて,この図は,自ら関わり,実際にLSIになった多くのコンピュータのうち,CGRAに関連がある初期のものです。VPP(Vector Parallel Processor)は,社会人になって最初に関わったスパコンです。VLIWとベクトル演算器の両方を搭載していました。F,D,E,C,Wという文字が並んでいますね。Fは命令フェッチ(学生が列に並ぶ),Dは命令デコード(注文を聞く),Eは演算実行(うどんゆでる),Cはキャッシュ参照(器に盛る),Wは結果格納(うどん渡してお金受けとる)です。以前に説明した5分割と少し違いますが,この分割がコンピュータの動作に近いです。上側がVLIW,下側がベクトルです。ベクトルのDは,100人分の同じうどんの注文ですね。Dは別にして,3つのパイプラインが繋がってデータが流れていく様子は,CGRAの動きに似ています。ただし,ベクトルでは,連結できるパイプラインは2本程度しかありません。FPU(浮動小数点演算ユニット)パイプラインだけたくさん繋げることはできません。
2つ目はOROCHIです。VLIWとスーパスカラの両方を搭載していました。ページ番号75に,CGRAへ繋がる前段階としてVLIWがありましたね。OROCHIは,たくさんのVLIWを命令バッファ(B)に溜めながら,隙間にARMの機械語命令を紛れ込ませて実行します。頭が2つで,胴体が1つなので,OROCHIです。VLIWは規則的なプログラムの消費電力を減らす効果があるので,こういう構成を考えました。実は,命令バッファの部分が,IMAXの原型です。
3つ目はLAPP(Linear Array Pipeline Processor)です。スーパスカラが無くなって,VLIWとCGRAになりました。演算ユニット(E)がたくさん並んでいる部分がCGRAです。最大の特徴は,普段はVLIW命令を実行し,ループ構造を検出すると,ハードウェアが自分で連続するVLIWをCGRAにセットして,高速動作に切り替わる点です。VLIW命令互換のCGRAということですね。ただし,演算器にメモリを付けつつ,VLIW互換を維持するのは難しく,メモリ容量を小さくする必要があったため,CGRA動作できるプログラムに制約がありました。
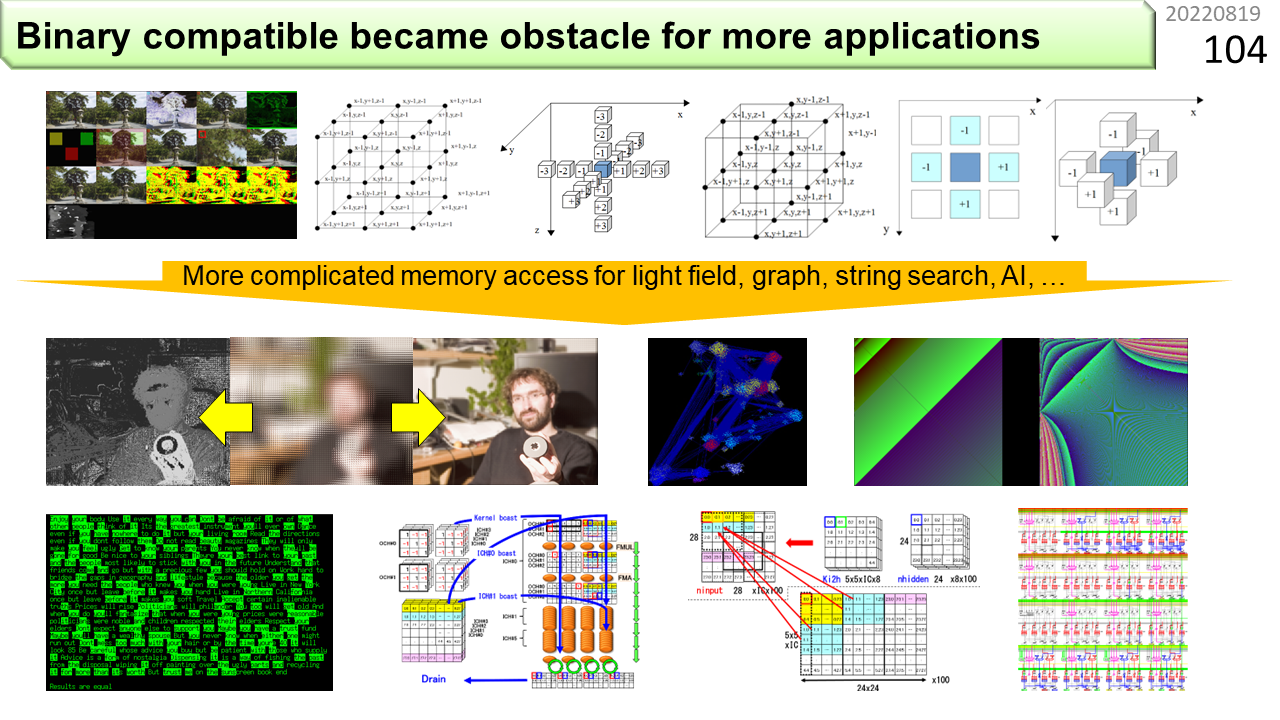
図の上がLAPPで動かせるプログラムです。画像処理や,ステンシル計算と呼ぶ科学技術計算が得意でした。そして,最近では,下のように,もっと複雑なプログラムを動かす必要が出てきました。LAPPをどんどん改良することで,上に加えて,ライトフィールド画像のレンダリングや距離画像生成,グラフ構造解析,逆行列,文字列検索,機械学習に必要なテンソル計算,畳み込み演算や行列積など,複雑なメモリ参照が必要なプログラムがいろいろ動くようになりました。
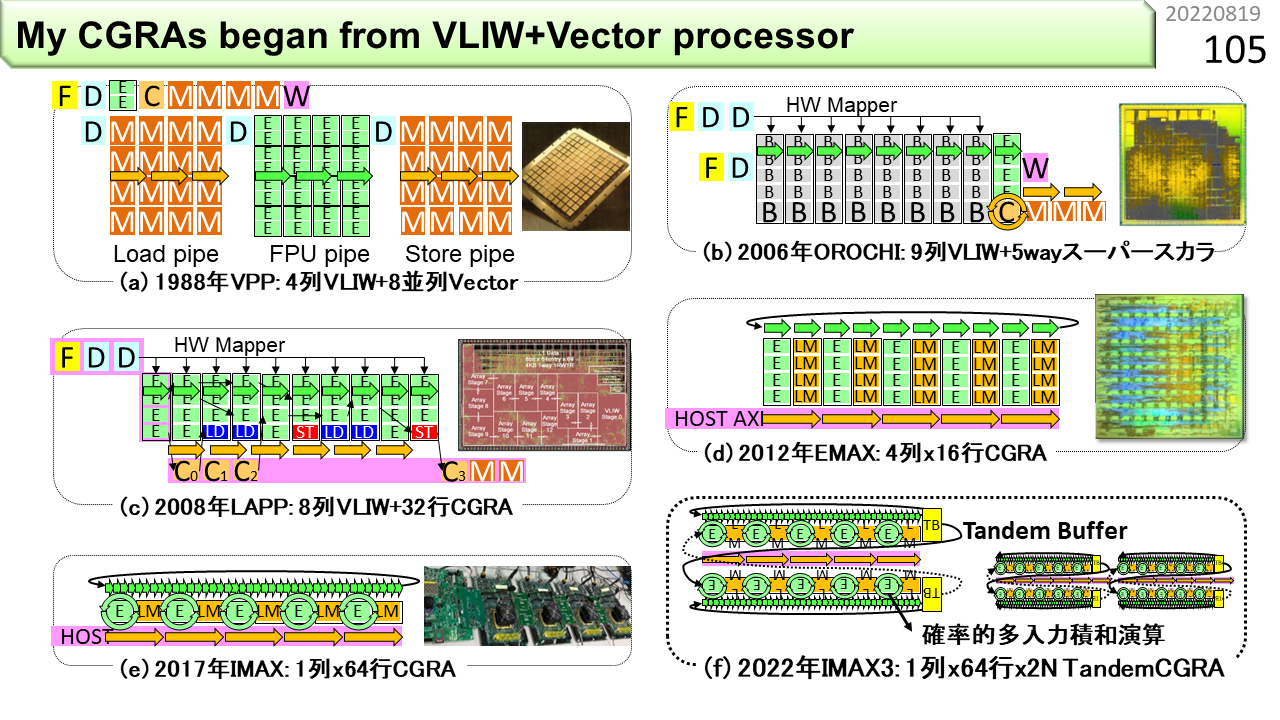
この図には,VPP,OROCHI,LAPPも含まれています。4つ目は(d)のEMAX(Energy-aware Multimode Accelerator eXtension)です。ここからは,ノイマン型コンピュータは内蔵されておらず,CGRAだけの構成です。好きなCPUに繋いで使うことを想定しています。LAPPがメモリ容量を大きくできなかった理由は,VLIW互換のためでした。EMAXは,互換を諦めることで,メモリ容量を大きくし,複雑なメモリ参照を伴うプログラムが動くようになりました。また,LAPPでは,プログラム実行中にハードウェアがVLIWを解釈し,CGRA内のネットワークを切り替えていたのに対し,EMAXでは,あらかじめ,コンパイラが切り替え情報を生成しておくことで,ハードウェアを簡略化しました。スーパスカラに必要であった命令スケジューラが,VLIWでは不要になったのと,同じ考え方です。これで,CGRA部分がとても小さくなりました。5つ目は(e)のIMAXです。EMAXでは演算器が4列ありましたが,IMAXでは1列に減っています。また,演算器の中でデータを回せるようになりました。回す機能というのは,計算結果を累算するために必要です。特に,浮動小数点積和演算を回すことが,最近のプログラムでは重要になっています。ところが,4段パイプライン演算器の中に,回す機能が増えると,4回に1回しか計算することができません。稼働率25%です。これでは,4列用意する意味がありませんね。そこで,マルチスレッディングを導入して,プログラマに対しては,論理的に4列にあるように見せつつ,物理的には1列で作ります。これで,演算器の稼働率を25%から100%に戻すことができました。最後は(f)のTandem CGRAです。これはまだ考え中です。CGRAを起動する際のオーバヘッドを減らすアイデアですが,まだ,シミュレータができていません。
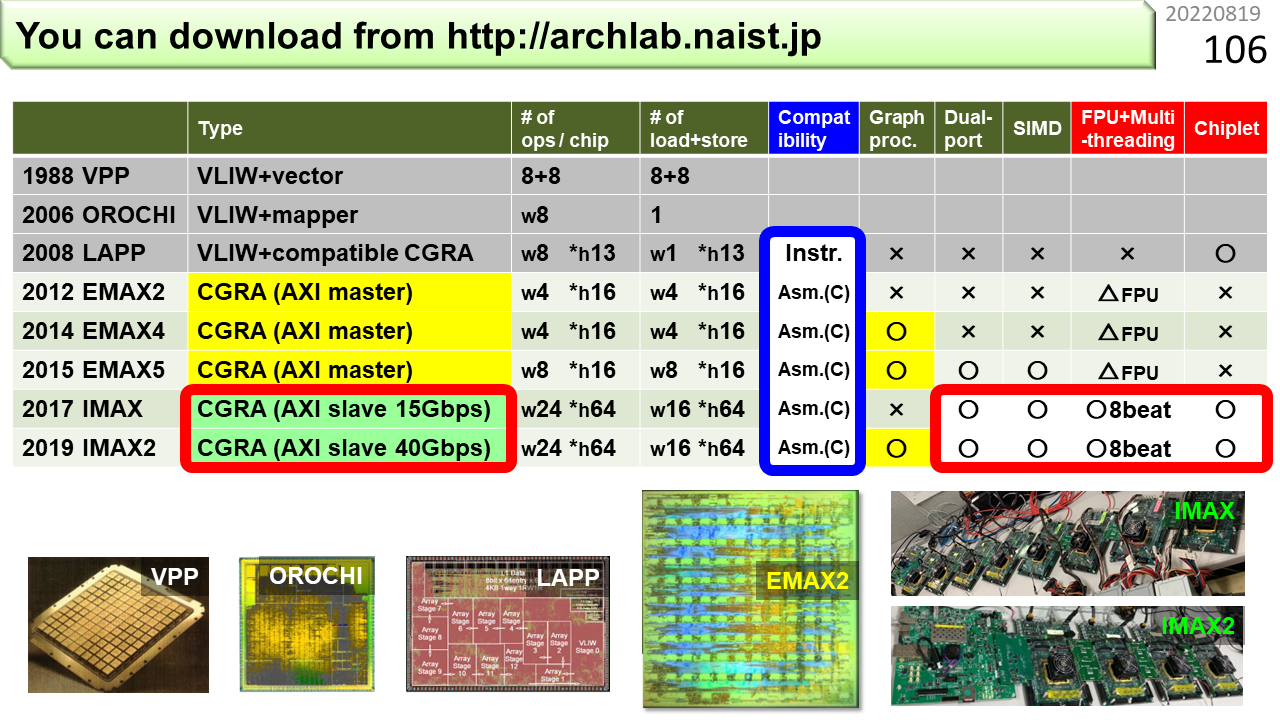
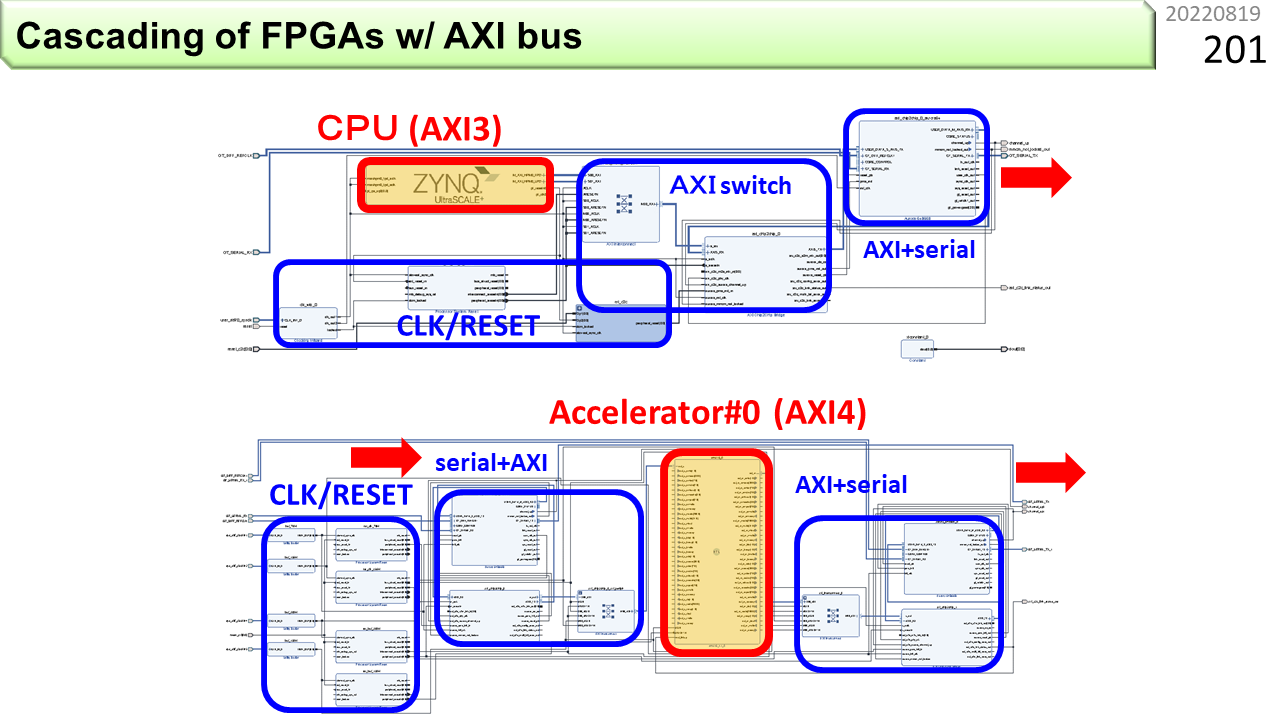
各々の機能を表にしました。LAPPまではノイマン型であるVLIW内蔵,EMAXまではAXIマスター,IMAXはAXIスレーブです。AXIマスターは,EMAXが自律的にCPUのメモリにデータを取りにいく能動的接続方法,AXIスレーブは,CPUからデータが送り付けられる受動的接続方法です。あとで詳しく説明します。AXIスレーブにすることで,IMAXはさらに小さく,また,たくさん繋ぐこと(Chiplet)ができるようになりました。
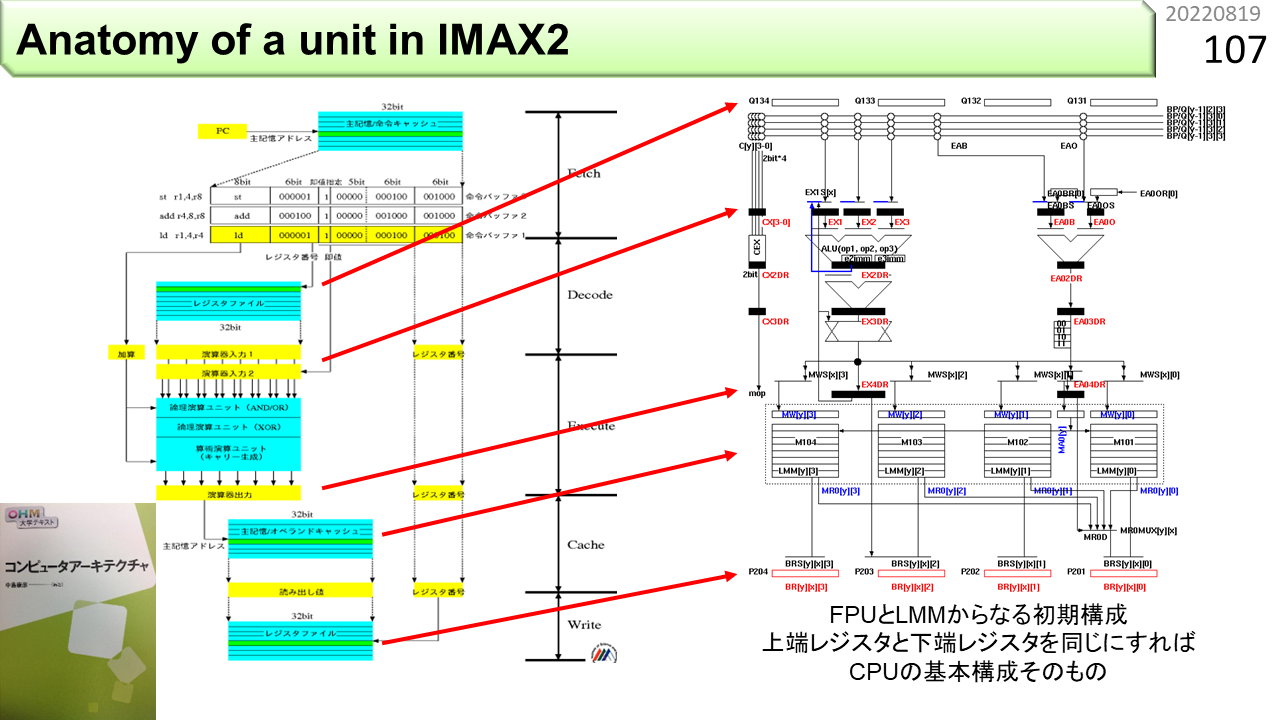
IMAXに入っているそれぞれのユニットは,実は,CPUの構造に似ています。ノイマン型の効率が悪いから非ノイマン型にしたのに,結局似てるなんて,誰かの呪いでしょうか。そうかもしれません。みなさんは,IMAXの構造を最初に見てしまいました。ここで,改めて,CPUの構造を見てみましょう。左の図は,前に紹介した教科書から持ってきました。図の真中に,上から,Fetch,Decode,Execute,Cache,Writeと書いてあります。どこかで見たことがありますね。ページ番号87です。この5分割されたハードウェア構造が,パイプラインの正体です。ただし,正しいCPUになる直前の構造です。上から見ていきましょう。Fetchは,機械語命令が入っている命令キャッシュから,命令を1つ取り出して,命令バッファと呼ぶ場所に書き込みます。Decodeは,機械語命令を解釈して,必要なデータをレジスタファイルと呼ぶデータの置き場所から,何個か取り出して,演算器の手前のレジスタに準備します。Executeは,用意されたデータを使って加算などを行い,結果を出口のレジスタに書き込みます。Cacheは,計算結果をオペランドキャッシュに書き込むか,オペランドキャッシュからデータを取り出します。Writeは,演算結果やキャッシュから取り出したデータをレジスタファイルに書き込んで,次の機械語命令が使えるようにします。一見,正しそうです。でも,気づいた人がいるはずです。これはCPUの構造としては間違っています。教科書では,次の図(ここには載せてないので教科書買いましょう 😀)で,正しい構造を説明しています。どこがおかしいのでしょう。
一番下にレジスタファイルがあって,Writeが書き込むところまで説明しました。でも,この下に何もないですね。これでは,次の機械語命令がデータを引き継ぐことができません。だから,CPUを作るためには,一番下にレジスタファイルを置くのではなく,Writeは,Decodeに入っているレジスタファイルに書き戻さなければなりません。これでCPUのでき上がりです。一方,右の図にあるIMAXは,一番下にレジスタファイルを置いたままにし,さらに下に,次のユニットを繋ぎます。最後はぐるっと回って先頭に繋がります。前に言った,リング構造のでき上がりです。CPUとIMAXは,上に戻すか,下に進むかの違いだけなんですね。ハードウェア機能に連続性を持たせることで,CPUに慣れ親しんだプログラマも,IMAXのプログラムにすんなり入っていけます。これがIMAXの設計思想であり,狙いです。
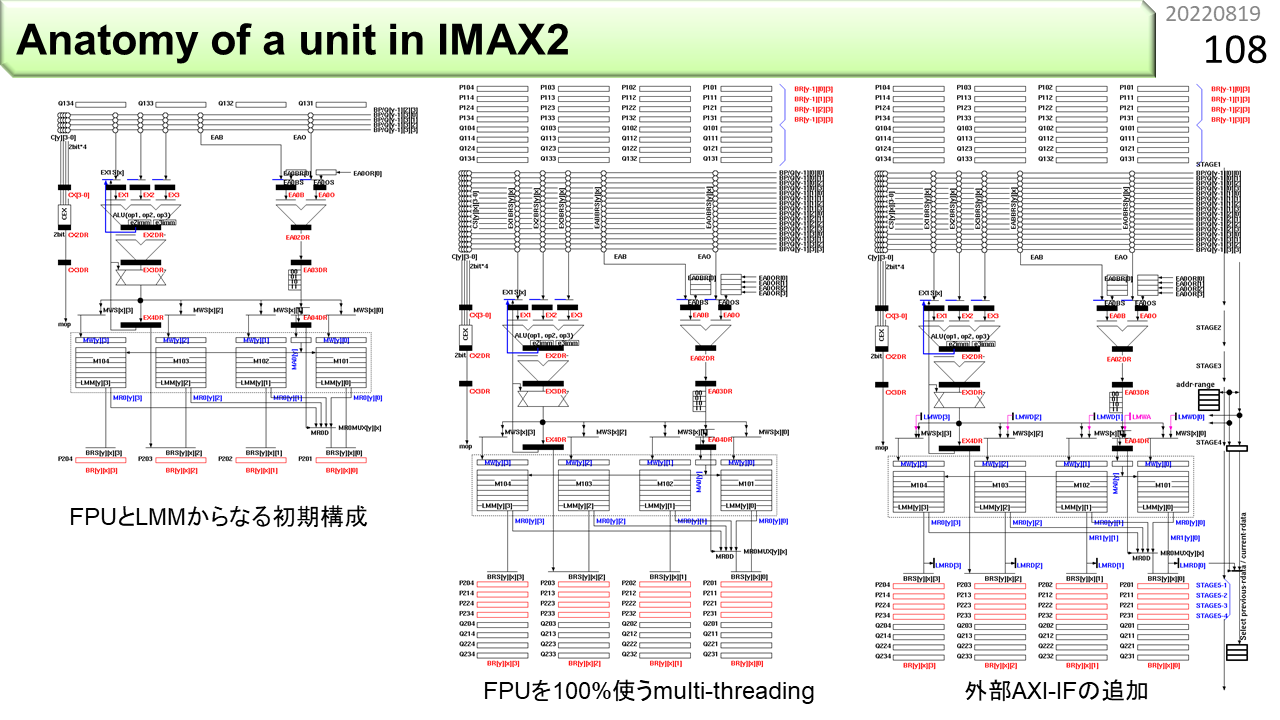
左端は,CPUと少しだけ違う基本構造で,論理的にも物理的にも1列分です。左上の山形がパイプライン演算器,右上の山形がメモリ参照のためのアドレス生成器,長方形が多数並んでいる中央の箱がメモリです。一番上と一番下に,細長い長方形が4本ずつのレジスタファイルがあります。ここから,IMAX2に進化させてみましょう。真ん中は,浮動小数点演算器の稼働率を100%に維持するマルチスレッディングを追加した構造です。論理的に4列分を収容するために,演算器は1つのままで,レジスタが4倍の16本に増えます。さらに,下に繋げるユニットに対して,4列分の状態をしばらく維持しておくことが必要なので,2倍の32本が必要になります。右端は,メモリに,CPUと接続するための外部インタフェースを付けた構造です。
どんどんいきましょう。左端に,回す仕組みが入りました。一番下のレジスタファイルや,演算器の出力から,上に戻る青い線が増えています。真ん中では,メモリの2箇所に同時アクセスするために,デュアルポートメモリに変更して,右上のアドレス生成器も2つに増えました。右端では,このユニットを飛ばして,上に繋ぐユニットから,下に繋ぐユニットにデータを直接送るための伝搬レジスタと配線を追加しました。

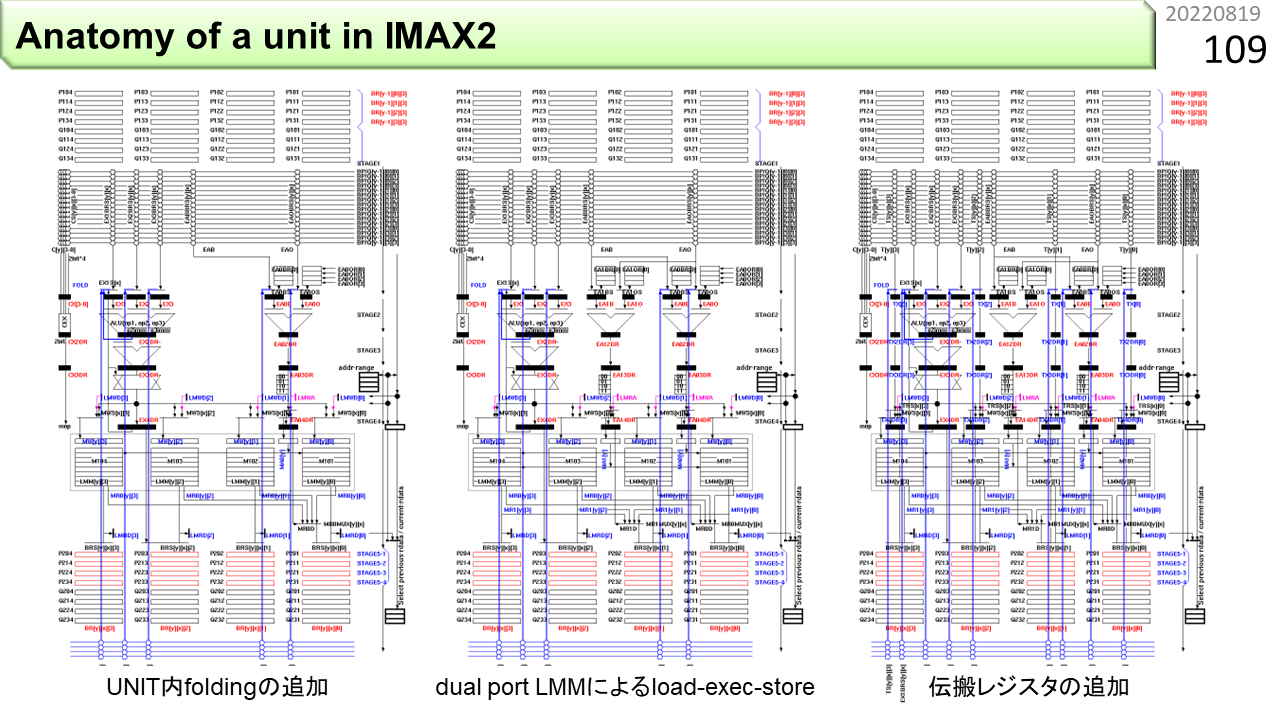
この図は,1つのユニットの中に,5個のループを作り,データを各所に同時に流すことで,無駄なく疎行列計算をするタイミングチャートです。同じパターンが繰り返されている中で,下から上にデータが戻る矢印が5種類見えますね。これが5個のループを表現しています。ちょうど五輪開催時期に考えました。余談ですが,ハードウェアを設計する時には,このようなタイミングチャートを書きます。プログラムは上から順に実行されるので理解しやすいです。でも,ハードウェアは全体が同時に動くので,可視化して確認する作業が必要です。空間的センスが要求されますね。左側は5個のループで構成されていますが,まだ隙間がありますね。二重化して10個のループを埋め込んだものが右側です。これで性能が2倍になりました。これをみて,CGRAの動きを読める人は,ハードウェアのセンスがある人です。
緑の線が,疎行列のために追加した配線です。これで,IMAX2の基本ユニットが完成しました。各所に隙間なくハードウェアが入っていることがわかります。右側の図は,疎行列計算の時のデータの流れです。とても複雑に見えますが,IMAX2のハードウェアは,このようなデータの流れをプログラムで自然に表現し,回路を動作させることができます。
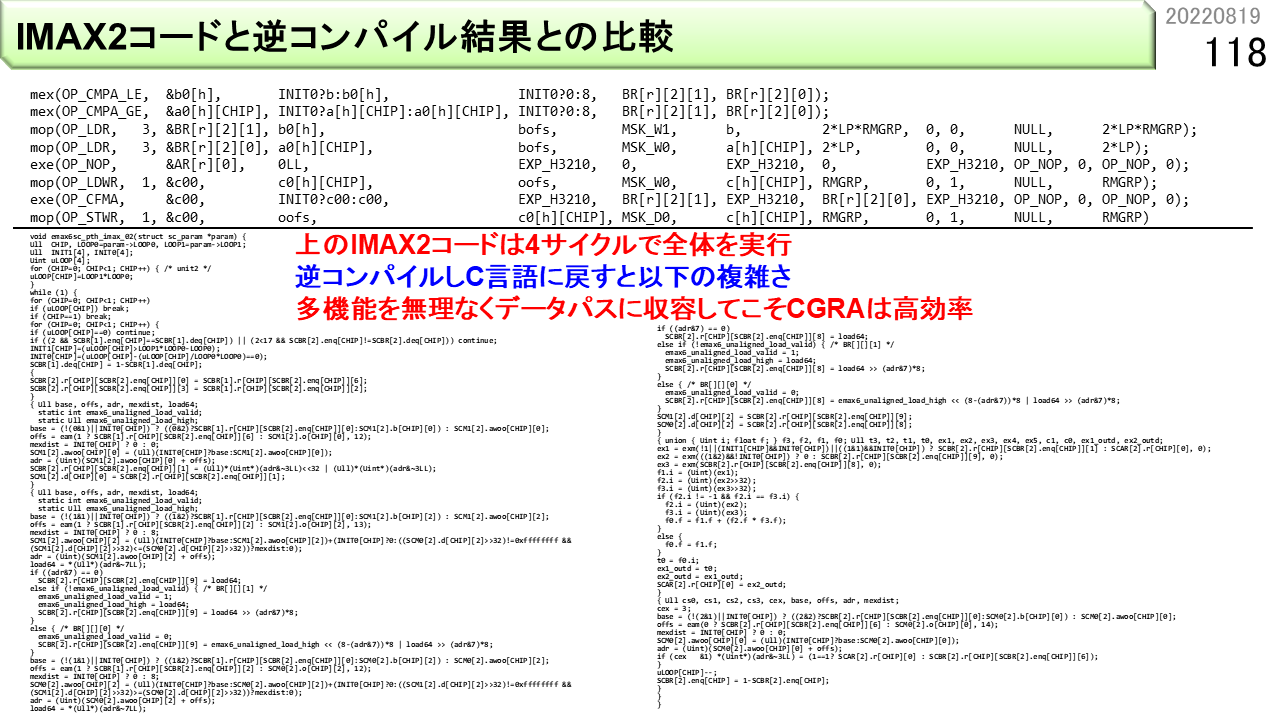
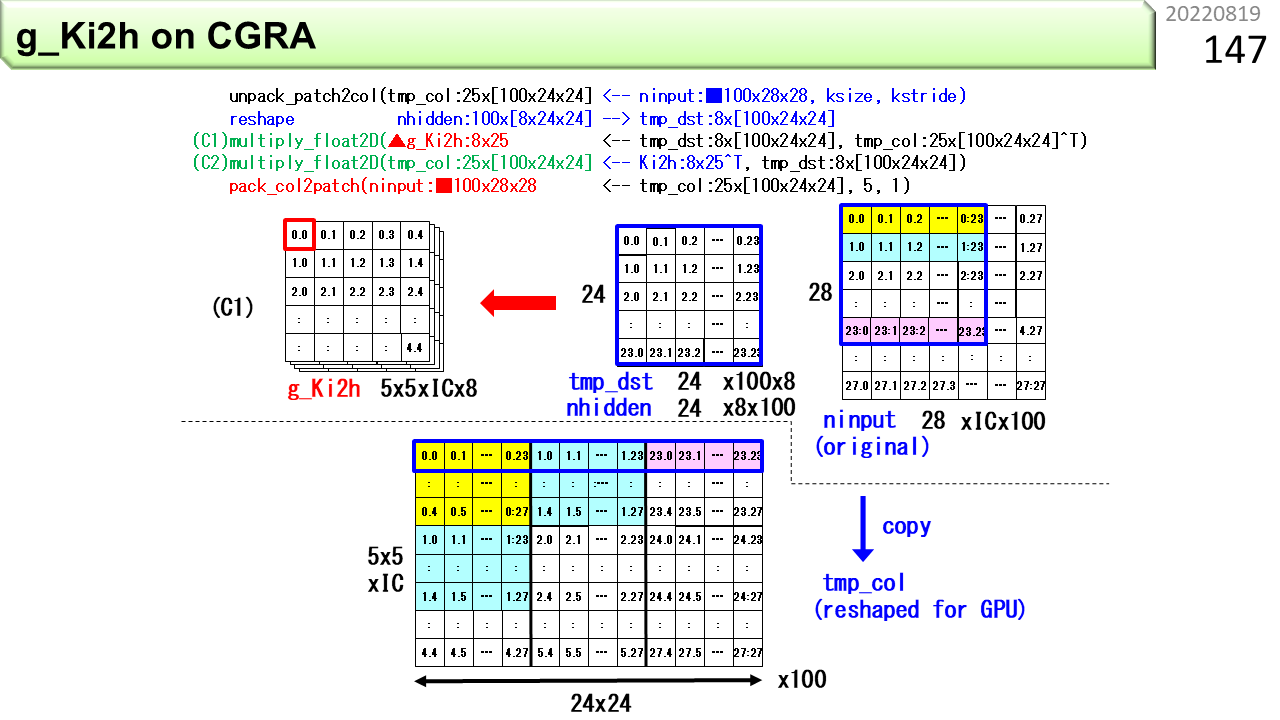
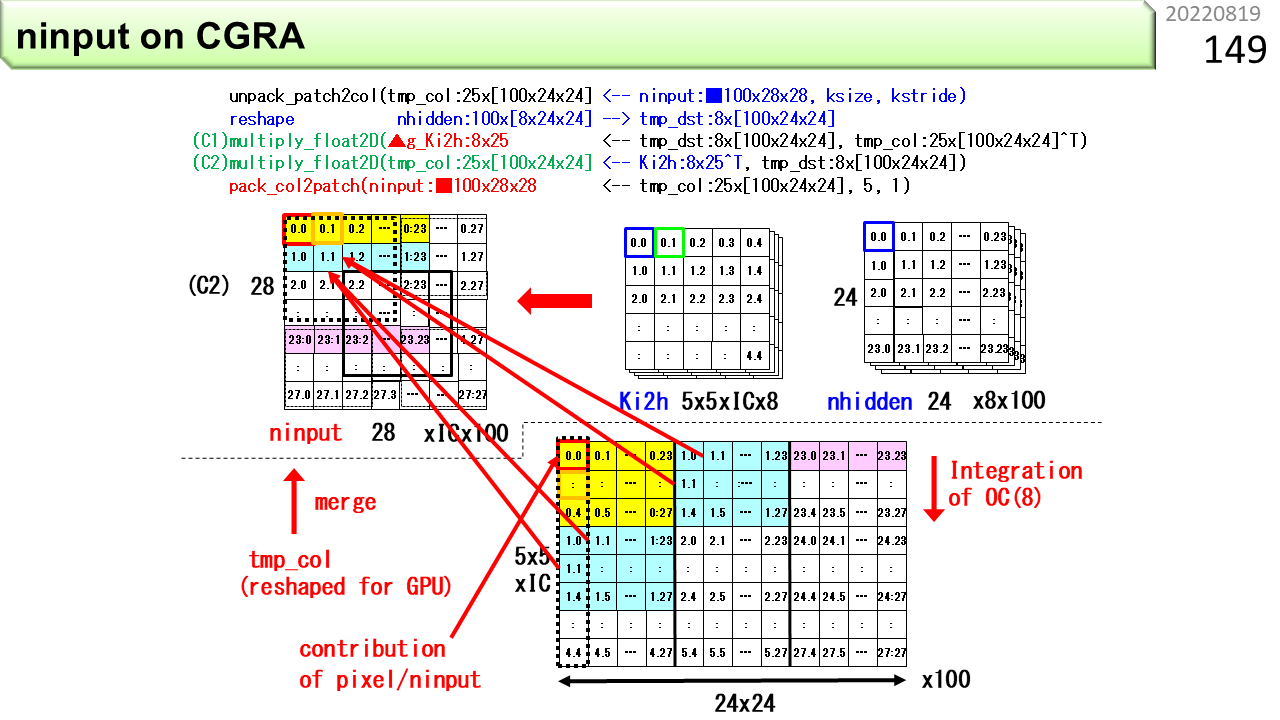
ここで,はじめて,IMAX2プログラムの具体例を紹介します。上の8行が,1つのユニットで疎行列計算をするIMAX2のプログラムです。C言語の関数呼び出しの形式で書いてあります。VLIWのように見えますね。その通りです。たくさんの機能をユニットにセットすることができます。IMAX2は,このプログラムをたった4サイクルで実行できます。60ユニットで実行すれば,さらに60倍の並列処理になります。下は,同じプログラムをノイマン型コンピュータ向けに変換したプログラムです。とても長いプログラムになりました。これは4サイクルでは到底実行できません。IMAX2は,多くの機能をコンパクトかつ巧妙にデータパスに埋め込んで,効率良く計算する仕組みであることがわかりますね。単に,CGRAにしたからできるというものではありません。例えるなら,ノイマン型コンピュータは都心の有名大型デパート,ふつうのCGRAはコンビニ,IMAX2は秋葉原高架下の超高密度電気街といったところです。
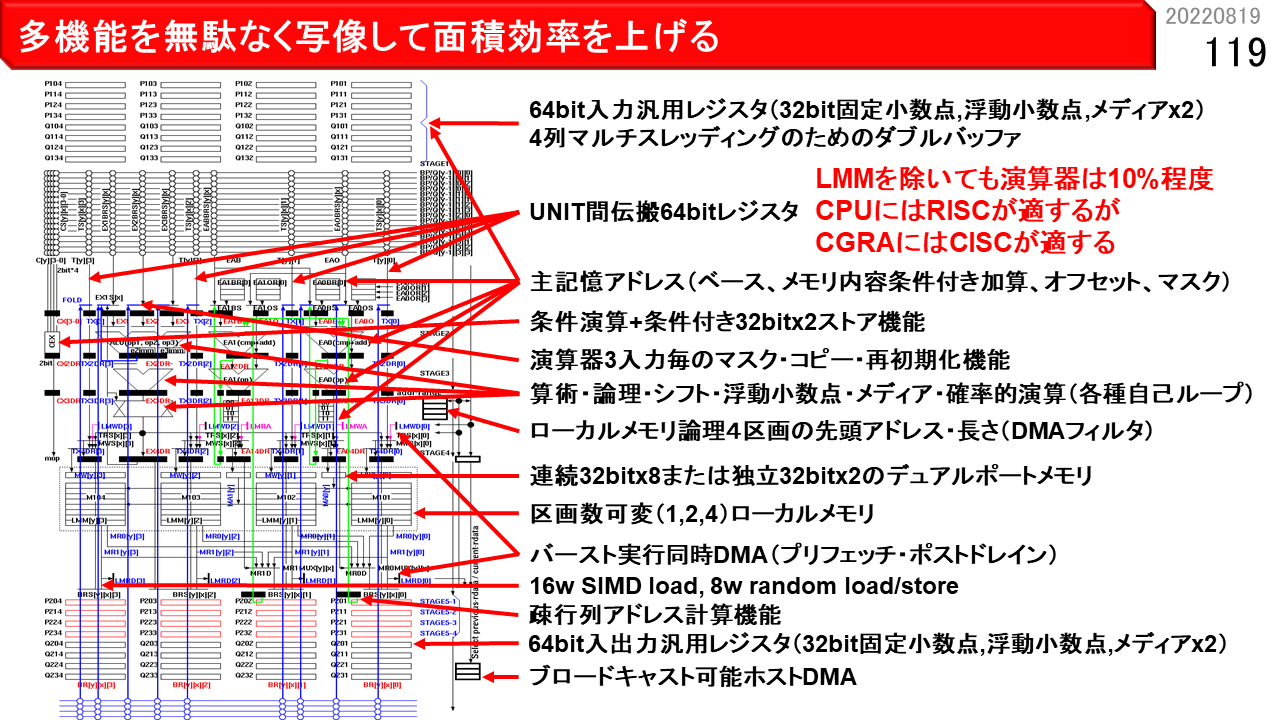
同じ説明の繰り返しです。ユニットの各部分がどういう役割を果たすかをまとめた図です。CPUより遥かに複雑に見えるかもしれませんが,CPUと違って,機械語命令を取り出したりスケジューリングする機能が不要なので,小さく作ることができます。コンパクトな構造なのに複雑なデータフローが写像できるというのは,まさに,「神は細部に宿る」ということでしょう。
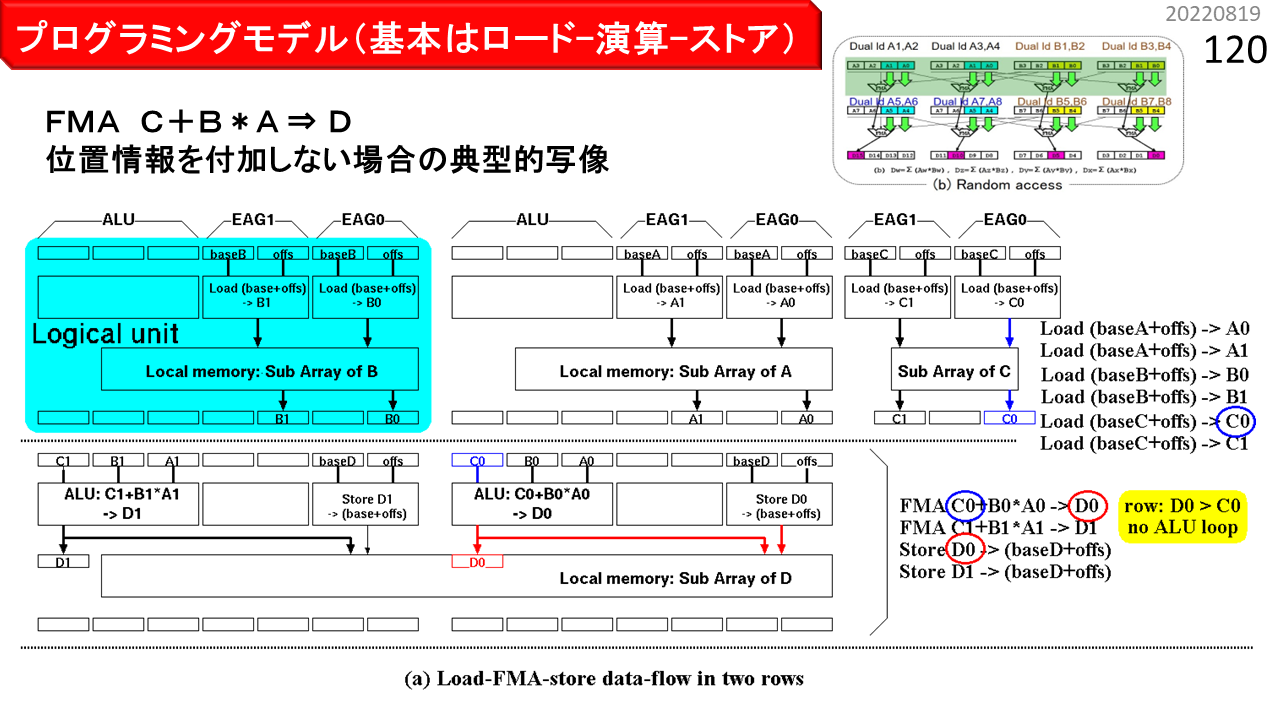
具体的なプログラムの書き方を理解するために,まず,書き方によって,ハードウェアの動きが変わることを見ていきます。前に説明した回す機能が何種類かあって,どのように書くと有効になるかさえ理解すれば,残りはたいしたことありません。まず,図の青い部分が,論理ユニット1つ分です。ALU,2個のアドレス生成器(EAG),および,デュアルポートローカルメモリが見えますね。横に4つ並べて,1行4列分です。そして,右端に,IMAX2プログラムの簡略表記が,縦にならんでいます。各々の記述の中に,行や列の位置情報を追加すると,コンパイラがその場所に強制的に配置するところが,ミソです。位置情報がなければ,コンパイラは,回す機能は使いません。この図(a)は,位置情報を記述せず,配列A,B,C,Dを用いて,2要素毎に"D=C+BxA"を計算する単純なケースです。まず,IMAX2の1行目に,Load A,Load B,および,Load Cがセットされ(4列目は省略),A,B,Cを入力とする積和演算FMAおよびStore Dが,CGRAの2行目に写像されます(3および4列目は省略)。位置情報を書かない場合,このように,上から下への単純なデータフローが形成されます。
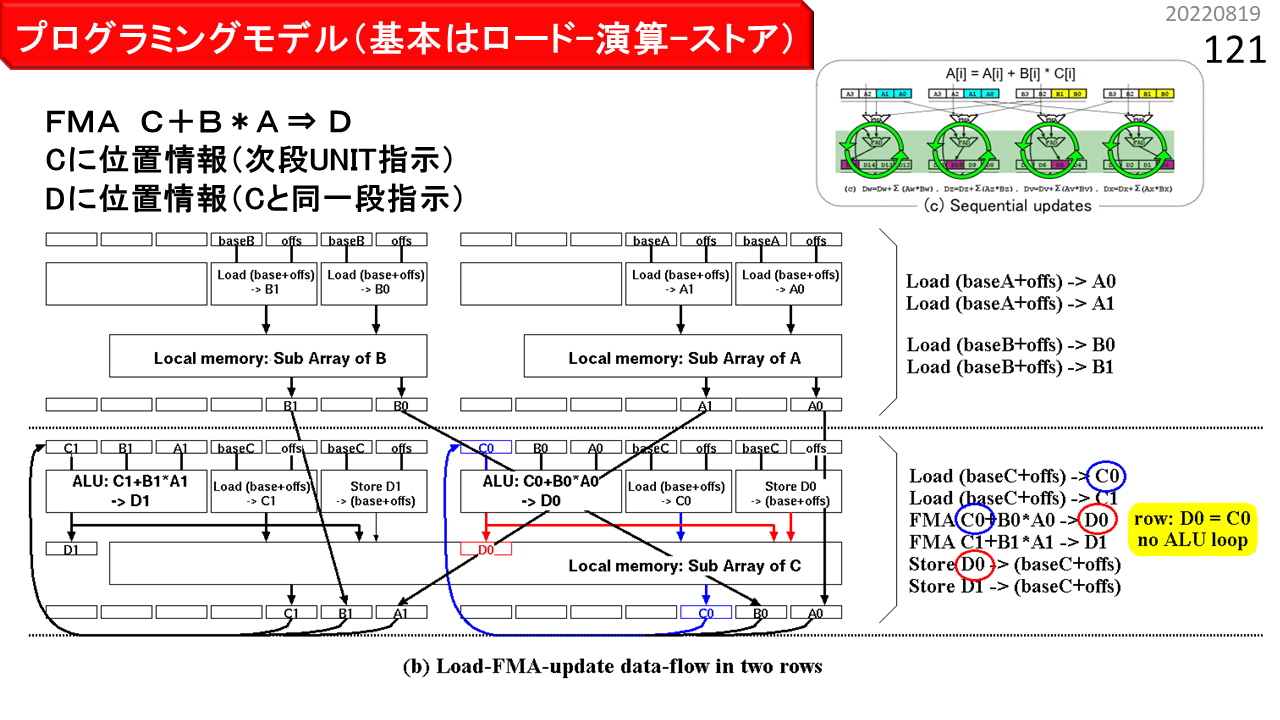
一方,図(b)は,配列A,B,Cを用いて,2要素毎に"D=C+B*A"を計算し,結果をCに書き戻すケースです。Loadの格納先C,および,FMAの結果を一時格納する変数Dに,位置情報を足すと,配列CへのLoadとStoreを同時に行います。IMAX2の1行目にLoad A,Load Bがセットされ,2行目にLoad Cがセットされます。積和演算FMAの結果を一時格納する変数Dが,Cと同一行に指定された場合,演算器の入力A,B,Cは,一度,同じ行の下側のレジスタに送られた後,演算器入力へ戻されます。配列Cに対するDのStoreも,同一行にセットされるため,同じローカルメモリの配列Cに対する,ロード-演算-ストアとなります。
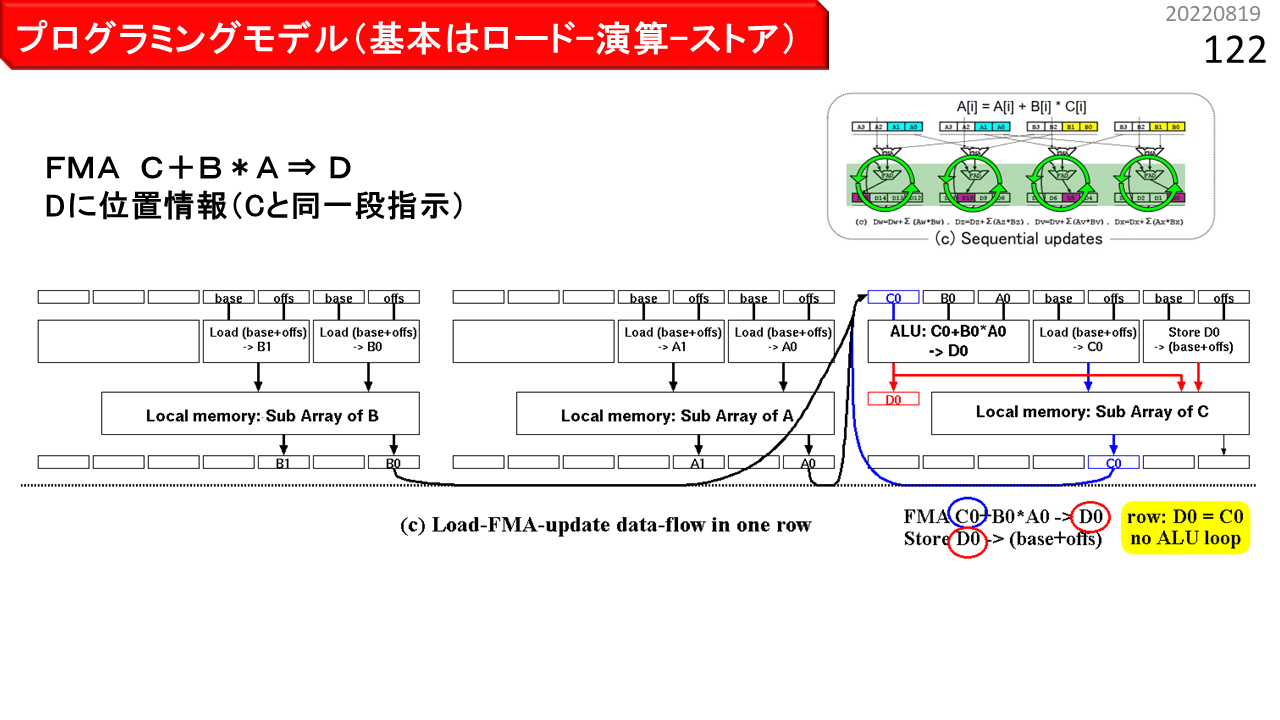
図(c)は,(b)を1行に収容するケースです。デュアルポートローカルメモリは,物理的には,IMAX2の1行に1個のみ装備されていて,時分割多重により,最大4列分の独立した論理メモリに見せています。このため,(b)では,1つの物理ローカルメモリを配列AとBで共有するのに対し,(c)では,配列Cも共有するため,配列あたり使用可能なメモリ空間は減少します。それでも,1行に収容するメリットがある場合は,Loadの格納先Cには位置情報を付加せず,FMAの結果を一時格納する変数Dのみに,位置情報を付加します。まず,Load A,Load B,および,Load Cがセットされ,積和演算FMAと,配列Cに対するDのStoreも,同一行に写像されます。
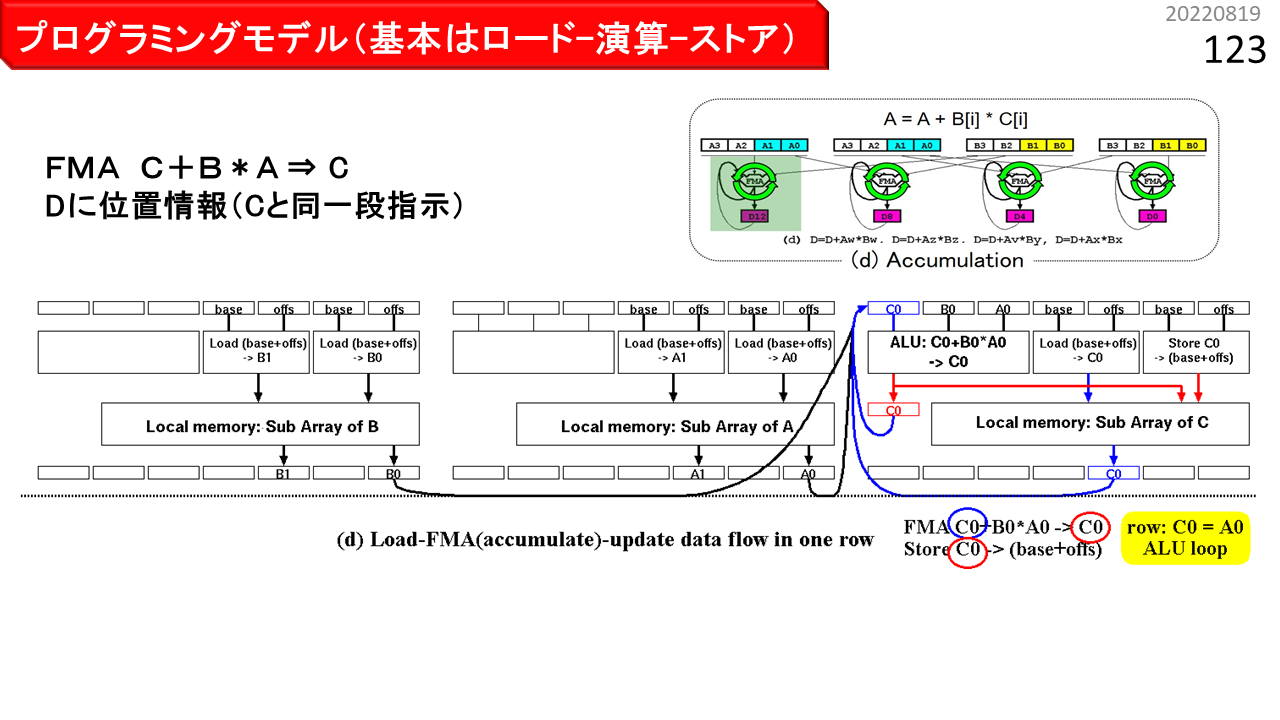
図(d)は,一時格納する変数Dを使用せず,積和演算FMAを"C=C+B*A"と記述したケースです。Store Cには位置情報を付加しません。プログラム上は,ローカルメモリにストアしたデータを再度ロードする,積和演算の繰り返しになります。しかし,ストア後に同一アドレスからロードして,演算に回す計算は,とても時間がかかるので,CPUでも回避しなければならないハードウェア動作の1つです。一方で,CGRAの場合,この動作は,演算器内のアキュムレート,つまり回す機能により,時間をかけずに容易に吸収できます。(c)との違いは,FMAが,単純なロード-演算-ストアではなく,入力C0が,LOOPの初回のみ配列Cのロード結果に接続され,そして次回以降は,演算結果に接続される,ロード-アキュムレート-ストアとなる点のみです。もちろん,パイプライン浮動小数点演算器の場合,演算器内アキュムレートは,単独では毎回の実行が不可能です。IMAX2は,4列マルチスレッディングにより,アキュムレートがあっても,論理UNITの動作にオーバヘッドが生じない特長があるため,性能低下の懸念なく(d)を利用できるというわけです。
以上のように,似たような積和演算でも,4種類の書き方があります。どれにするかを別に指定する方法を使えば,コンパイラは楽に作れます。でも,以前に,IMAX2のプログラムは,CPUでも動くことが重要と言いました。C言語の制約の中で正しく動き,かつ,IMAX2上で狙い通りに高速動作させるための,うまい仕掛けです。
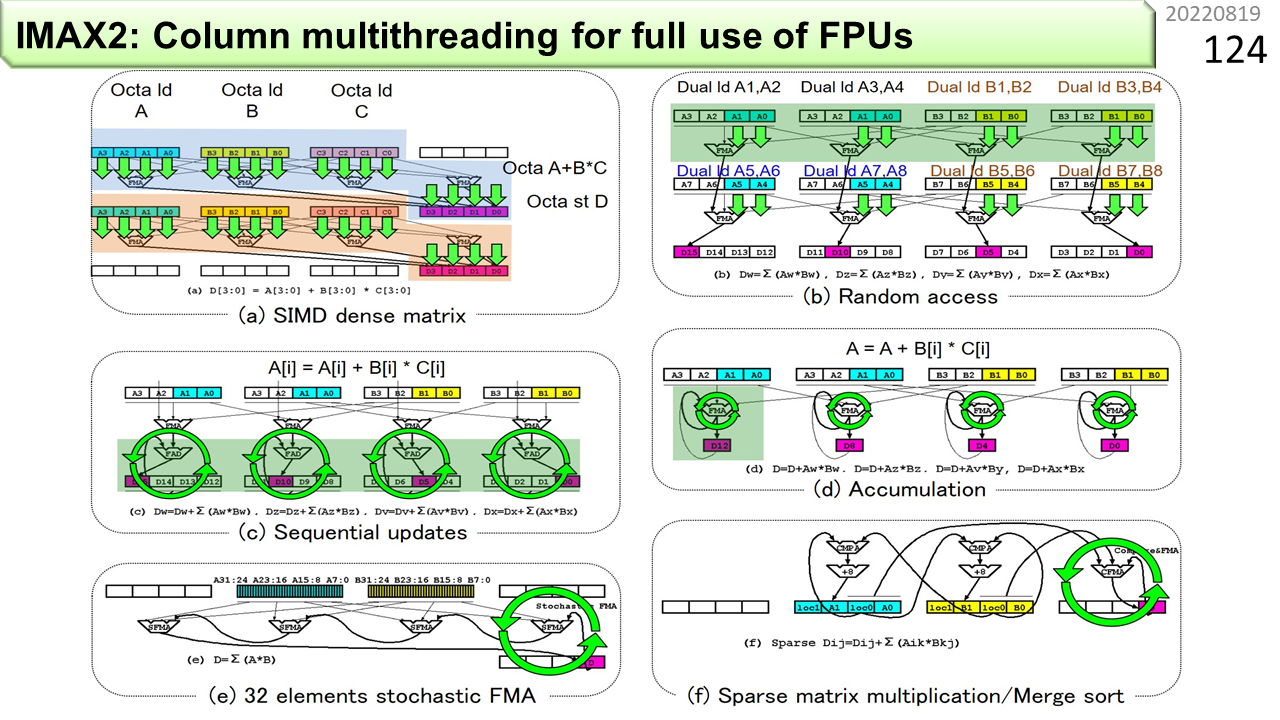
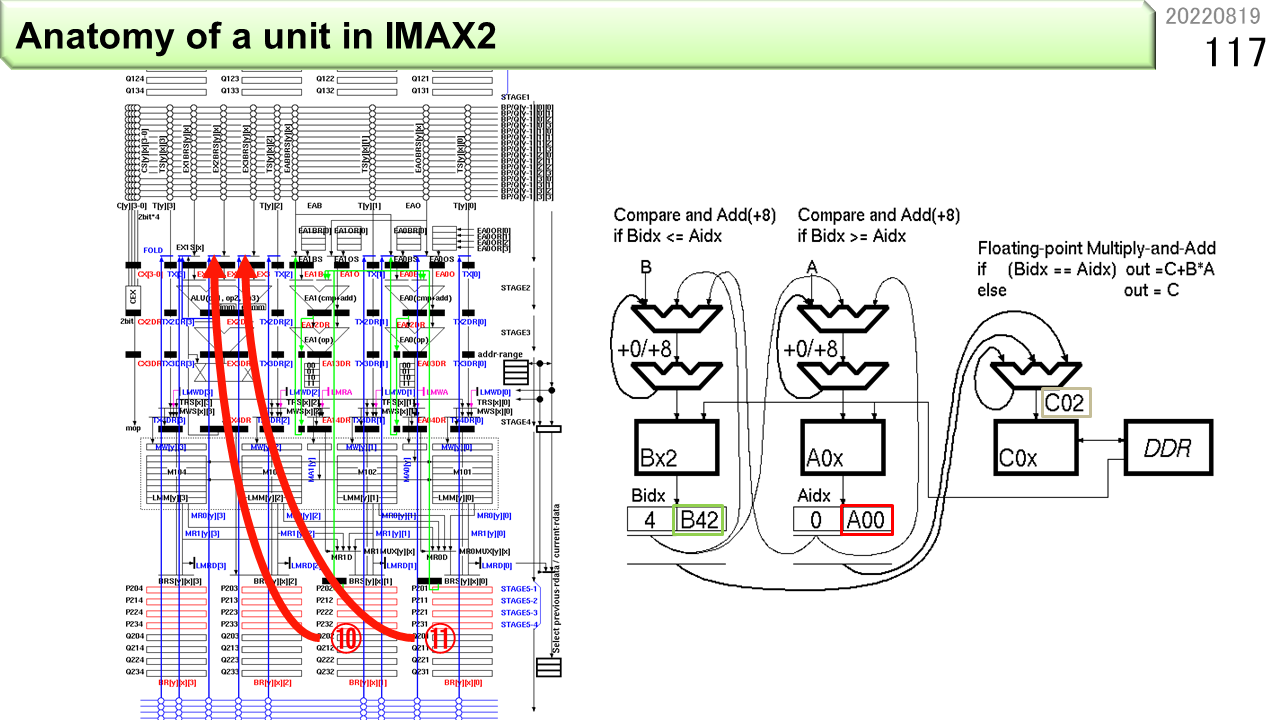
図(a)〜(f)は,IMAXが対応している計算パターンをまとめたものです。山形はALU,長方形はメモリを示していて,プログラムの視点では,4列構成です。(a)は,0の要素が少ない密行列を8並列のSIMD命令で処理するパターンです。青色メモリから,一度に配列Aの連続8要素を読み出します(1つの矢印が2要素に対応)。同様に,黄色メモリから配列Bの連続8要素,オレンジから配列Cの連続8要素を読み出します。そして,4個の3入力ALUが,A,B,Cの各2要素を使って,A+BxCを計算し,連続8要素の計算結果を赤色メモリに書き込みます。つまり,CGRAの1行あたり,8組のA+BxCを計算します。(b)は,各行各メモリの離れた2箇所から,連続2要素を読み出し,縦に送って,多くの積和演算を行うパターンです。1列目と2列目のメモリを共有すれば,各配列の離れた4箇所から読み出せます。さらに,横1列のメモリを全て共有すれば,配列の離れた8箇所から読み出せます。(c)も,縦に送って,多くの積和演算を行うパターンです。ただし,最後の結果をメモリに書き込む時に,以前の値に1回だけ累算し,次の場所に移動します。メモリから読み出して,ぐるっと回して同じ場所に1回だけ書き戻します。回す機能の出番です。(d)は,メモリの内容に1回だけ累算するのではなく,パイプライン演算器自身の演算結果を毎回戻して累算します。マルチスレッディングは,特にこのパターンにおいて,演算器稼働率を25%から100%に引き上げる仕組みです。(e)は,ページ番号46で説明した確率的積和演算のパターンです。IMAXのデータパスはよく考えられていて,確率的計算機能を自然に入れることができます。配列Aから連続8要素を読み出すことで,各8ビットの値を32個一度に読み出します。そして,8個ずつ,4つの確率的積和演算器に投入し,全ての結果を加算した結果をメモリに書き込みます。(f)は,最後に追加した,疎行列計算のパターンです。あらかじめ,64ビットの上位に要素番号,下位に要素値を格納することで,0の要素が多い疎行列を密行列に圧縮しておきます。IMAXは,CGRAならではの,とても巧妙な仕組みを使って,圧縮した行列どうしの行列積を計算します。メモリの有効利用と高速化が同時にできます。さっき説明しましたね。
このビデオは,論理的に4列構成のCGRAを物理1列に圧縮し,64ユニットを1個のLSIに収容し,3つのLSIをCPUに接続するまでをアニメーションにしたものです。LSIの中では,ユニット内メモリと外部とのインタフェースが,レイテンシ短縮のために,メッシュ構造になっています。一方,ユニットからユニットへ演算結果を伝搬させる演算データパスは,次のページの通り,1列に繋がったリング構造になっています。
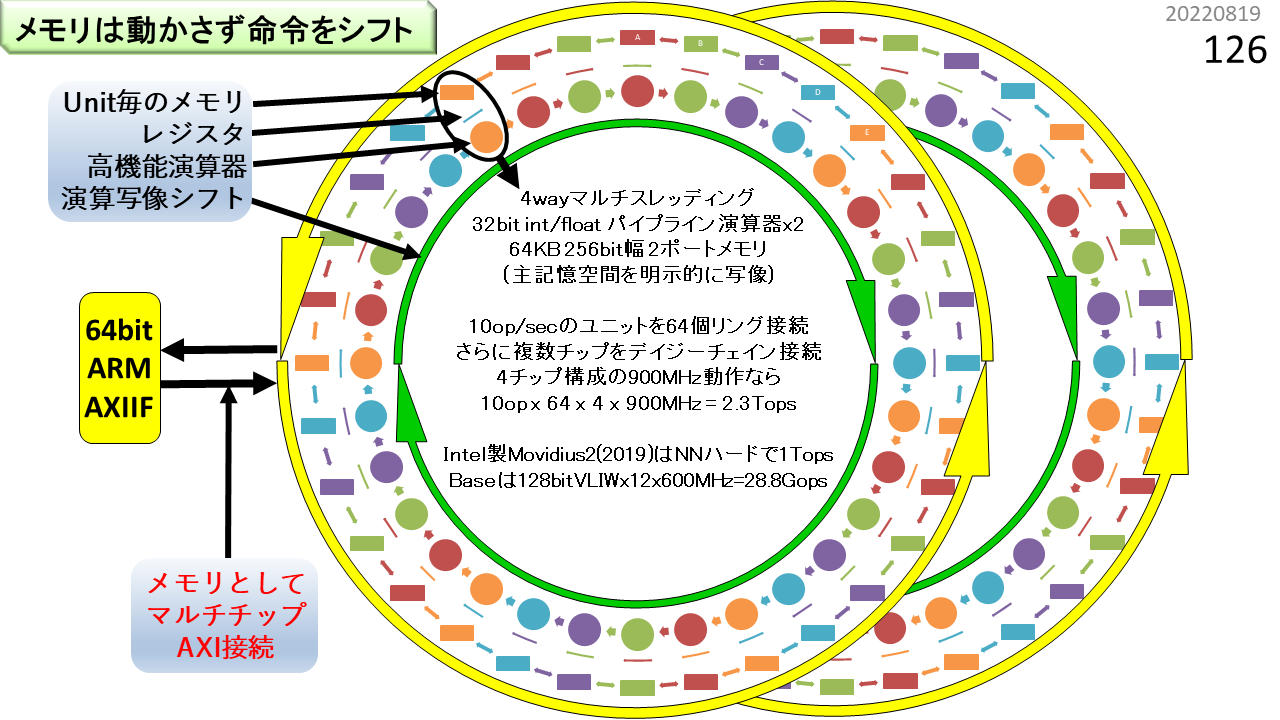
CGRAでは,メモリの内容を移動せず,代わりにALUにセットする機能を移動させることができます。図のようにALUとメモリの組をリング状に接続すると,メモリに対して,ALUにセットする機能をダイヤル錠のように回しながらデータ処理することもできます。1つのリングが1つのCGRAに対応していて,何基も繋げることで性能を上げることができます。実は,全体を1個の大きなLSIにするよりも,1つのリングを1個のLSIにしてたくさん繋げるほうが,製造時の分止まりが向上して価格が安くなります。IMAX2はこのような効果も狙っています。

そして,ローカルメモリを可能な限り再利用し,外部メモリとのデータ転送を削減する最適化が,コンパイラによって自動的に行われます。CGRAの場合,演算器ネットワークをどう埋め込むかばかり考えがちですが,それはアーキテクチャの視点からは完全に間違っています。何がボトルネックになっているかを正しく理解している人であれば,外部メモリとのデータ転送を一番に最適化するのが重要であるとわかっているし,それが王道です。
次のビデオは,物理1列のIMAXがどう動くかのアニメーションです。左側は縦に64個繋がったうちの1つのユニット,右側は2つのユニットを示しています。4枚のパワーポイントが入っています。ページが進むにつれて,小さな箱が,全体的には上から下に動きます。一方,いろんな場所から上に戻っていくデータもありますね。これが,さっきの回す仕組みです。

さて,CGRAの商用化には,様々な要求を満たす必要があります。上から順に,多くのアプリに対応できること,高速・小型であること,メモリバンド幅が狭くても性能が出ること,演算器を無駄に遊ばせないこと,レジスタが必要最小限であること,データ転送のコストを下げられること,プログラムのデバッグが容易であること,チップ数を容易に増やせる等の拡張性があること,ホストの改造が不要であること,コンパイル速度が速いこと,簡単にプログラムできること,仮想化に対応できることなどです。以前に,「非ノイマン型にも,使えるものと使えないものがある」と言いました。これらが揃っているのが,使えるコンピュータということです。特に,コンピュータと呼んで欲しければ,コンパイル速度だけは絶対に譲ることができません。技術者の時間は貴重です。作業のたびに,何十分か何時間かコンパイルが終るのを待っているなど,論外です。
[2022/01/20]むずかしいんですけどやめちゃだめですか?

だめです。離陸したので,出口はロックされています。まもなく垂直上昇するので,シートベルトして下さい。では,中級編のはじまりです。AIの入門レベルで必ず出てくる,画像識別プログラムを使って,学習と識別がどのようにIMAX2に実装できるかを考えます。
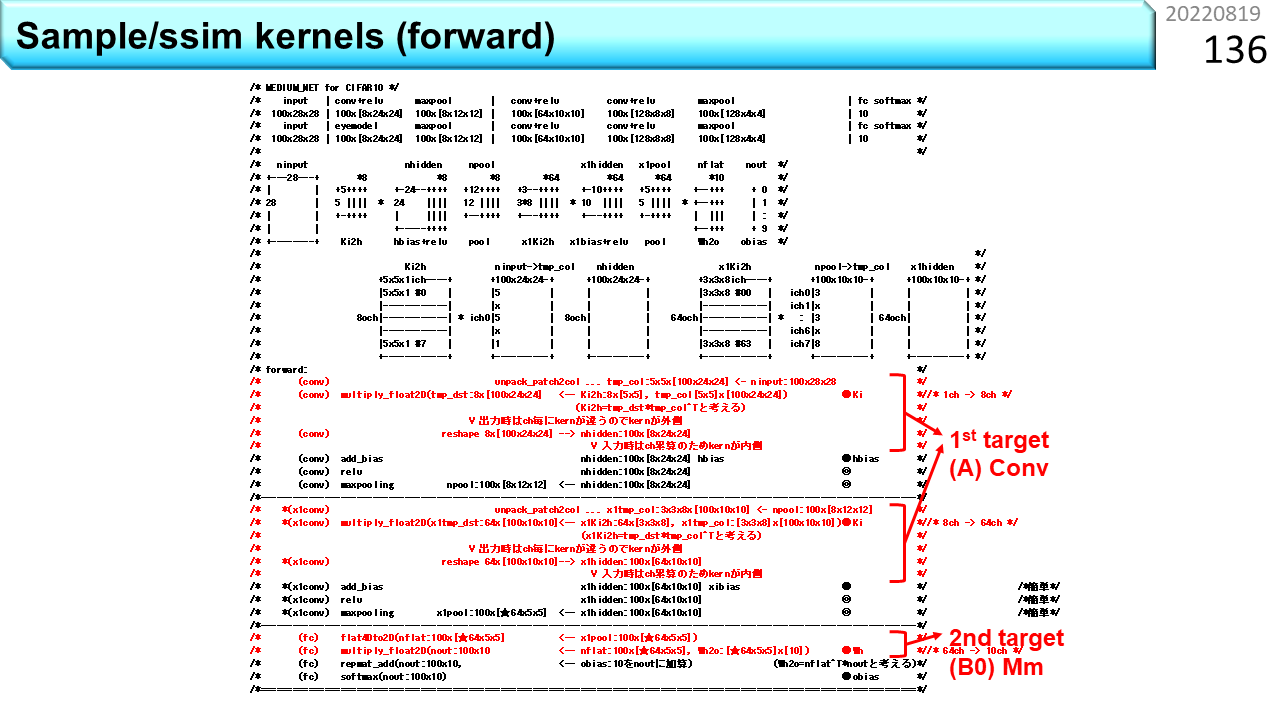
これは,ニューラルネットワークと呼ぶモデルです。Forwardは,未知の画像を入力し,何の画像であるかを識別するのに使います。なんのことやらわかりませんね。Pythonを知っている人は,ページ番号63のような,もっとわかりやすい書き方を知っていることでしょう。でも,中身はこういうものです。この一部分が,ページ番号64にあった畳み込みです。ブラックボックスに満足する人は,そもそも,ハードウェア設計に向いていません。Forwardの中で,計算量の大部分を占めるのが,畳み込み計算と全結合計算です。どちらも,変形すれば,ただの行列積を使って計算できます。行列積の形に書き直すスキルがあれば,ブラックボックスに頼ることなく,ハードウェアを設計することができます。

Backwardは,間違いを含む識別結果から入力画像に遡って,途中の計算に使う重みを調整するのに使います。この一部分が,ページ番号66でした。Forwardは,1回計算すれば識別結果が出力されます。でも,backwardは,元々計算量が多いことに加えて,何度も調整を繰り返す必要があるので,とても時間がかかります。
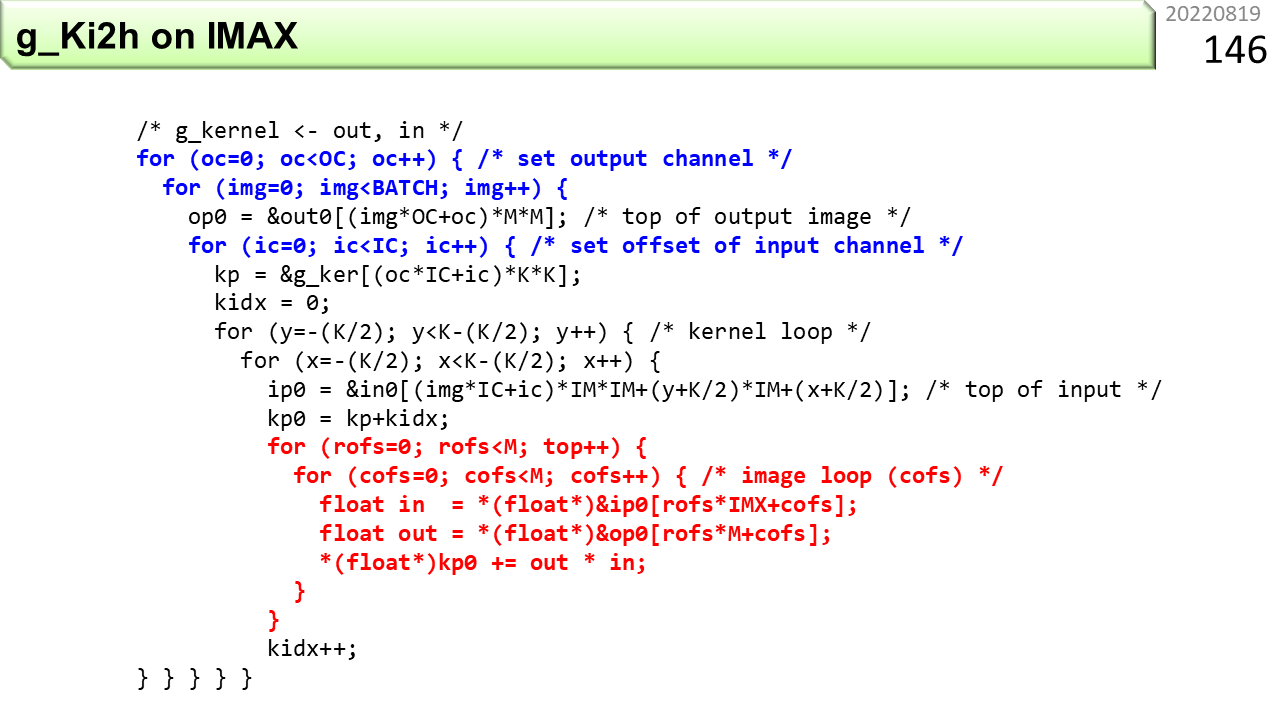
ページ番号65(64の次です。ビデオは番号1になるので)は,CPUやGPUの場合の畳み込み計算方法でした。データをあちこちにコピーし,整列しておく必要があります。この図は,IMAX2の畳み込みです。左下が画像データ,左上が重みデータで,CPU側にあります。CPUは,複数箇所へのコピーはせず,アドレス情報とデータを1度だけ,右のIMAX2に送信します。IMAX2の各ユニットは,アドレス情報を見て,自分に必要なデータであれば取り込みます。複数のユニットが同じデータを取り込めば,IMAX2の内部で複数箇所にコピーされたことになりますが,CPUから見れば手間は増えません。乗客が何人いようと,機内アナウンスで1回放送(broadcast)すれば,全員に伝わるのと同じです。コンピュータ用語でも,ブロードキャストと呼びます。その後,CGRAとしての連続演算が始まり,計算結果をCPU側に戻します。
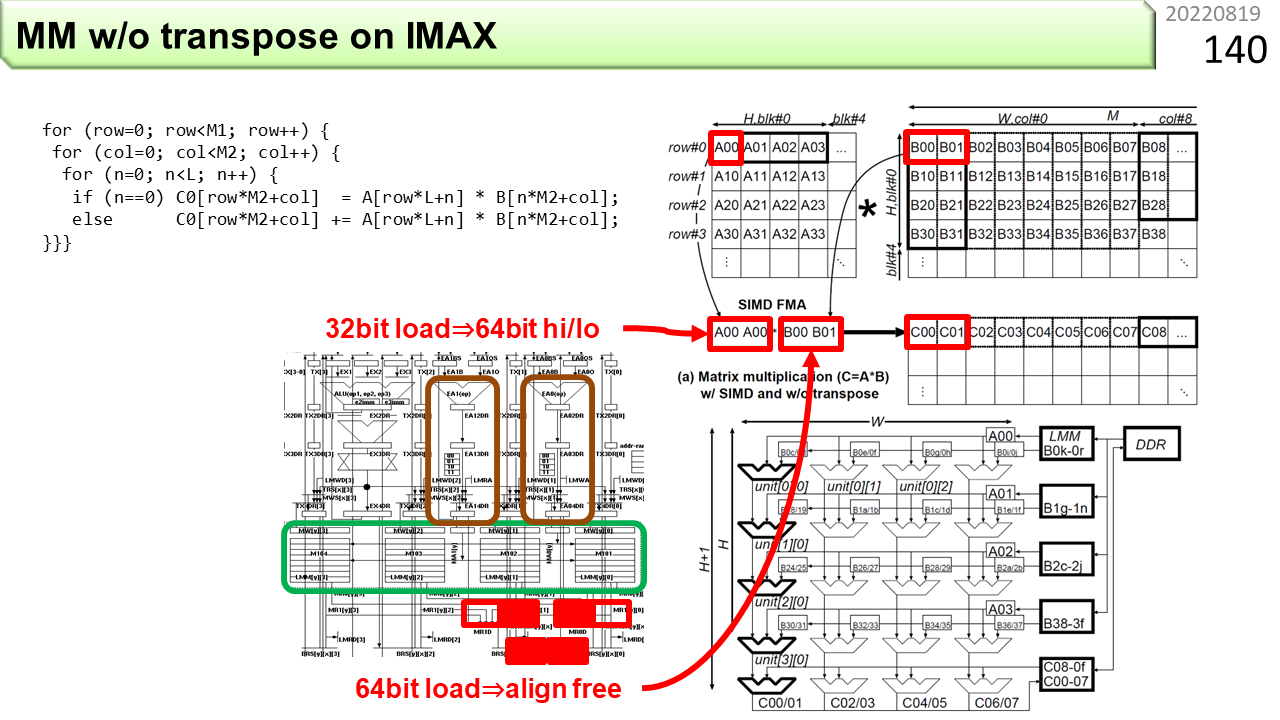
次は行列積です。IMAX2は,転置をせずに計算します。

ページ番号102では,IMAX2のプログラムを8行だけ見せました。この図は,CPUで動くプログラムに,IMAX2のコードを埋め込んだものです。C言語で書いてあります。上のほうは,CPUが実行します。そして,//EMAX5A beginと,//EMAX5A endで挟まれた,青字部分と赤字部分をIMAX2が実行します。ところで,CGRAは,あちこちが同時に動くハードウェアなので,ノイマン型のように,機械語命令が順番に実行されることを前提とした,ステップ実行などのデバッグ方法が使えません。そこで,IMAX2では,青字部分と赤字部分が,CPUでもそのまま動く仕掛けになっています。そうすれば,プログラムが思ったように動かない時に,アルゴリズムが悪いのか,IMAX2の使い方が悪いのかを区別することができます。アルゴリズムが正しいことをCPUで確認し,その後,IMAX2コンパイラを使って,IMAX2で動かします。
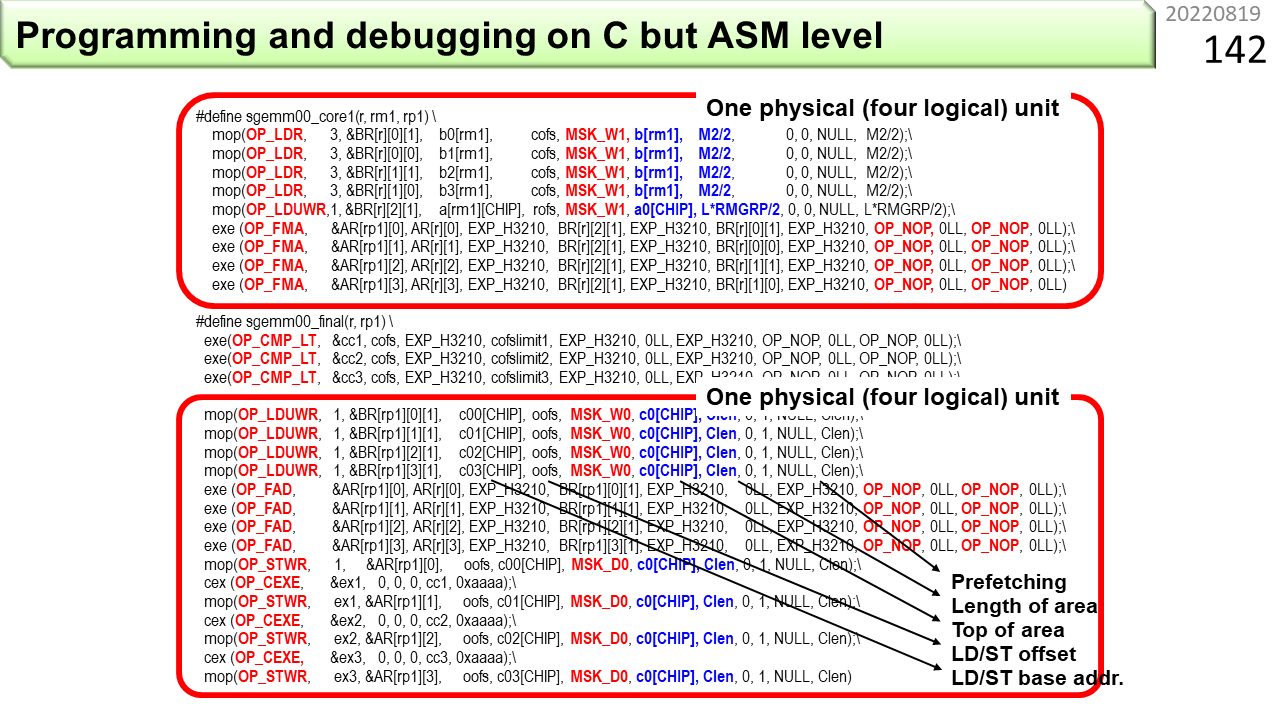
赤字部分には,マクロと呼ばれる記述が2種類入っています。上のsgemm00_core1は,IMAX2の中を縦方向に,下へ向かって積和演算を繋いでいく,ユニット毎の部品です。下のsgemm00_finalは,最後のユニットにセットされて,上から落ちてきた積和演算結果をメモリの内容に足し込みます。2つの赤枠部分が,それぞれ,CGRAの1行4列分の機能がある,IMAX2の1個の物理ユニットにセットされます。

ページ番号98では,あちこちが同時に動くハードウェアの動作確認には,タイミングチャートによる可視化が便利と言いました。同じように,あちこちが同時に動くIMAX2のプログラムも,変数がどのレジスタに対応付けられ,ユニット間をどのように流れていくかを可視化できると便利です。今まで,「機能をユニットにセットする」という表現を使いました。IMAX2コンパイラは,プログラムの赤字や青字の部分から,セットする情報を生成するついでに,線画で可視化したファイルを作ってくれます。ページ番号91にあったユニットの構造が横に4列並んでいます。これが,プログラムを書く際のIMAX2のモデルです。1つが論理ユニットに対応していて,ユニットの上端と下端には,レジスタが4本ずつしかありません。プログラマは,物理ユニットにレジスタが32本あることは気にせず,レジスタが4つある論理ユニットの世界で,プログラムを書きます。
黒い部分は,ハードウェアの機能を使っていないこと,紫は,3入力演算器が使われていることを示しています。左は行列積,右は畳み込みです。1行目と2行目に黒が多いのは,積和演算に必要なカウンタやアドレス計算を初期化しているためです。はじめのうちは,この図を見ながら,どう書いたら,どうなるのかをいろいろ試してみるのがよいでしょう。
同じように,重みに関するバックプロパゲーションをIMAX2用にアレンジしたのがこのプログラムです。これを元に,IMAX2用に書き換えていきます。書き換え後のプログラムは,あとでダウンロードできます。
図の下は,ページ番号66のように,同じデータをコピーしてデータを整列する手順ですが,IMAX2では,この作業を経由せず,元の複雑な形のデータのまま,直接,重みを計算することができます。
同様に,入力に関するバックプロパゲーションをIMAX2用にアレンジしたのがこのプログラムです。
さっきと同様に,図の下は,同じデータをコピーしてデータを整列する手順です。IMAX2では,この作業を経由せず,元の複雑な形のデータのまま,直接,入力を計算することができます。
[2022/01/21]もうむりですよぅ

現在,衛星軌道周回中です。景色を楽しんで下さい。ほら,あそこで氷床が盛大に崩れてますよ。カテゴリー5も暴れてますね。大富豪より,高校生をつれていくべきですね。百聞は一見にしかずです。大気圏に再突入して,着陸するまであきらめましょう。上級編のはじまりです。ここでは,具体的に,IMAX2のプログラムの書き方,動かし方,そして,IMAX2の現状の設計資産を手に入れた後で,どうやって自分用にカスタマイズしていくかの流れを説明します。

ここからしばらくは,IMAX2仕様書からの抜粋です。とりあえず最後まで書いて,時間があったら,ここに戻ってきて解説を追加します。


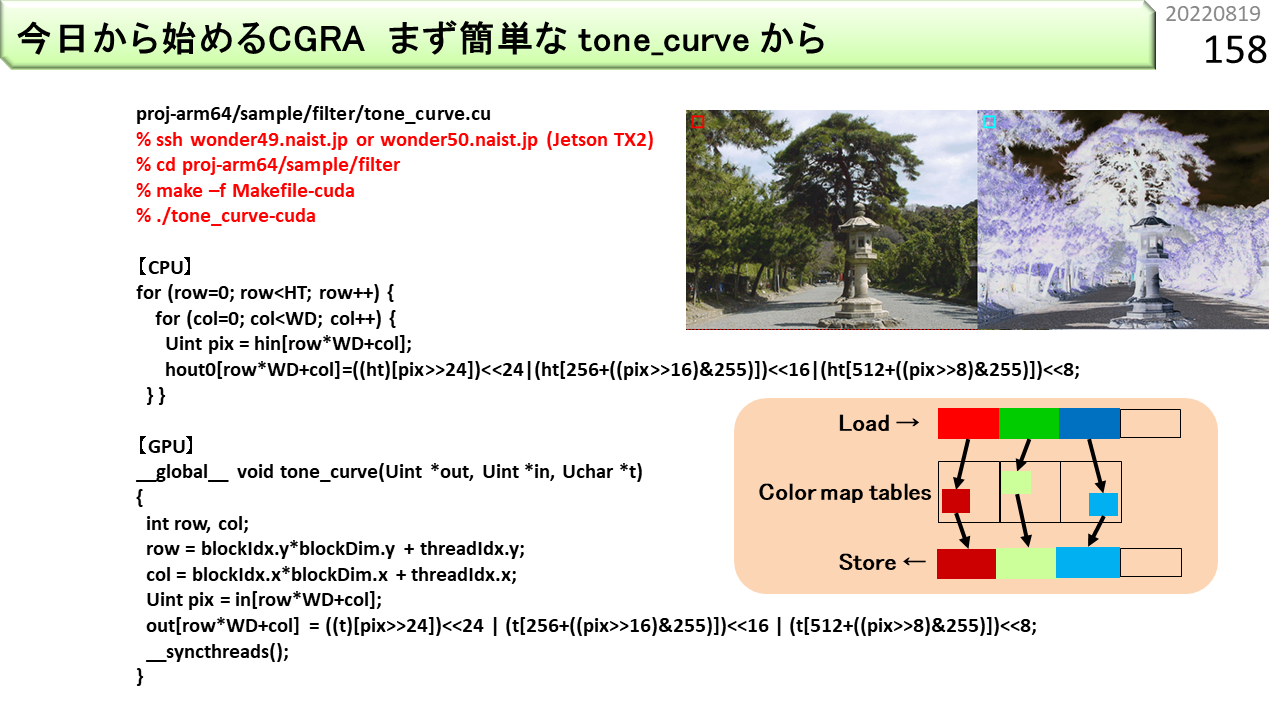
かなり飛びました。ここから続けます。色を入れ換える画像処理を例題に,プログラムを具体的に説明していきます。左画像を入力すると,右画像のように,色が変わります。どの色をどの色に変換するかは,色ごとの配列で定義します。赤字は,ダウンロードできるファイルの使い方です。CUDAが使えるGPUで動かせます。【CPU】の部分は,CPUで動くプログラムです。画像は2次元構造ですが,画素はメモリ上で一列に並んでいるので1次元配列を使い,制御には,あとでステンシル計算に対応できるよう,2重ループを使います。hin[]が入力画素,pixが処理中の1画素,ht[]が色変換表,hout[]が出力画素です。メディアンフィルタのところで説明したように,RGBの色成分は8ビットなので,シフト演算を使ってpixから各8ビットを取り出します。そして,各成分を使って色変換表を引き,最後に3色をつないで,出力のでき上がりです。【GPU】の部分は,このプログラムをCUDAに書き直したものです。CPUの最内ループの計算部分だけが入っていて,演算コアはこれだけ実行します。GPUは,たくさんの演算コアを使って,画像のあちこちを一斉に処理します。
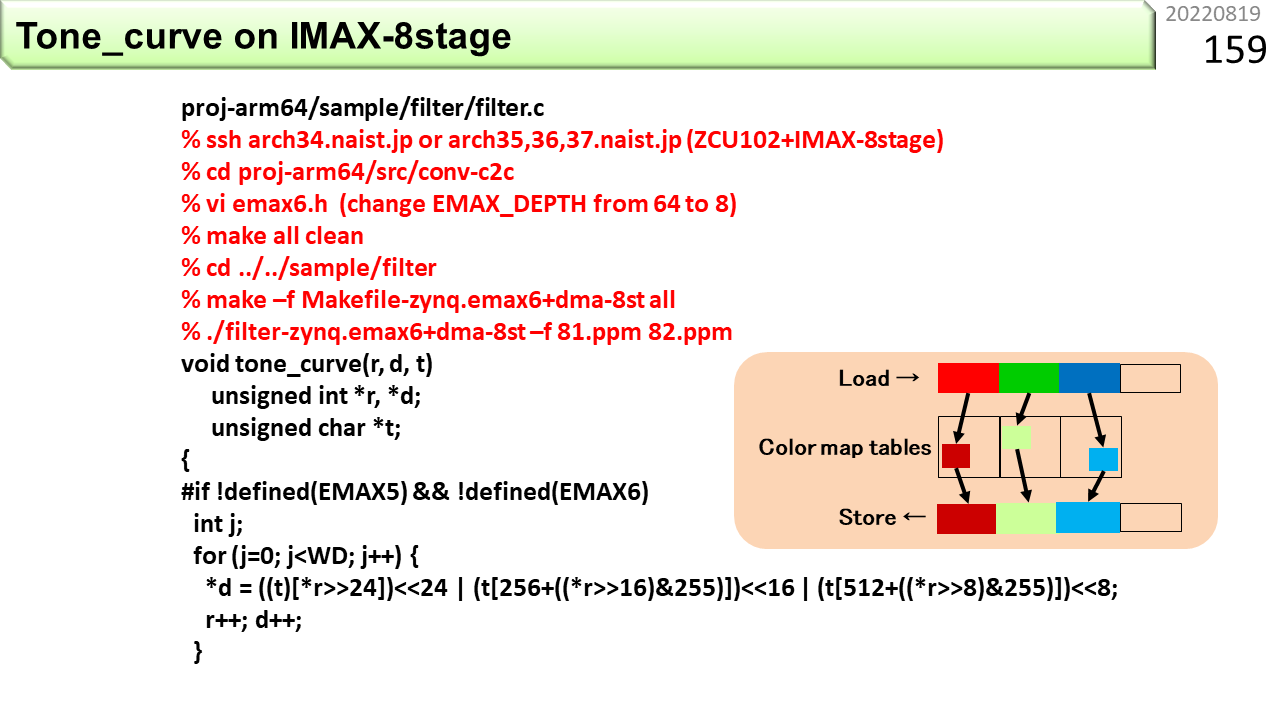
IMAX2で動くように書いてみましょう。まず,#if !defined(EMAX5) && !defined(EMAX6)から,#elseの前までは,参考に置いた,元のCPU用プログラムです。
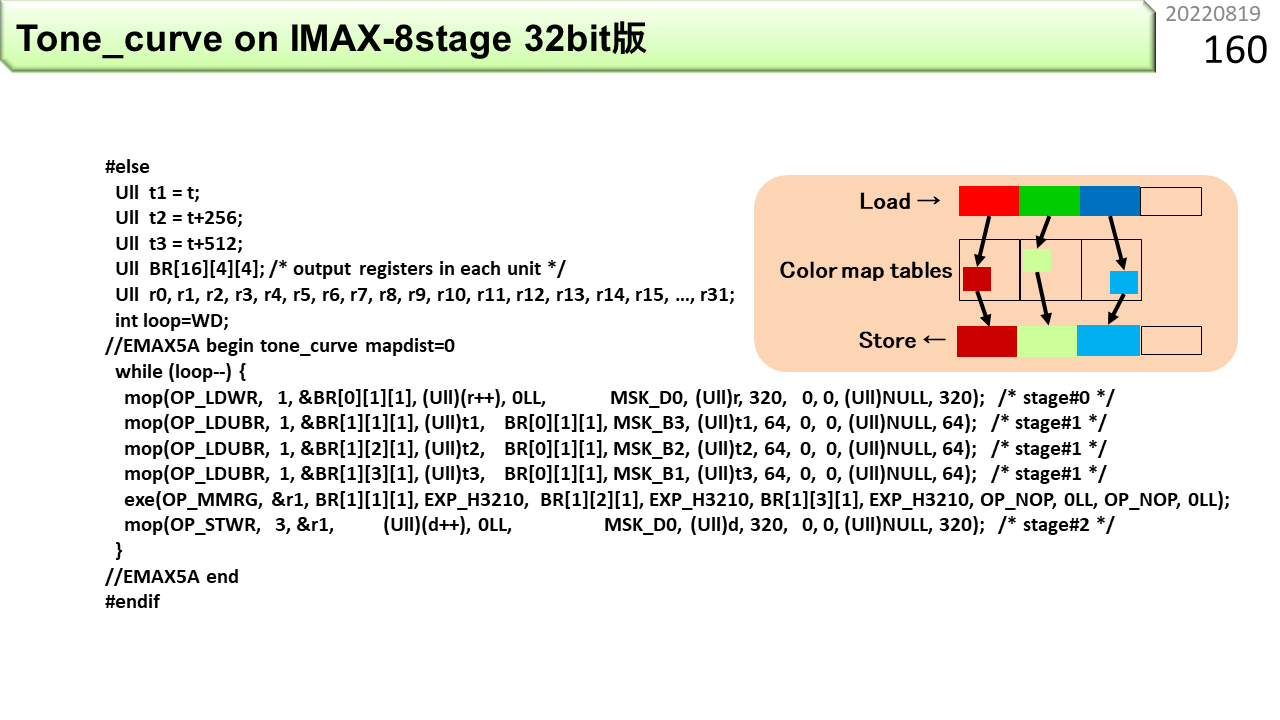
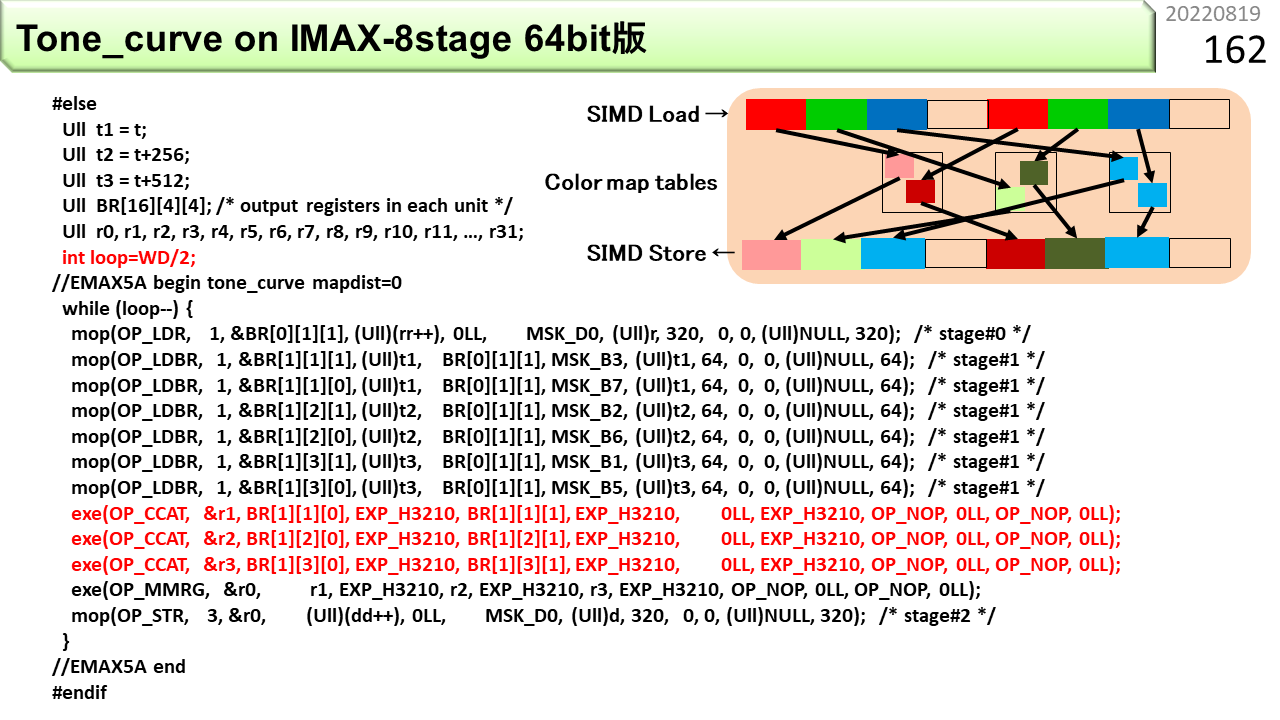
#elseから後ろが,CPUでもIMAX2でも動くプログラムです。//EMAX5A begin - endの間が,IMAX2コンパイラにより,IMAX2向けコードに変換されます。IMAX2コンパイラは,3重ループまで扱えますが,この例は,whileループを使った単純ループで書いてあります。使用する物理ユニット数は3です。最初のOP_LDWRは,先頭ユニットのローカルメモリから,32ビットの画素値を1つロードして,レジスタファイルBRの1つ,BR[0][1][1]に格納します。各BRは64ビットなので,下位32ビットに書き込まれ,上位32ビットは0になります。[0][1]は論理ユニット0行1列目,[1]は論理ユニット内レジスタの右から2番目を意味します。これが位置情報の具体例です。位置情報の代わりに好きな変数名も使えますが,次に可視化結果と対応づけて説明するので,今は位置情報を使います。続く3行のOP_LDUBRは,色変換表の先頭をベースアドレス,最初にロードした画素値の各色成分をオフセットとして,1バイトをロードし,各々BRに格納します。OP_MMRGは,3つの1バイトデータを繋げて,画素値に戻し,最後のOP_STWRが,32ビットデータを出力画素としてメモリに書き込みます。
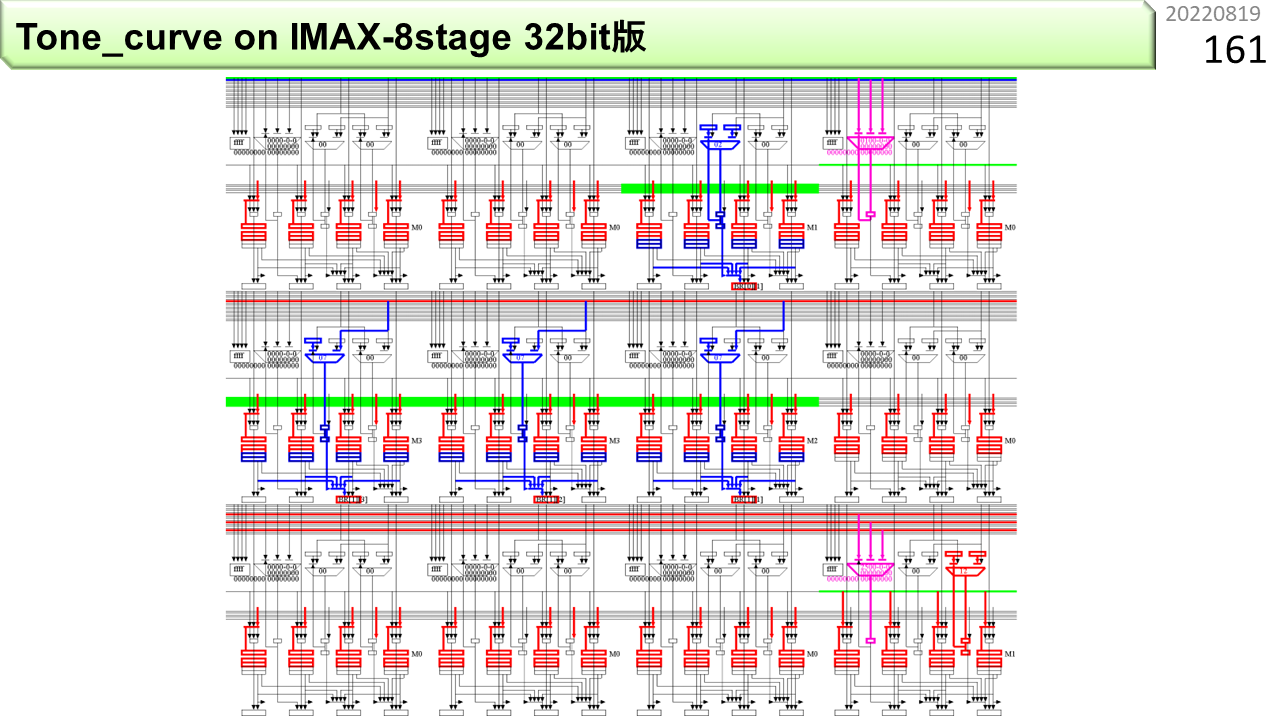
これが,IMAX2コンパイラが可視化してくれた,コンパイル結果です。右上端が第0行0列です。ここには,whileループのカウンタ初期値と,ALUを使う減算がセットされます。カウンタが0になったら,下のユニットに停止指示を出します。後続ユニットの動作が,順に止まっていきます。第1列には,最初のロード命令がセットされています。右から6番目の赤いBRレジスタに,BR[0][1]という名前が見えます。第0行1列のBRという意味です。ユニット内の位置は,見ればわかるので,表示されません。ロード結果はここに格納されます。第1行1列から3列に,OP_LDUBRがセットされています。そして,第2行0列に,OP_MMRG(紫のALU)とOP_STWRがセットされます。このプログラムは,第0行1列に入力画像,第1行1列から3列に色変換表を用意し,IMAX2を起動すると,第2行0列のメモリに,毎サイクル1つの出力画素を格納します。演算器内部だけでなく,ユニット間もパイプライン化されているので,毎サイクル結果が出てくるわけです。
さっきのプログラムは,64ビットレジスタの半分しか使っていません。もったいないですね。この図は,32ビットの画素値を2つロードすることで,処理速度を2倍に上げた64ビット版プログラムです。最初のOP_LDRは,先頭ユニットのローカルメモリから,32ビットの画素値を2つロードして,BR[0][1][1]に格納します。続く6行のOP_LDUBRは,色変換表の先頭をベースアドレス,最初にロードした画素値の合計6箇所の色成分をオフセットとして,1バイトをロードし,各々BRに格納します。3つのOP_CCATは,同色の2つの1バイトデータを各々1つのレジスタにまとめ,OP_MMRGが,3つのレジスタの内容をまとめて2つの画素値に戻し,最後のOP_STRが,64ビットデータを2つの出力画素としてメモリに書き込みます。IMAX2の実行回数も,画像の横幅(WD)の半分になるので,loop=WD/2になっています。
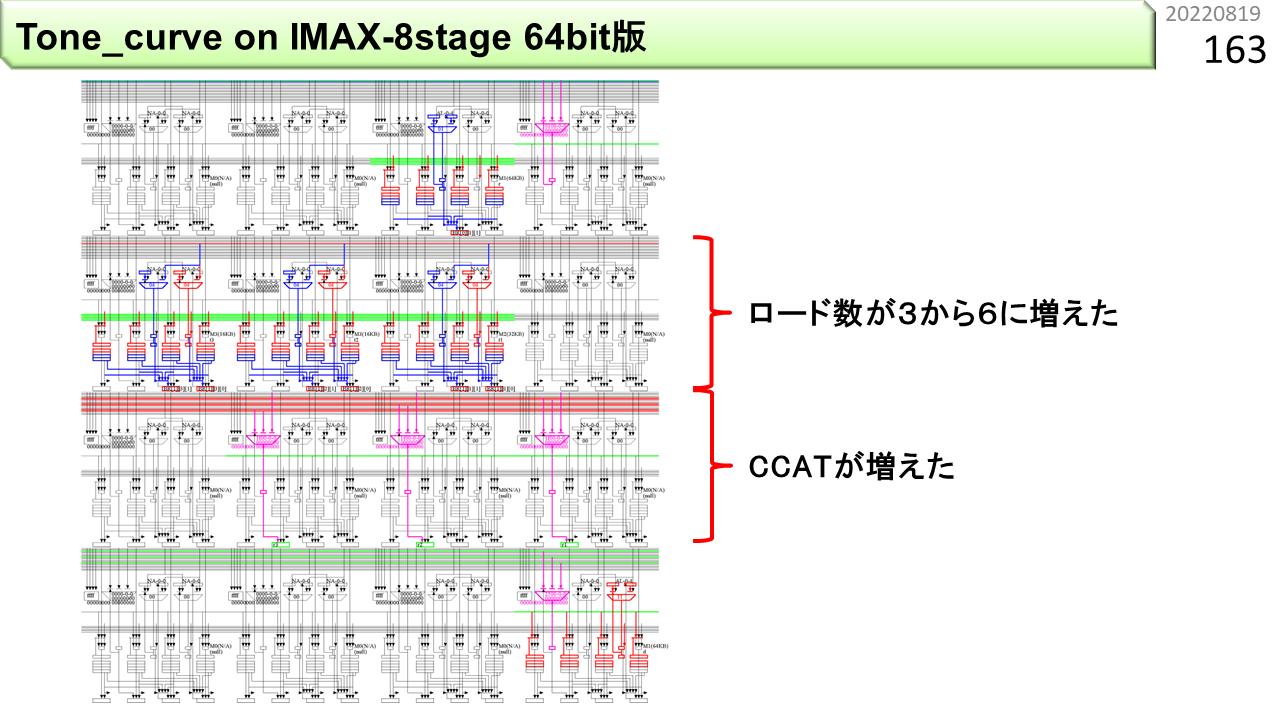
コンパイル結果です。右上端が第0行0列です。第0行は,さっきの32ビット版と同じです。第1行1列から3列に,OP_LDUBRが2つずつセットされています。デュアルポートメモリのおかげです。第2行0列から2列に,OP_CCATがセットされています。そして,第3行0列に,OP_MMRG(紫のALU)とOP_STRがセットされます。第3行0列のメモリに,毎サイクル2つの出力画素を格納するので,性能が2倍になりました。
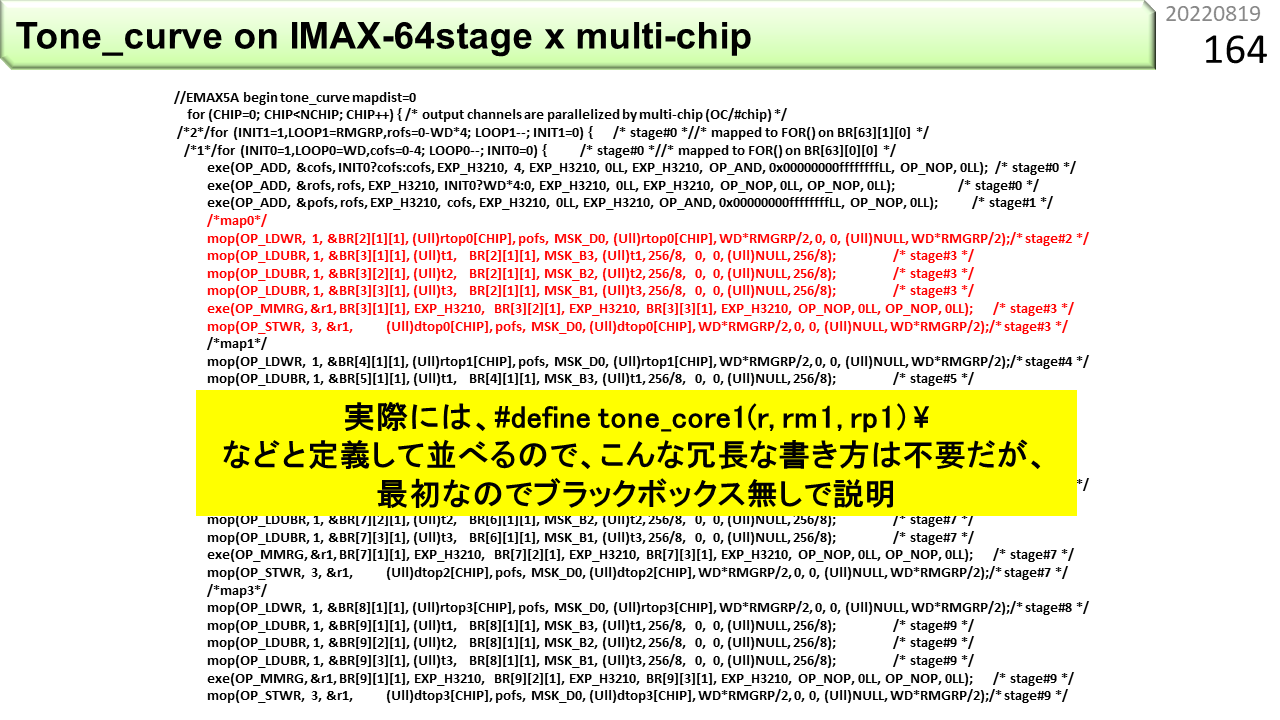
IMAX2には,1基あたり,64個の物理ユニットが入っていますが,今までの2つの例では,3個か4個しか使っていません。また,IMAX2の起動回数は,画像の高さHT=240と同じでした。いろいろもったいないです。そこで,同じ処理を残りのユニットにも割り当て,多くのユニットを使うことで,IMAX2の起動回数を減らすことを考えます。32bit版で作ったプログラムを10倍に増やしたのが,このプログラムです。長いので,後ろは省略です。また,プログラムの構造が,whileだけの単純ループではなく,3重ループになっています。IMAX2が4基参加し,10個の物理ユニットが各々2重ループにより,幅方向WD,高さ方向6の画像を一度に処理するようにします。これで,IMAX2の起動回数は何回になったでしょう。240/4基/10ユニット/6=1なので,起動回数はわずか1回になりました。

コンパイル結果です。第0行と第1行は,3重ループの制御とアドレス計算に使われています。第2行から第4行に,さっきの32ビット版が埋め込まれているのがわかります。10倍にふやしたので,物理ユニットは,3x10=30必要でしょうか。いいえ,違います。よく見ると,第2行から第4行に対応するデータフローと同じ形が,第5行から第7行ではなく,1つ手前の,第4行から第6行にあります。つまり,コードを10倍に増やしても,論理ユニットに空きがあれば,一部オーバラップできるということです。全体では,22個の物理ユニットにおさまります。まだまだ物理ユニットが空いていますね。4バイトの1画素は,320x6でも8KB未満しかないので,64KBのローカルメモリも大部分が余っています。物理ユニット数64というのは,少ないように感じるかもしれませんが,まだまだ余力があります。
[2022/01/21]どうやってコンパイルするんですか?
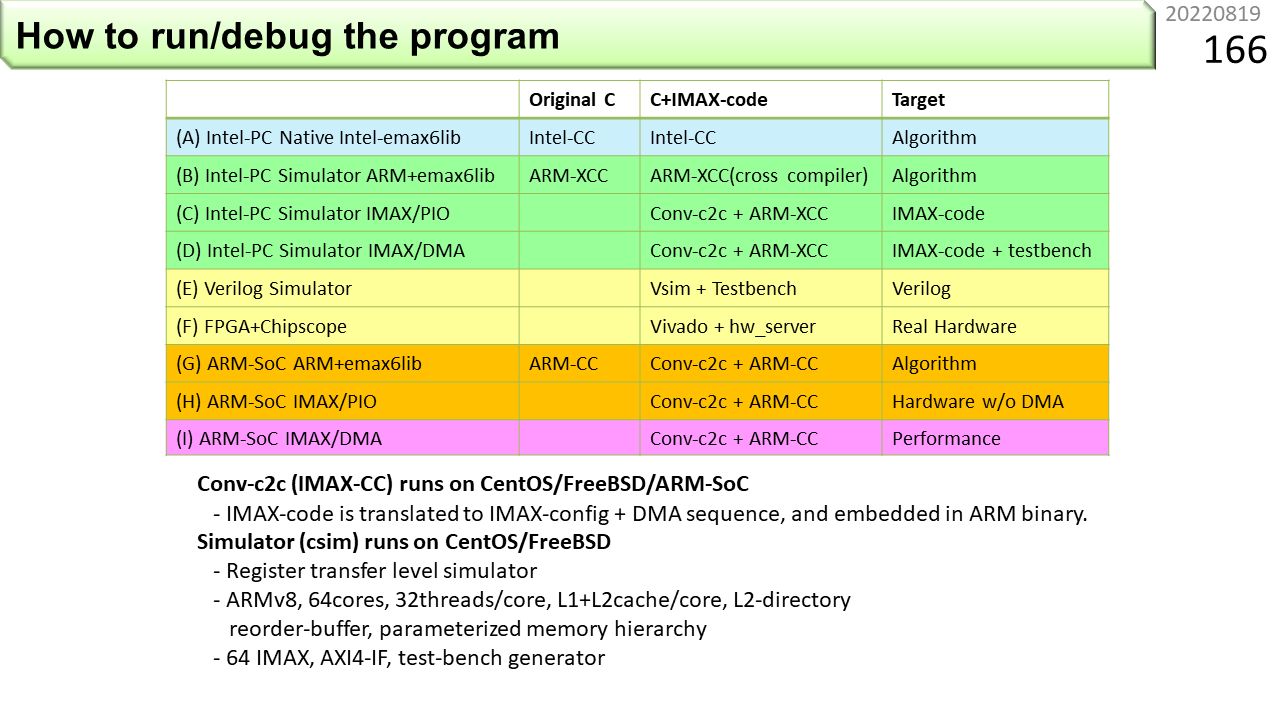
だいたいの感じがつかめたところで,今度は,IMAX2のプログラム開発環境について説明します。以前に説明したように,CGRAプログラムのデバッグは,ノイマン型のようにはいかないので,いろいろな実行方法が必要です。一発で動けばいいですが,動かない場合,どこで何がおこっているのかわからなければ,手も足もでません。この表は,実行方法の一覧です。本格的なCGRAの環境としては,これ以上のものはないと思います。(A)では,以前に説明した,//EMAX5A beginと,//EMAX5A endで挟まれた部分をCPUで動かします。IMAX2コンパイラは,前に列挙した命令テンプレートをIMAX2の制御データにコンパイルしますが,このテンプレートは,C言語の関数呼び出しと全く同じ形式です。IMAX2機能のC言語ライブラリが用意されているので,IMAX2コンパイラを使わずに,通常のCコンパイラとCPUを使って,そのまま動かすことができます。この段階で正しく動かなければ,IMAX2コンパイラを使っても無駄です。
(B)から(D)では,ARMv8のクロスコンパイル環境と,ARM+IMAX2シミュレータを使って,段階的に動かします。シミュレータを使えば,各ARM機械語命令の動きや,IMAX2の物理ユニットの動きを全て再現するので,内部で何が起こっているかを調査することができます。(B)は,(A)のCPUをIntelからARMに変更しただけです。IMAX2機能C言語ライブラリを使い,ARM機械語命令のみで実行します。ARM特有の問題があれば,ここで解決しておきます。(C)は,IMAX2コンパイラを使って,ARM機械語命令にIMAX2コードが埋め込まれたものを実行します。この時,CPUのDMA機能は使わず,ロードストア命令のみによって,IMAX2とのデータ送受を行います。送受する個々のデータをprintf()等により確認することができます。(D)は,フルスピードの実機と同じく,DMA機能を使ってデータ送受します。
(E)と(F)では,シミュレータよりも正確に,IMAX2のハードウェアの内部動作を確認できます。プログラマが使うことは,あまりありませんが,最初に言ったように,プログラマがハードウェアも開発する局面では,必須のスキルです。(E)は,Verilog言語で書かれたIMAX2の設計情報を回路レベルでシミュレーションします。配線レベルの動作を確認できますが,シミュレーション速度はとても遅いので,大きなプログラムを走らせることは,ほぼ不可能です。(F)は,実機の中から指定した配線の波形を取り出して可視化してくれます。ただ,FPGA内部のメモリを流用するので,短い時間の波形しか観測できません。
(G)から(I)は,(B)から(D)をシミュレータから,ARMの実機に置き換えたものです。まとめると,(I)が最終実行形態ですね。運が良い人は,いきなり(I)で試しましょう。動かなかったら,遡って,いろいろ試してデバッグするのもよい方法です。でも,実機が少ない場合は,みんな試してみたくて,取り合いになります。一発で動く確率を上げてから試したほうが,取り合いにならないですね。前に「これ,いくらするんでしょうね」と言いました。何台も買える人は,なかなかいないでしょう。だから,(A)から(I)までの,様々な方法が必要になるという側面もあります。慣れてきた人には,(A)⇒(I)⇒(D)⇒(I)の順序がお勧めです。
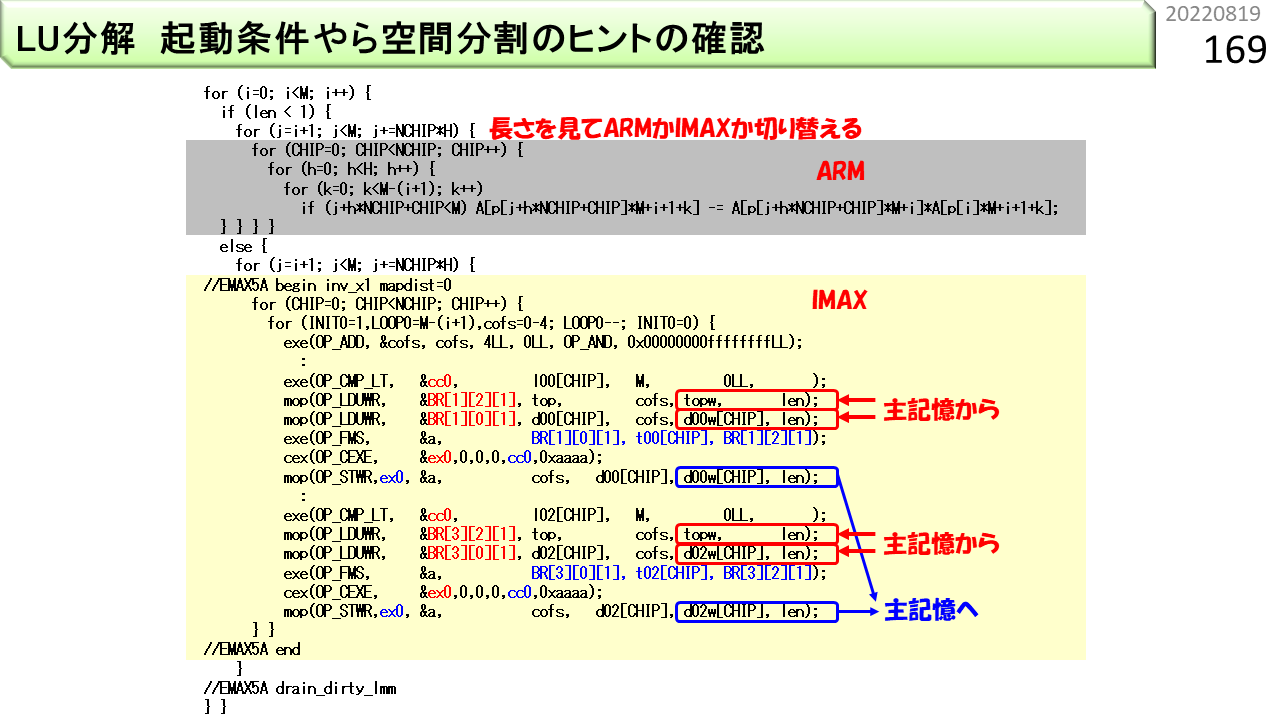
実際のプログラムでは,扱うデータ量が必ずしも大きくないことがあります。たとえば,この図は,連立一次方程式を解く際に使われるLU分解です。三角行列を扱うので,IMAX2が連続動作できる時間に大きなばらつきが出ます。データ長が短いと,CPUのほうが早く終わることもあります。このような場合は,CPUで動かす部分と,IMAX2で動かす部分を両方用意して,長さに応じて切り替えるのがよいです。
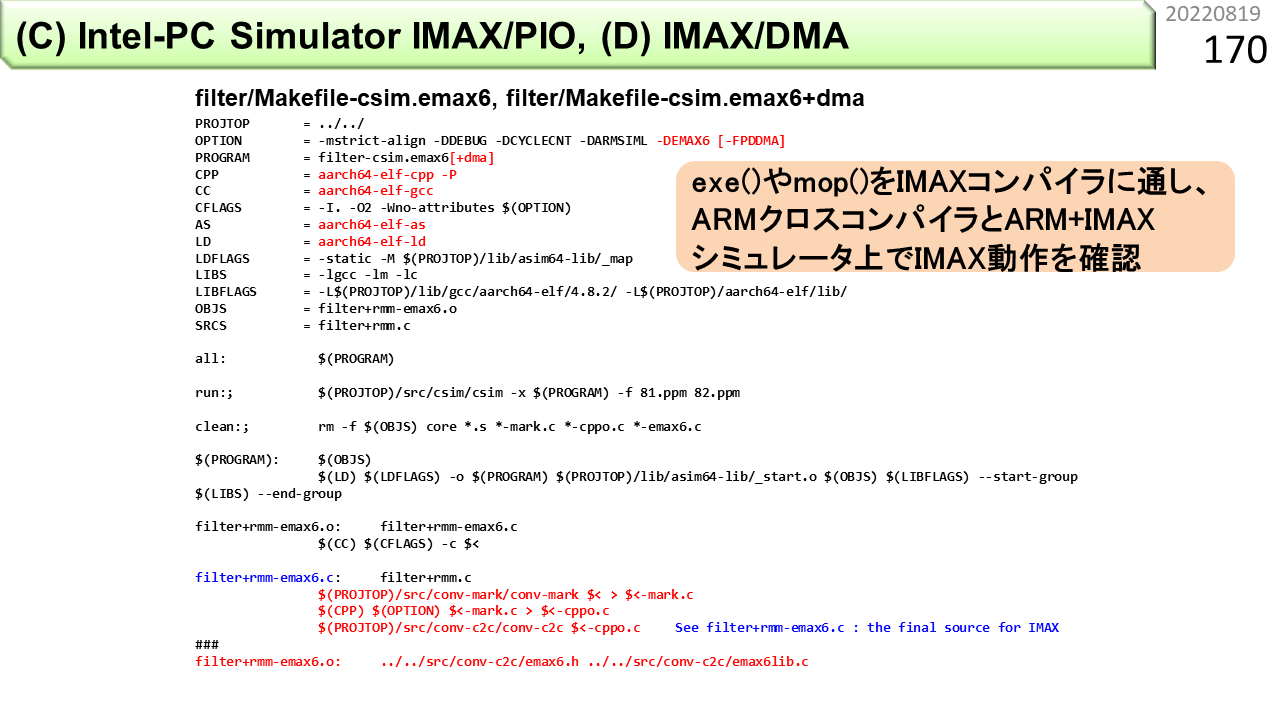
では,ここからは,コンパイル過程と,コンパイラの仕組みです。図は,(C)と(D)で使う,Makefileの内容です。Makefileは,ソースプログラムから,実行形式ファイルを生成する際の手順を書いておくことで,コンパイル作業の自動化ができるファイルです。UNIXに詳しい人は,これを見るのが正確ですが,高校生は見慣れないでしょうから,次のページから順に説明します。
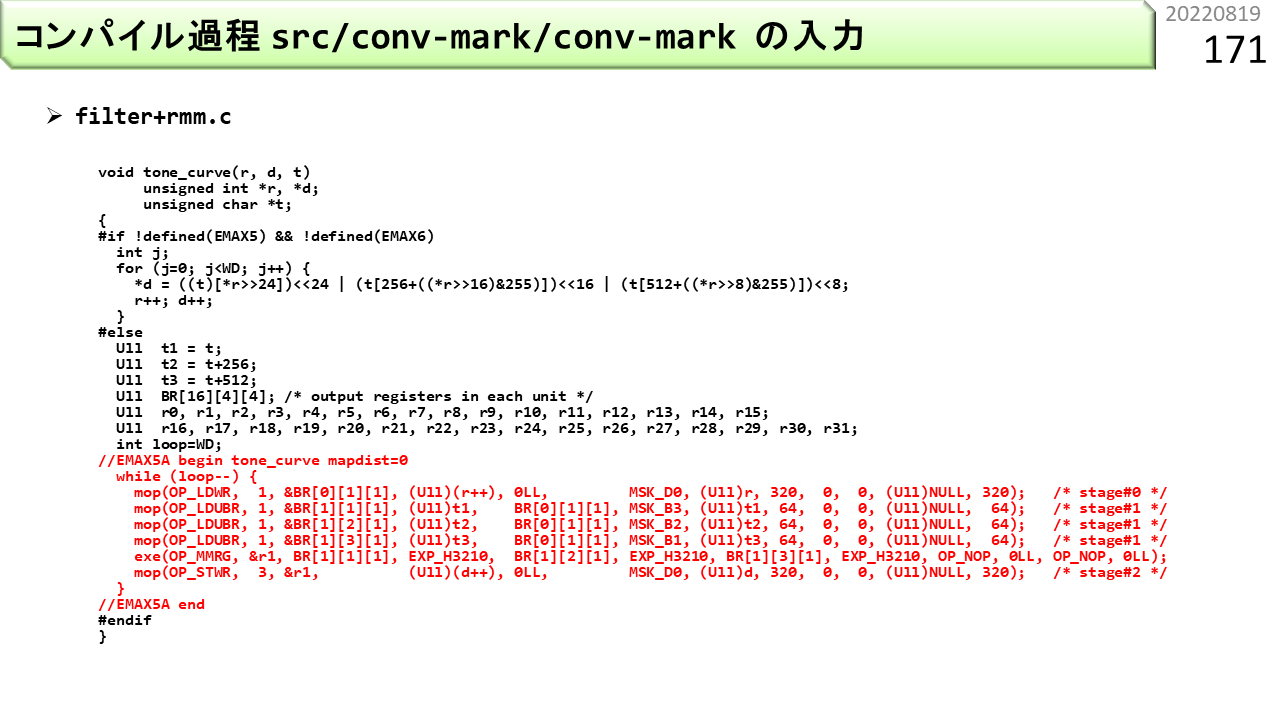
これは,前に使った,色を入れ換えるプログラムです。ファイル名は,filter+rmm.cです。IMAX2コンパイラは,いくつかの手順を使って,赤字部分を変換していきます。まず,conv-markが変換します。
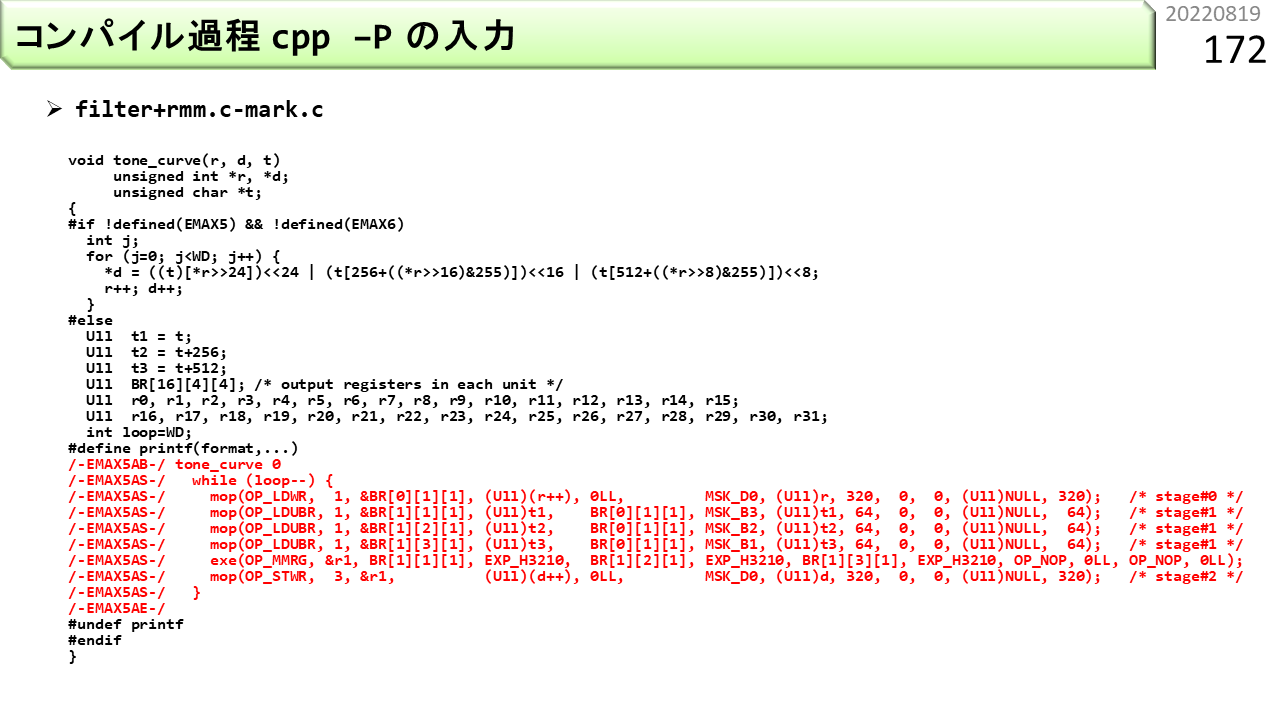
変換結果です。行の頭に,/-EMAX5AB-/という修飾が付いたり,中身が少し書き換えられています。次に,cpp -Pが変換します。
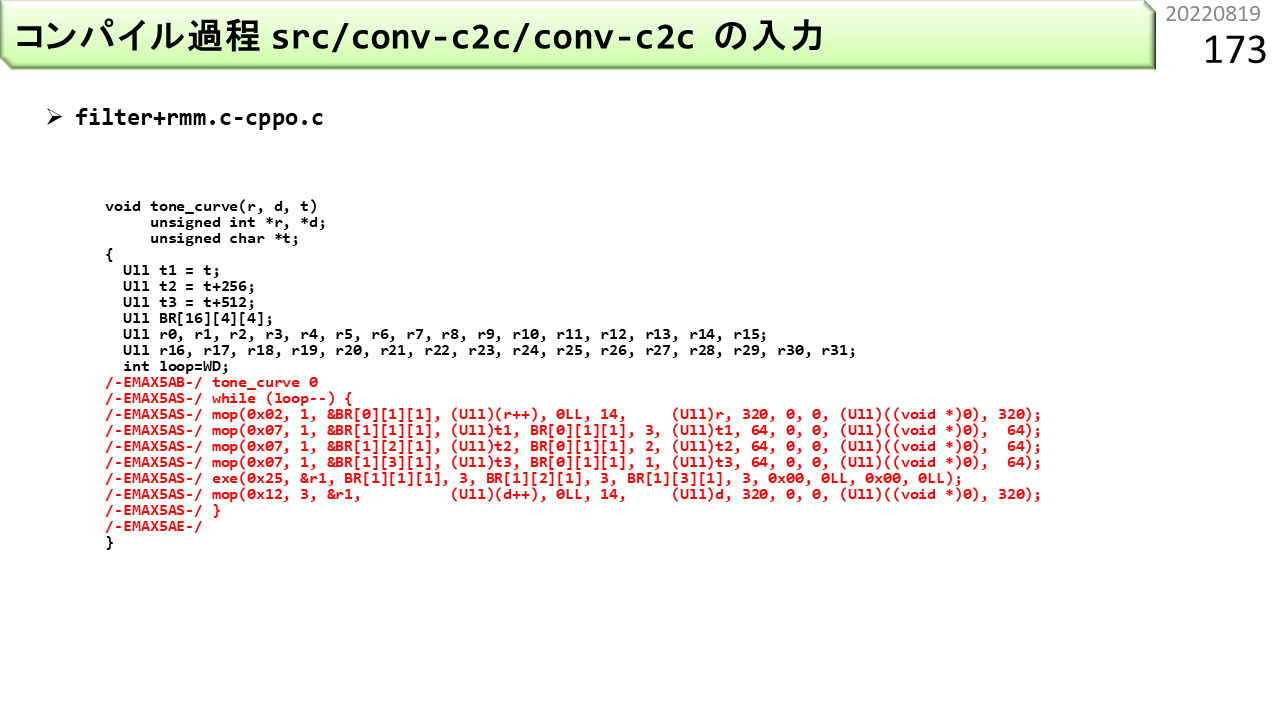
変換結果です。#ifの部分がなくなりました。次に,conv-c2cが各行を解釈してIMX2コードを生成します。

変換結果です。whileループの構造が消え,行数が増えて,一気に変わりました。各ローカルメモリの担当範囲の抽出,前回演算結果の回収,という具合に,IMAX2を使うために必要な準備が,CPUコードとして入りました。

さらに,4列分の論理ユニット機能を物理ユニットにセット,初期値をレジスタファイルへセット,担当範囲情報を各ローカルメモリへセットします。

最後に,ローカルメモリへのデータ送信,IMAX2の起動,同時に次データの送信を行い,IMAX2の動作完了を待ちます。残りは,IMAX2が生成した制御情報です。
この動画は,LAPPのハードウェアが,上から流れ込んでくるVLIWをデコードし,レジスタ間依存関係に基づいて,CGRAの演算器間ネットワークをセットしていく様子です。IMAX2では,同様の方法により,コンパイラがユニット間接続情報を生成します。
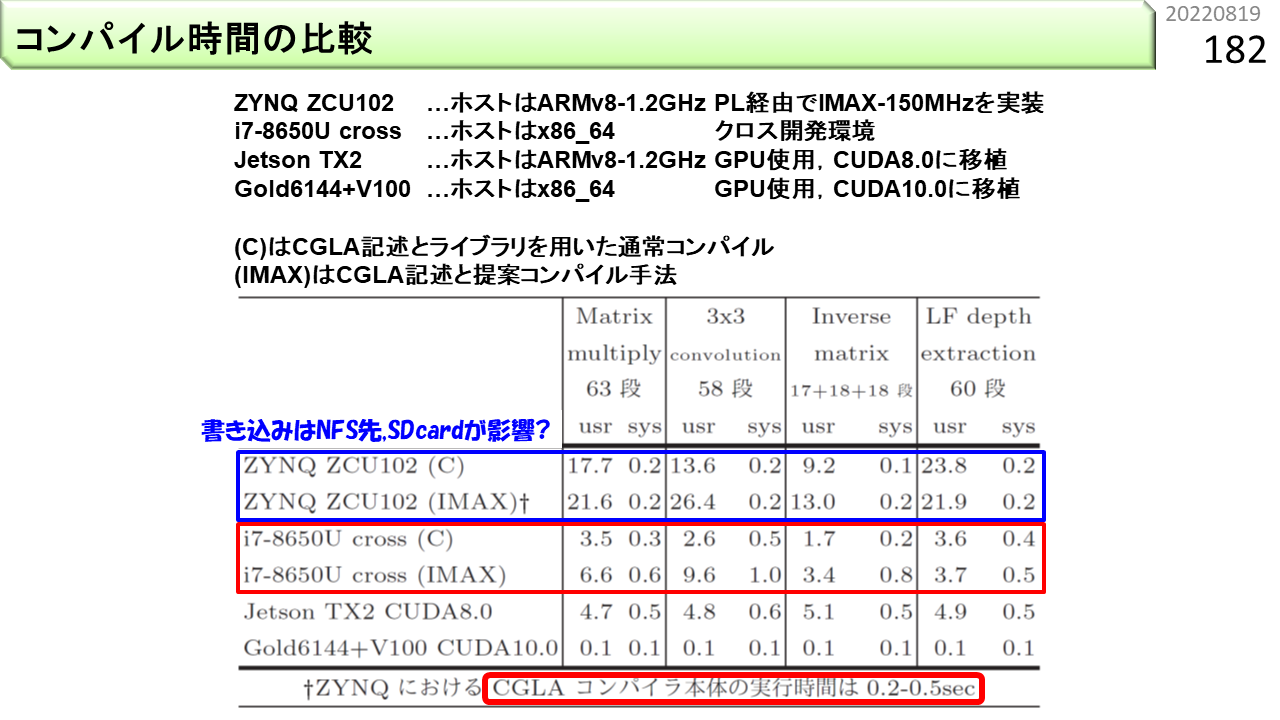
以前に,FPGAとCGRAは,再構成の粒度が違うと言いました。ソースプログラムを入力として,FPGAコンパイラはゲート間接続情報,CGRAコンパイラはユニット間接続情報を生成します。 FPGAの場合,IMAX2程度の大きな回路だと,合成に24時間以上かかります。一方,IMAX2のコンパイル時間は,IMAX2機能C言語ライブラリを使う場合でも,IMAX2コンパイラを使う場合でも,数秒です。
[2022/01/22]プログラマでおわるのはだめですか?

ここまでは,プログラマとしての,IMAX2の使い方でした。プログラマでおわるのもいいでしょう。でも,それが許されるのは,ノイマン型コンピュータまでです。ノイマン型には,もう進化の余地がないし,今のスキルは,いずれ小学生に追い越されます。現状の非ノイマン型の使い方だけ勉強したところで,焼け石に水,東南海大地震に堤防です。ここからは,コンピュータ開発者としての,IMAX2の改良も含めた使い方です。

2.のNo-CGRAモードを試すには,IMAX2機能C言語ライブラリに,機能を追加します。具体的には,conv-c2c/emax6lib.cに,記述を追加します。例えば,浮動小数点積和演算を追加する場合は,このように書きます。シミュレータに対する機能追加と同じです。

3.のコンパイラ機能追加は,conv-c2c/emax6.cに,記述を追加するだけです。しかも,具体的機能は,すでにemax6lib.cに追加したので,命令スケジューラに,OP_FMAとOP_FMSの存在を教えるために,赤字部分を追加するだけです。
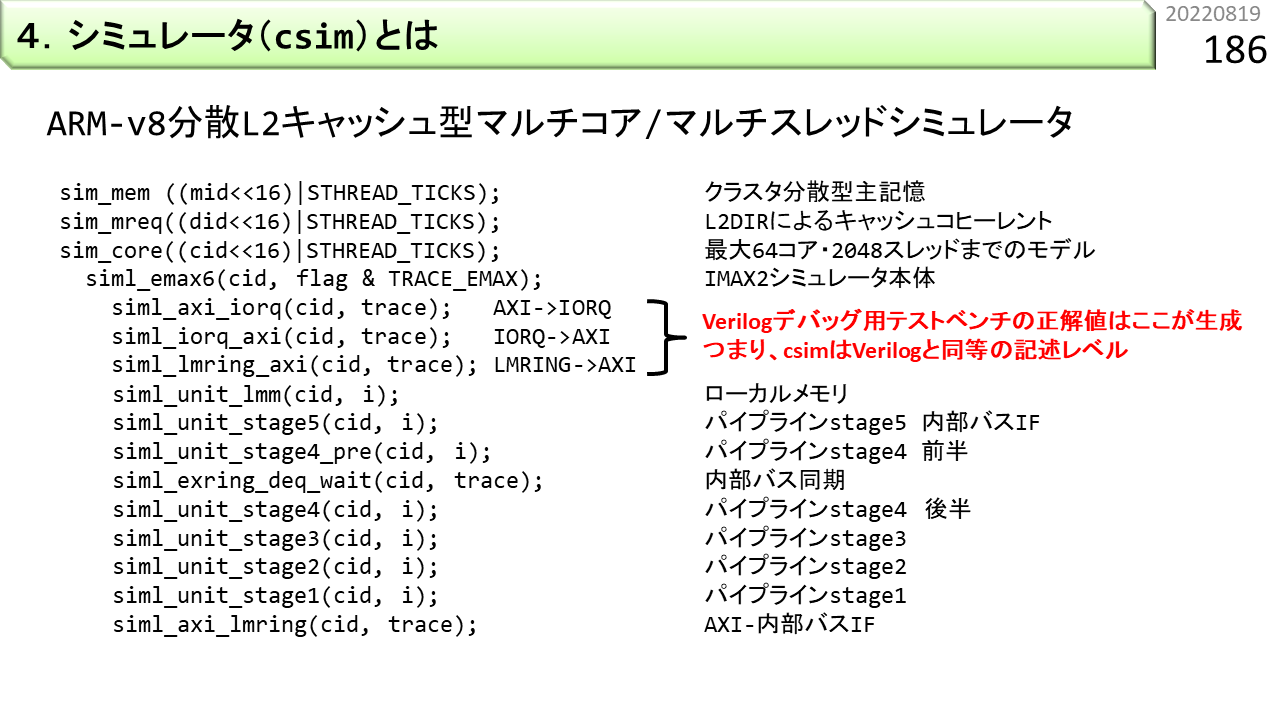
4.のシミュレータ機能追加は,emax6lib.cへの記述追加により,すでに終わっています。シミュレータを再コンパイルするだけで,追加機能が使えるようになります。ここでは,シミュレータ(csim)について説明します。IMAX2は,CPUにスレーブ接続されるため,単独ではプログラムを動かすことはできません。つまり,csimは,ページ番号150で説明したように,ARMv8とIMAX2の機能,および,AXIインタフェースの全てをシミュレートします。1つのARMv8コアに,1基のIMAX2が接続されるモデルになっていて,図のような粒度でシミュレーションをします。
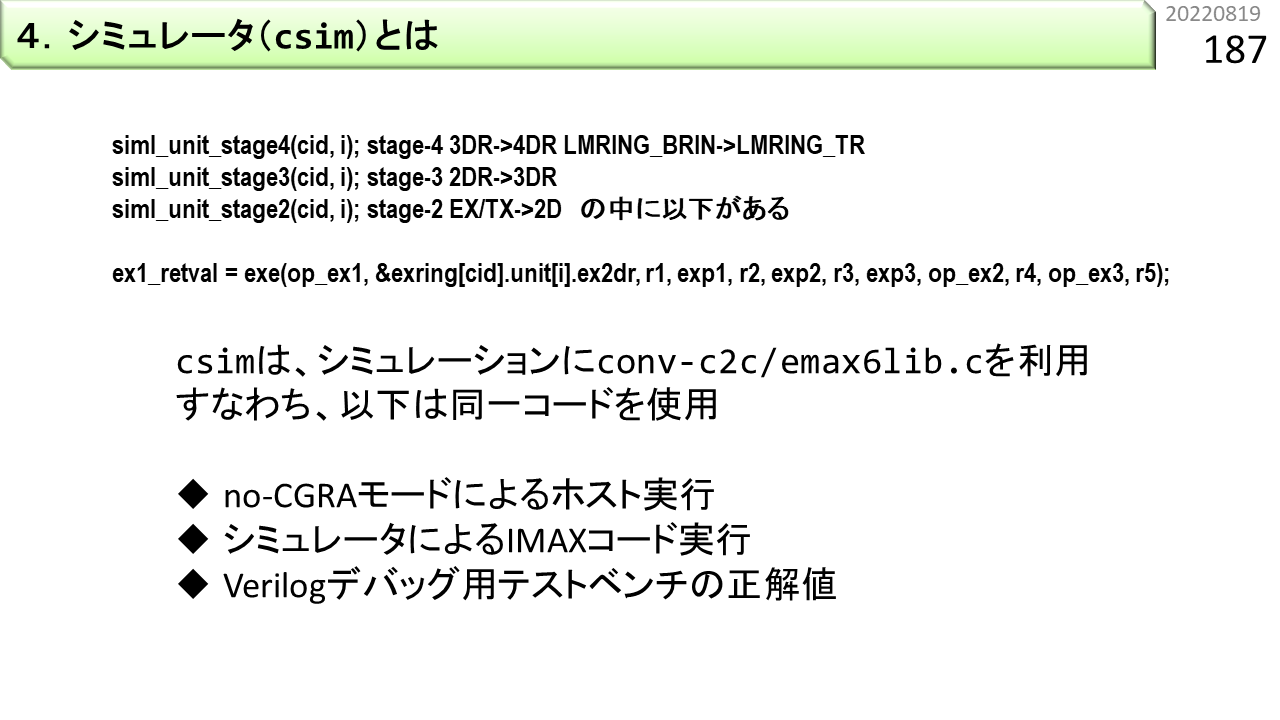
すでに説明したemax6lib.cは,siml_unit_stage4,siml_unit_stage3,siml_unit_stage2の中から呼び出されて,シミュレーションに参加します。おさらいすると,emax6lib.cに追加した機能は,No-CGRAモード,csimによるシミュレーション,さらに,あとで説明する,テストベンチの正解値生成に使用されます。
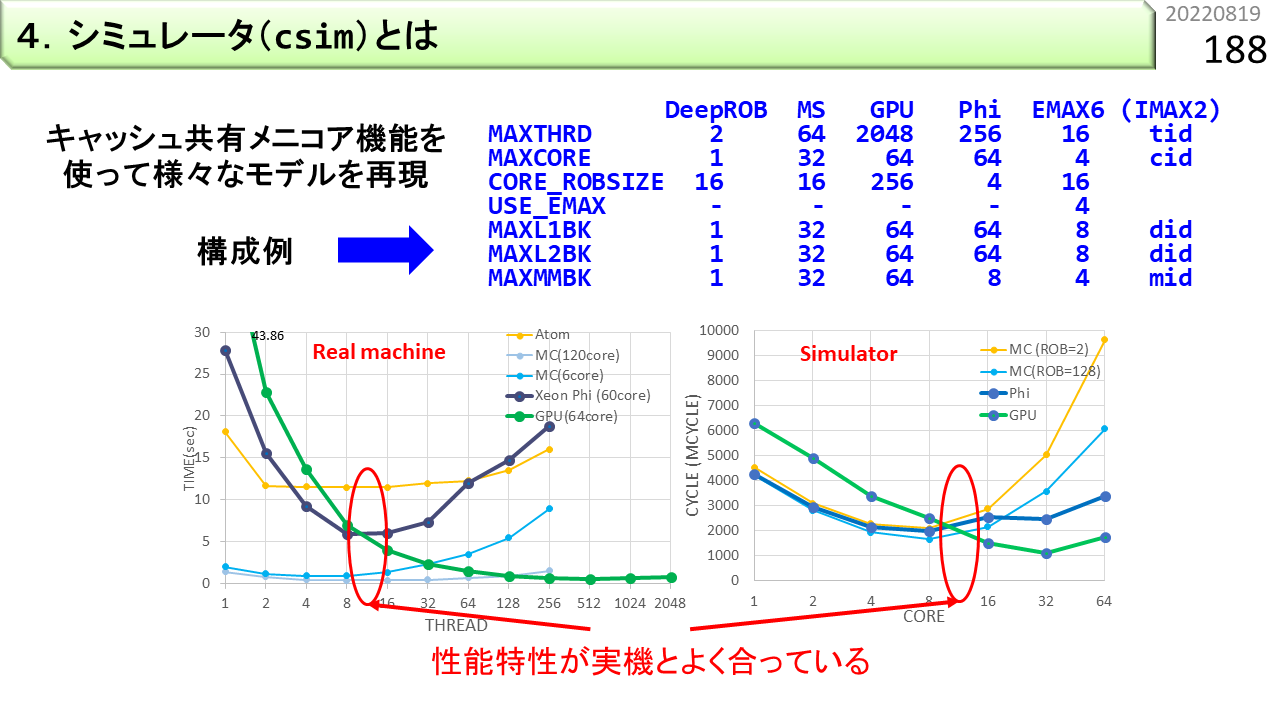
Csimには,ARMv8の機能として,スーパスカラ,マルチスレッド,分散L2キャッシュ,マルチコアの機能が入っており,プログラムの高速化に効くのが,スーパスカラか,マルチスレッドか,マルチコアか,アクセラレータか,あるいは,どのような組合せが最適であるかを比較検討できるようになっています。このグラフは,csimのパラメタを変更するだけで,GPUや,XEON/Phiを含む,様々なコンピュータをモデル化できることを示しています。横軸は,コア数,縦軸は,プログラムの実行時間です。左のグラフは,実機での測定結果,右のグラフは,csimでの測定結果です。性能が交差する部分のコア数が,見事に再現できています。

ここからしばらくは,プログラムをcsimで動かして,動作をチェックする手順です。



だんだん,説明が手抜きになってきました。技術セミナーで,詳しく説明します。
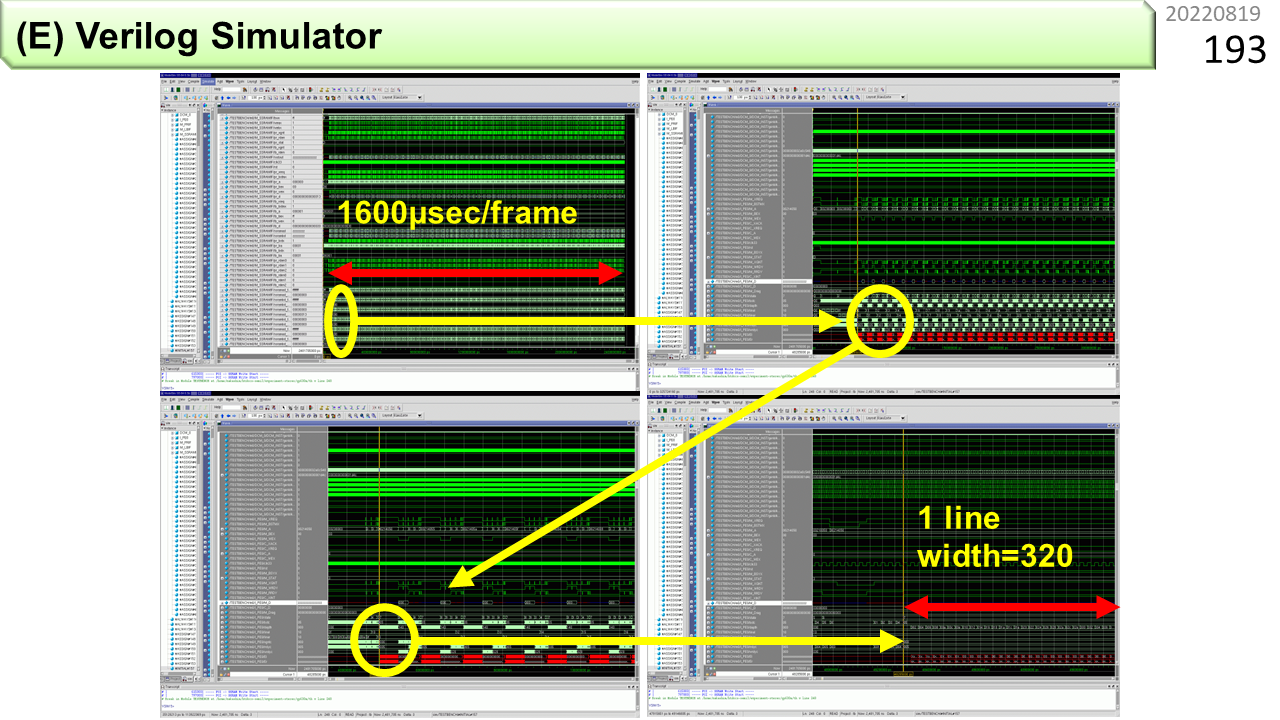
次は,Verilogシミュレーションの実例です。
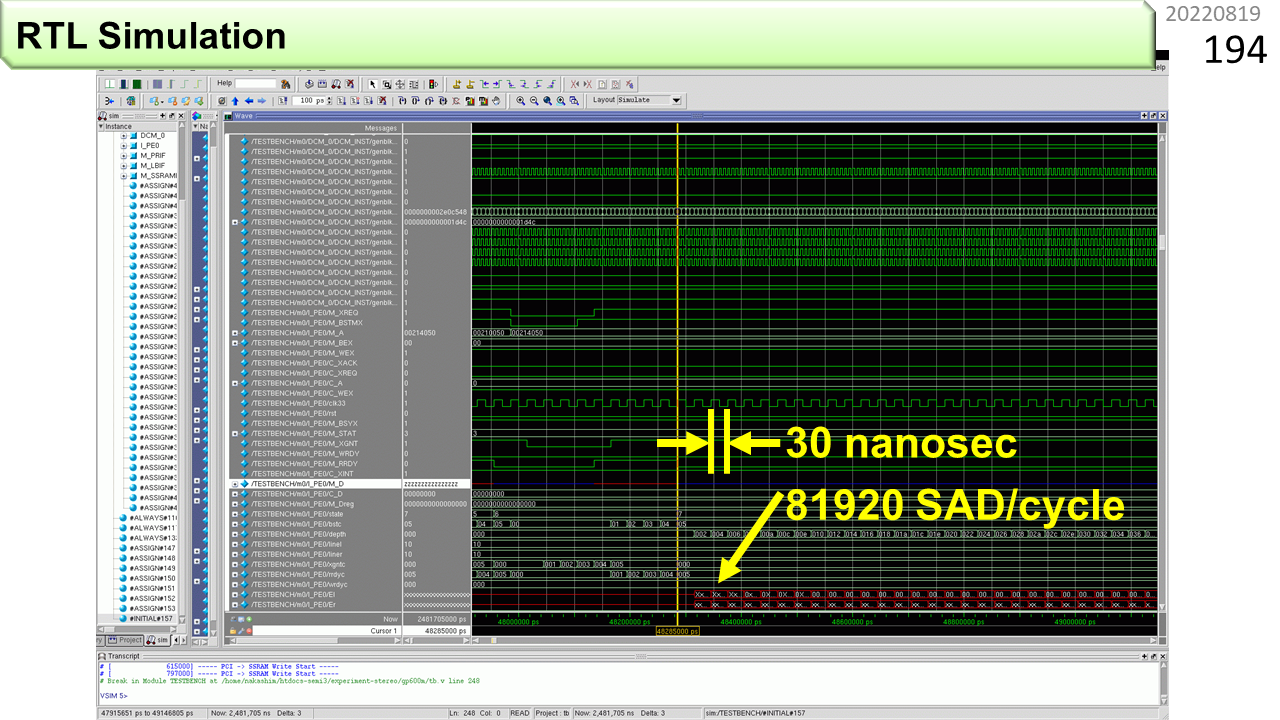
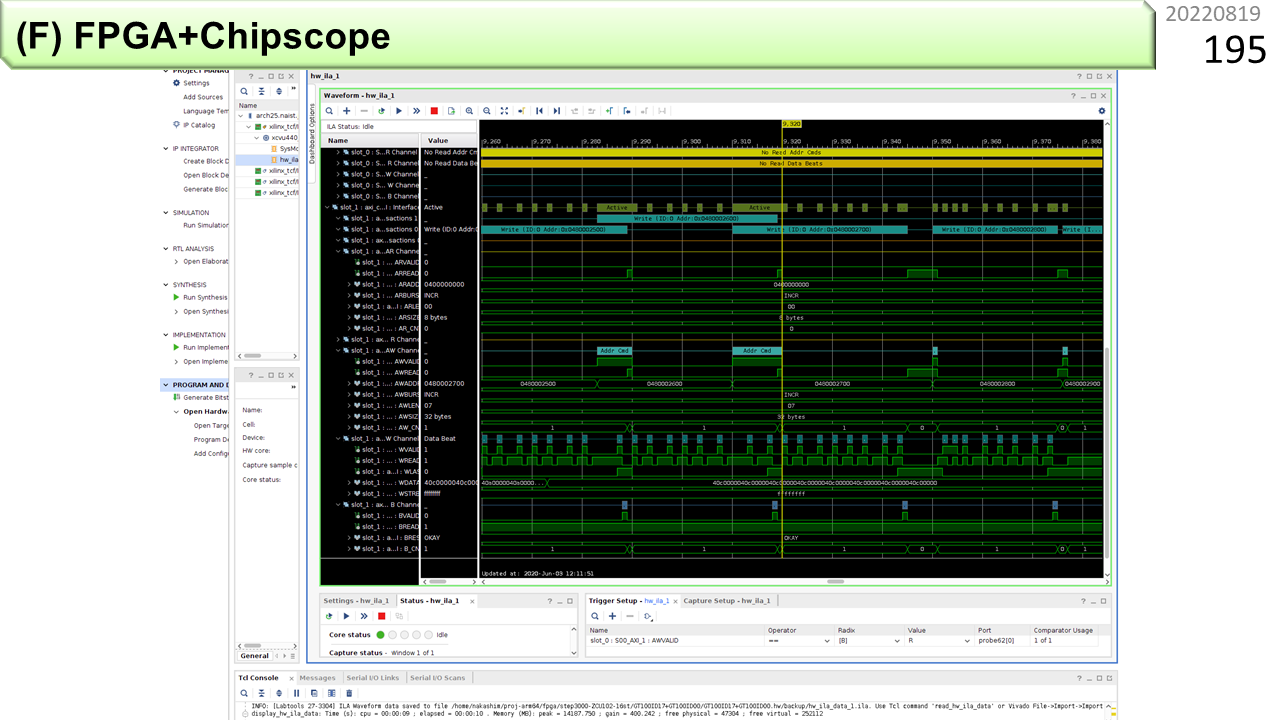
そして,実機波形の実例です。
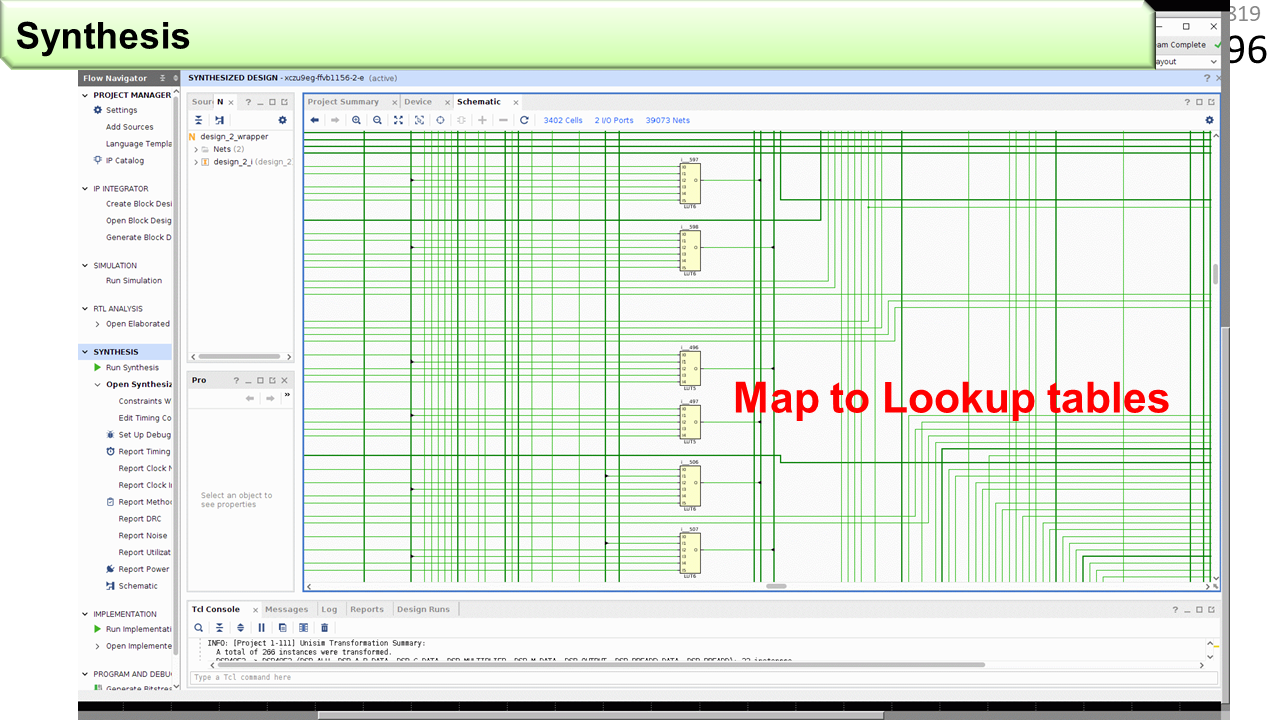
実機を使うためには,Verilog記述から,まず回路合成を行い,次に配置配線を行います。これは合成結果。
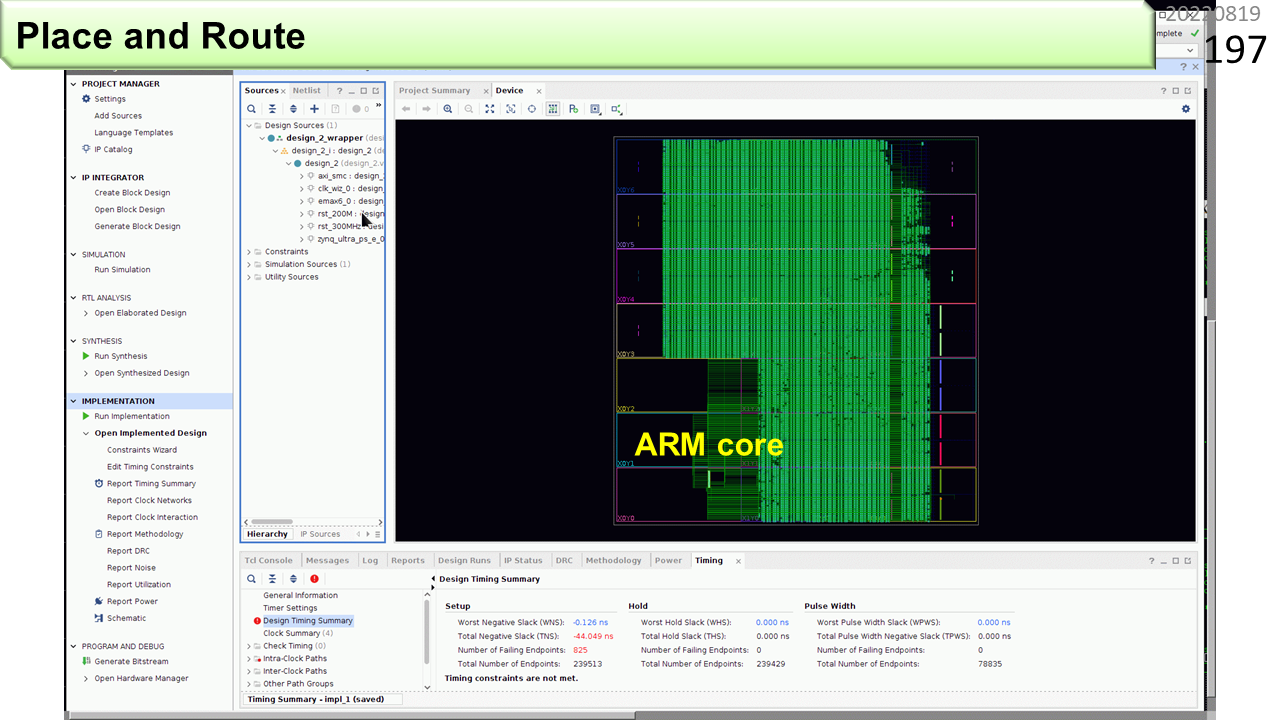
これが,IMAX2の配置配線結果です。ここで使ったFPGAは小さいので,8ユニット構成です。
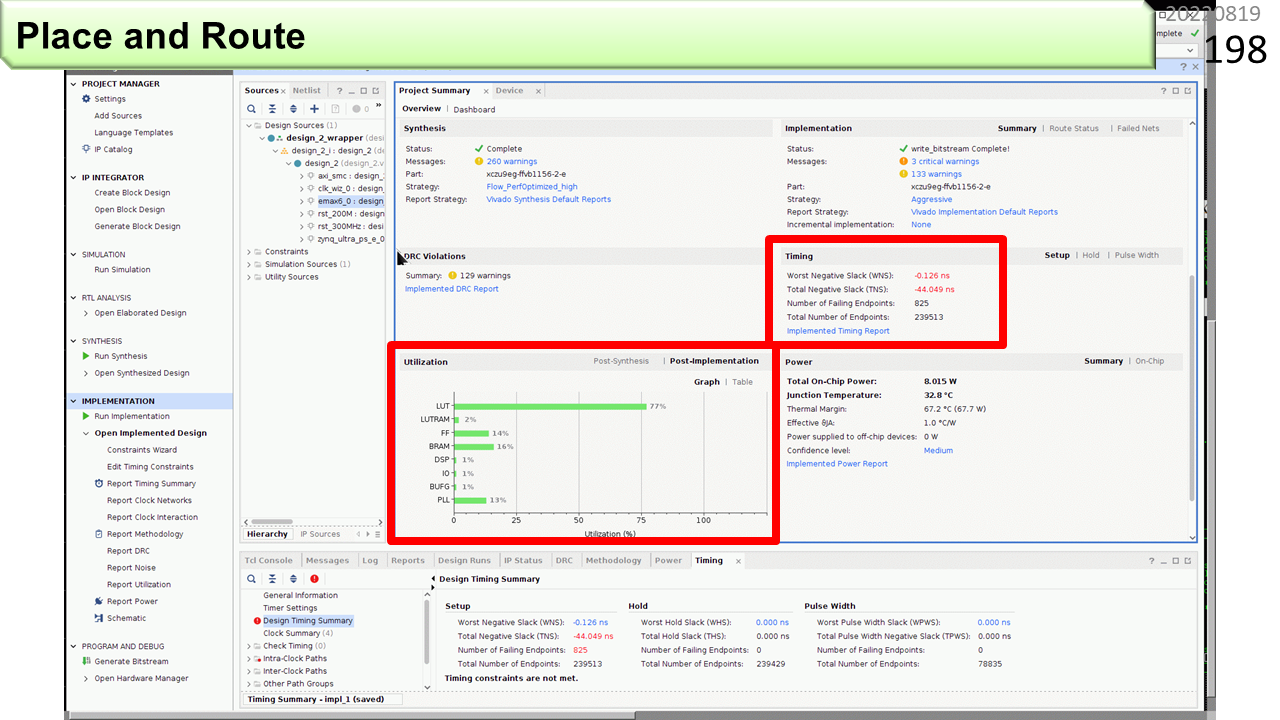
FPGAの資源のうち,LUTの77%が使われています。WNSがマイナス0.126nsと,目標動作周波数200MHzに少し届いていません。
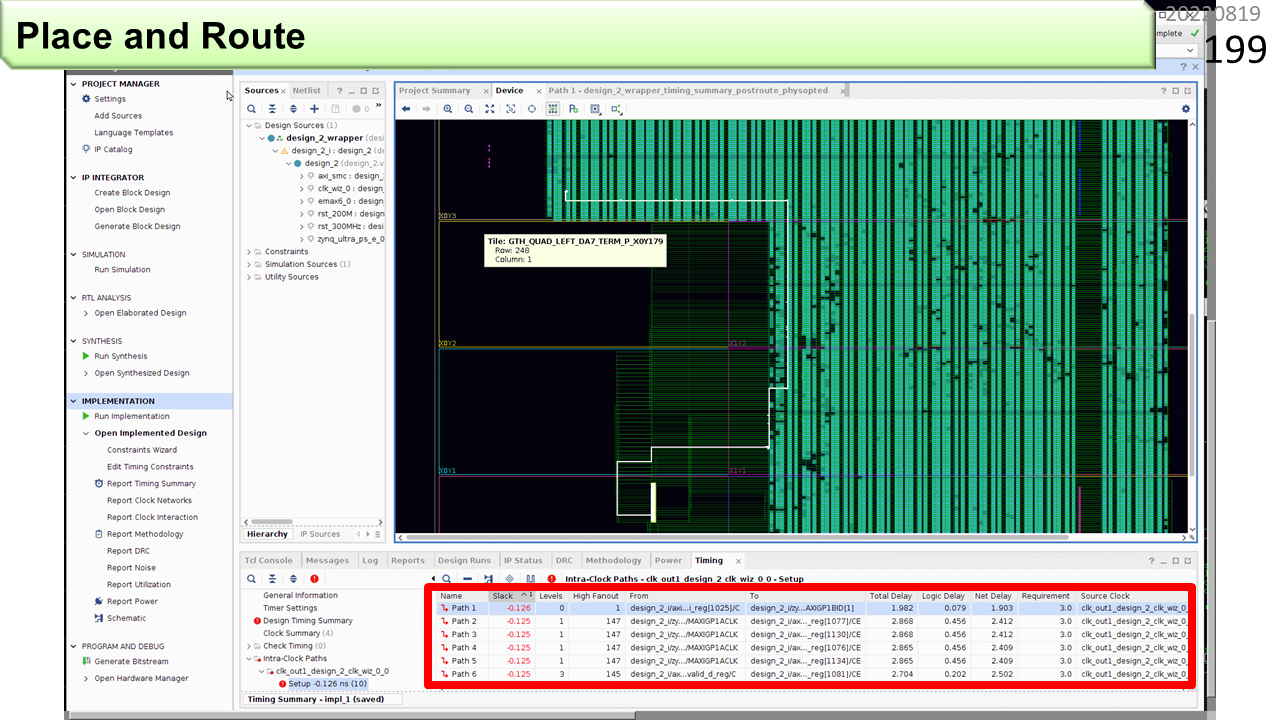
遅い配線を調べると,このような,長距離配線が見つかりました。
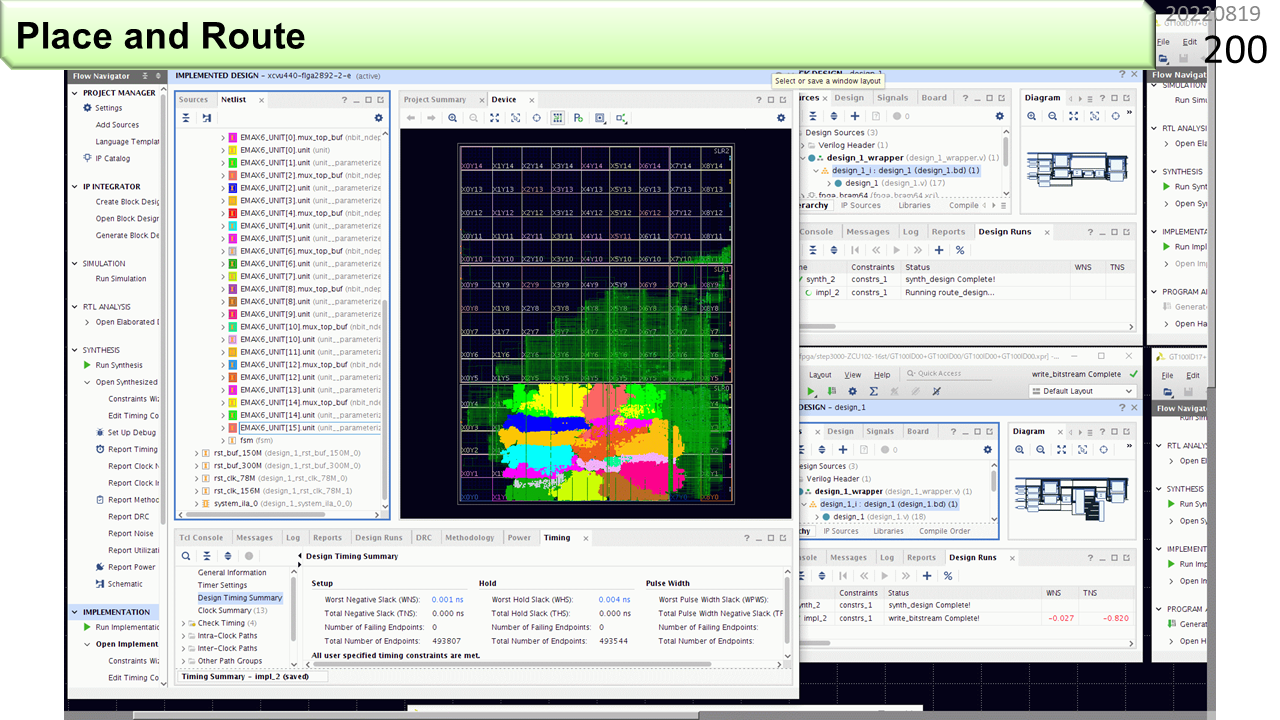
もっと大きなFPGAを使って,16ユニット構成を配置配線してみました。まだ多くの空き地がありますね。最終的には,このFPGAには,64ユニットを実装することができます。
さらにユニット数を増やすには,FPGAボートを複数枚接続します。ボード間接続には,高速シリアル通信を使います。

そして,ボード間接続のためのインタフェースボードも作ります。左端が,ARMv8が載っているFPGAボード(ZCU102),右側が,IMAX2が載っている2枚の大規模FPGAボード(VU440)です。
高速シリアル通信といっても,FPGA内部のデータ転送速度と釣り合う性能を出すのは,とても難しいです。IMAX2内部が高速動作した後は,ARMv8との間の通信時間を短縮する工夫が重要になります。
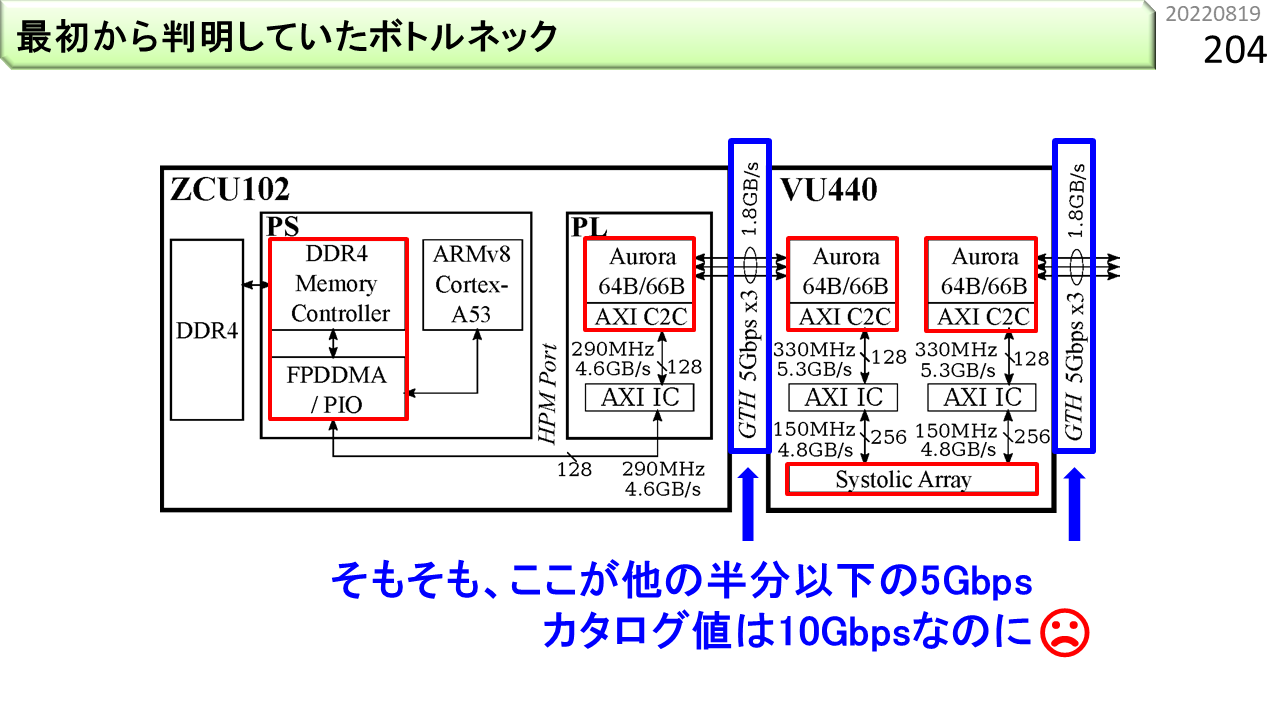
よくあるのが,カタログスペック通りに,性能が出ないことです。このFPGAのシリアル通信は,1本あたり,10Gbps出るはずですが,ボード上の制約があるのか,実際には,5Gbpsしか出ません。
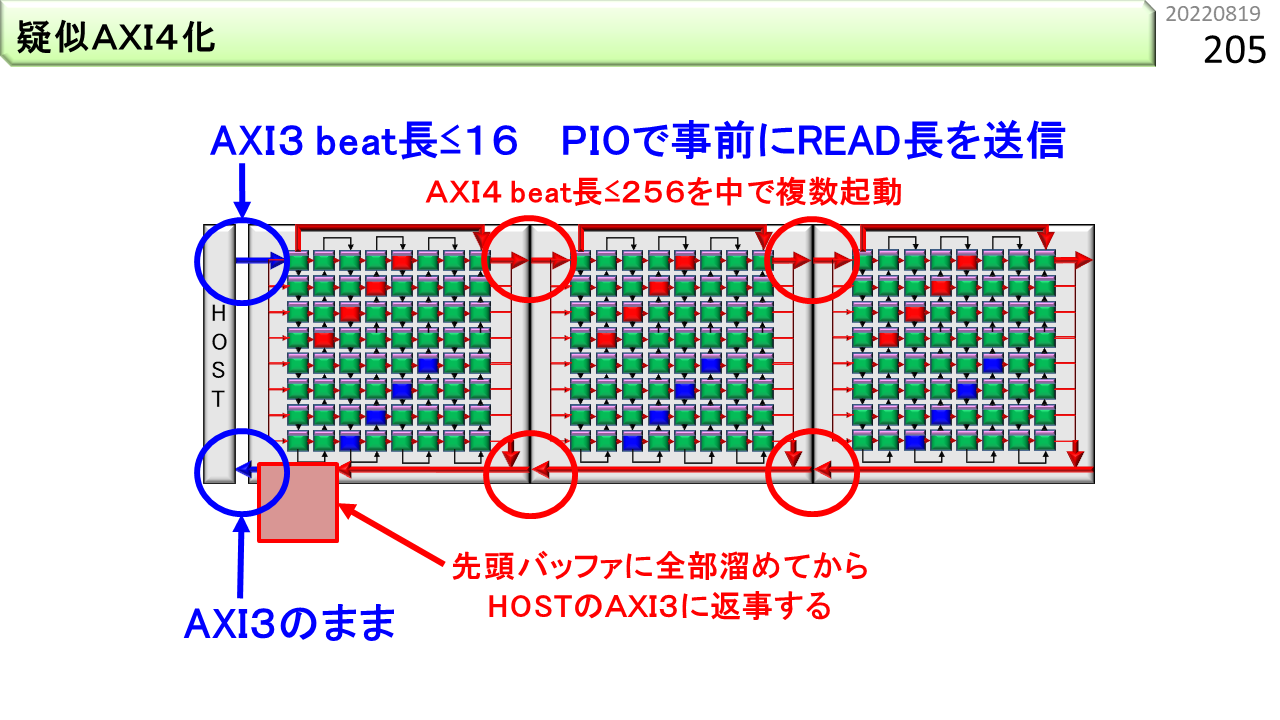
また,左端のボードに載っているARMv8のAXIインタフェースが,AXI3という,少し古い規格になっていて,バースト転送の長さが,16beatまでしかありません。いろいろ工夫して,バースト転送の長さを疑似的に256beatまで増やします。
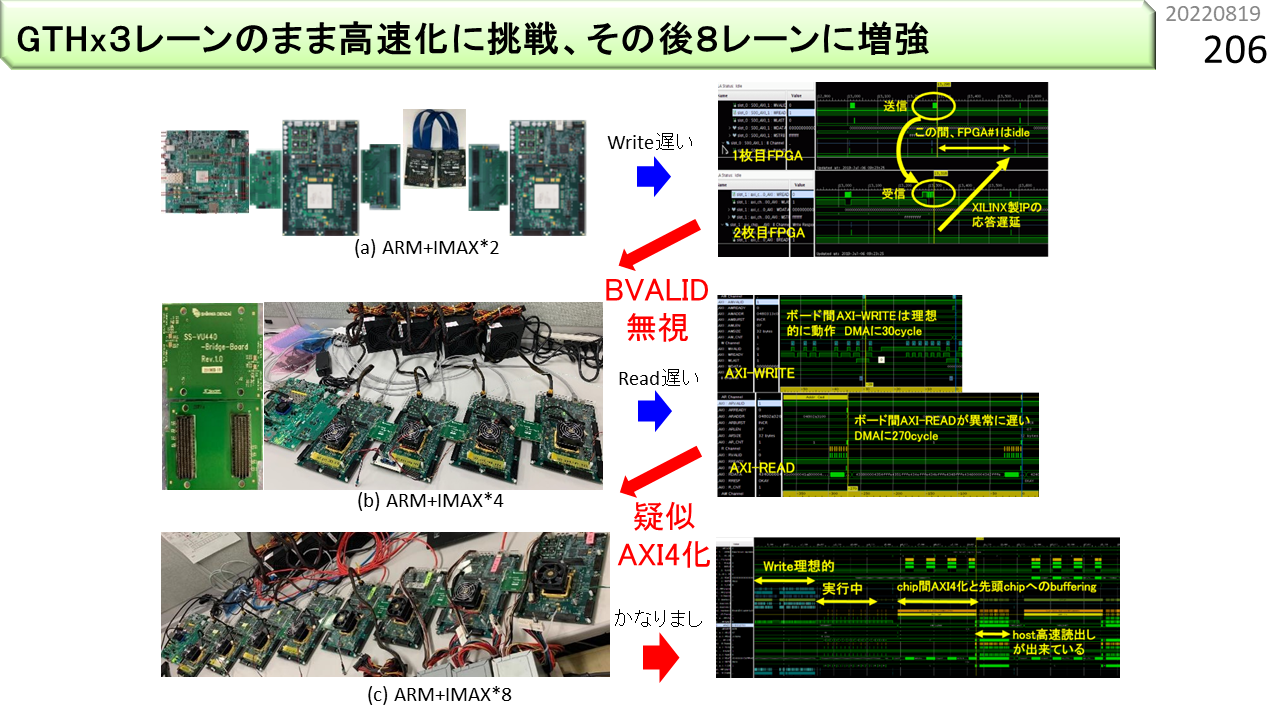
さらに,このボードは,標準仕様では,高速シリアル通信を3本までしか束ねることができません。これを8本に増やします。
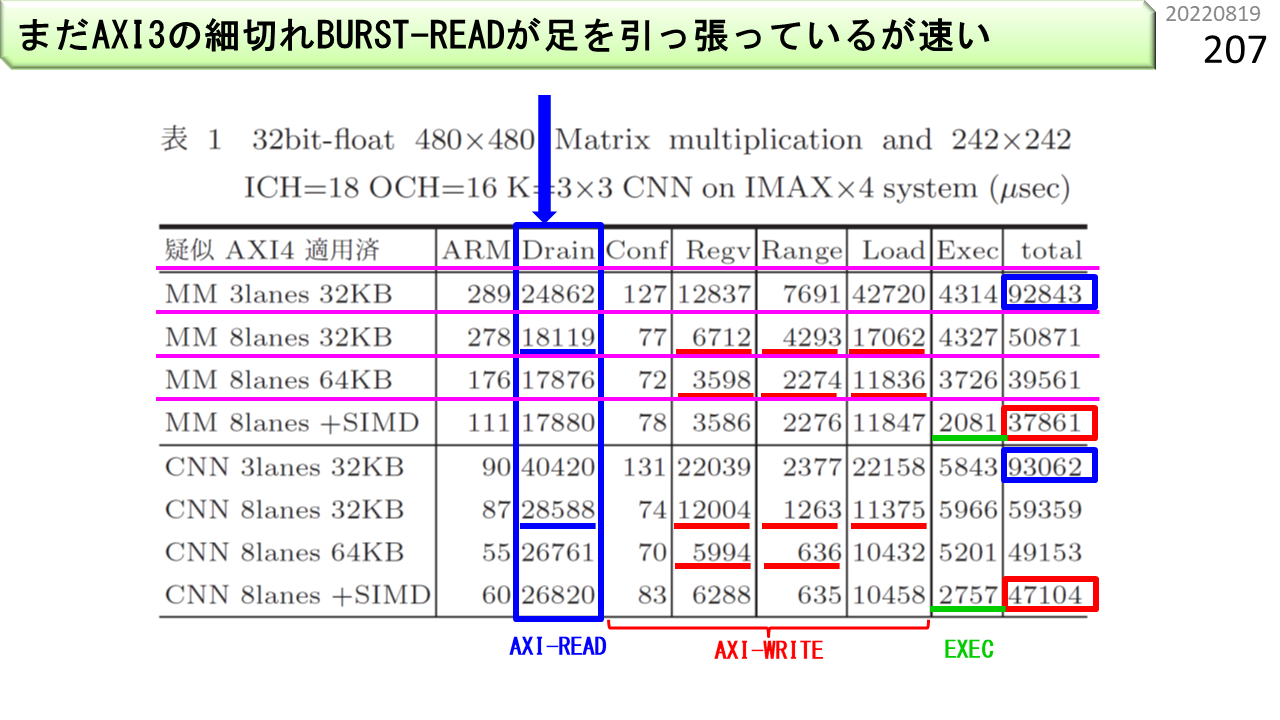
いろいろ工夫して,プログラムの実行時間を測定します。改良前の実行時間は,MM(行列積)が92843マイクロ秒,CNN(畳み込み)が93062マイクロ秒でした。改良後は,37861マイクロ秒,47104マイクロ秒に短くなりました。内訳を見ると,まだまだ,ARMv8ボードのデータ読み込み時間が,半分を占めています。AXI3がAXI4に改良されると,かなり速くなるはずです。

性能に関しては,FPGAによるプロトタイプであるが故の問題がいろいろありますが,ともかく,実機として,いろいろ試せるようになっています。これは画像処理です。

これは,画像識別と学習です。

FPGA特有の機能を使わずに,Verilogを書き,これがFPGAで動くようになれば,あとは,LSIにするだけです。OROCHIは,2006年に,こんなLSIになりました。

LAPPとEMAXも,LSIになりました。

これ,最初に見せた図です。もう一度,指さし確認。
今は,実用的LSIを作る費用が高くなり過ぎました。お金持ちの人には,作る義務,作らせる義務があります。
[2022/01/22]ああ,やっとおわるんですね?

勉強はおわりです。サンプルプログラムもツールもダウンロードできます。でも,ここからが本番です。このまま使うのもよし,参考にして全く違うものを作るのもよし,他国の同世代に頼んで,高い輸入品を使わせてもらうのもよしです。これからどうすべきか,自分で考えましょう。なお,くれぐれも,今の高校生は,ならせんたんだいに入学して,CGRAを教わろうなどど甘えてはいけません。ここは大学院だし,どこかの大学を卒業した頃には,定年過ぎて,ここにはもういませんから。そういえば,たまたまですが,今年から,高校生向けのインターンが始まるそうです。AIとかロボットとか,どこの大学でもやってますが,本格的にCGRAの実験ができるところなんてありません。高校生がIMAX2を使えるチャンスは,あと6年だけです。


IMAX2仕様書の目次はこんな感じ。
プロトタイプが各種揃っています。予算に応じてFPGAボードを買って,FPGAにIMAX2の構成ファイルをダウンロードすれば,CGRAの実機が手に入ります。ボードの値段は,上から順に,50万,150万,850万,1650万です。なお,OS調整や高速I/O実装などを含むシステム全体の開発費は15000万です。それがボードの購入費だけで手に入るのですから格安です。海外から結構な件数ダウンロードされています。現在,さらにパワーアップしたIMAX3の開発に着手しています。
関連して,ブロックチェインアクセラレータも各種揃っています。問い合わせも来ています。
研究室HPに,いろいろ置いてあります。VPP,OROCHI,LAPPや,CGRA以外のシミュレータ・プログラムが置いてあります。 終了したものも含めると,様々なプロジェクトがあります。連想メモリを使うCAMP,32ビットOSが動く超小型8ビットEMIN,CGRA型では,耐故障性を高めたEReLA,ブロックチェインに特化したBCA,アナログ計算に特化したDiaNet1とDiaNet2,確率的計算に特化したDiaNet3,超伝導素子を使うDiaNet4,シリコン以外の新材料を使うNMAXなどがあります。

おしまい。Good Luck!